

Se você deseja desbloquear todo o potencial do DeepSeek R1 0528 em domínios específicos, o fine-tuning é o método mais eficaz. Embora o modelo já seja excelente em raciocínio avançado, matemática e programação, o fine-tuning permite que ele se especialize em áreas como geração de linguagem natural, expertise em domínios específicos ou tarefas multimodais. Este artigo fornecerá um guia concreto sobre como fazer fine-tuning do DeepSeek R1 0528.
Em Que Partes o DeepSeek R1 0528 se Destaca?
Ficha Técnica do Modelo
- Tamanho do Modelo: 685B parâmetros
- Código Aberto: Sim
- Arquitetura: Mistura de Especialistas (MoE)
- Suporte a Idiomas: Multilíngue (Excelente em Inglês e Chinês)
- Capacidade Multimodal: Sim (Texto para texto)
- Treinamento: A atualização mais recente do DeepSeek R1 utiliza recursos computacionais aumentados e otimizações algorítmicas pós-treinamento. Isso melhorou significativamente sua profundidade de raciocínio e capacidades de inferência.
Desempenho do Modelo
| Benchmark | DeepSeek R1 0528 | Mais Alto Que |
|---|---|---|
| AIME 2024 | 91.4 | Todos (exceto OpenAI-o3, quase empatado) |
| AIME 2025 | 87.5 | Todos |
| GPQA Diamond | 81.0 | Qwen3-235B, DeepSeek-R1 |
| LiveCodeBench | 73.3 | Todos |
| Aider | 71.6 | Qwen3-235B, DeepSeek-R1 |
| Humanity’s Last Exam | 17.7 | Qwen3-235B, DeepSeek-R1 |
- Excelente em raciocínio matemático avançado e resolução de problemas
- Demonstra fortes habilidades de programação e geração de código
- Lida eficazmente com lógica complexa e tarefas analíticas
Como o DeepSeek R1 0528 já é forte em matemática, código e lógica, sua melhor direção de fine-tuning é mirar áreas onde ele é menos dominante, como geração de linguagem natural, expertise em domínios específicos, tarefas multimodais ou segurança e alinhamento. Isso tornará o modelo mais versátil e útil para uma gama maior de aplicações.
Quando Você Deve Escolher o Fine-Tuning?
Fine-tuning é o processo de adaptar um modelo de linguagem grande (LLM) pré-treinado para atender a um propósito ou conjunto de dados específico, melhorando sua capacidade de entregar resultados ideais para tarefas direcionadas.
| Aspecto | Engenharia de Prompt | Fine-Tuning |
|---|---|---|
| Ideia Central | Instruir um cérebro geral | Treinar um cérebro especialista |
| Custo | Baixo (principalmente tempo e tokens) | Alto (dados e computação) |
| Conhecimento | Usa o conhecimento geral do modelo | Implantar seu conhecimento especialista |
| Confiabilidade | Média; pode ser inconsistente | Alta; o comportamento é incorporado |
Veja qual dos cenários abaixo se encaixa melhor no seu projeto.
Você deve escolher Fine-Tuning se precisar de:
-
Profunda Expertise em Domínio
- Cenário: Você precisa que o modelo aprenda a base de código privada da sua empresa, documentação extensa de produtos ou artigos científicos de nicho. É um conhecimento que ele não encontra na internet pública.
-
Confiabilidade Estrutural Estrita
- Cenário: Sua aplicação exige que o modelo produza consistentemente JSON ou XML perfeitos, sem campos faltando ou texto conversacional extra.
-
Uma Personalidade Única e Enraizada
- Cenário: Você quer que o modelo adote uma voz de marca específica, o estilo de um personagem fictício ou uma estrutura de comunicação terapêutica que pareça profundamente integrada.
Você deve escolher Engenharia de Prompt se precisar de:
-
Realizar Tarefas Gerais
- Cenário: Você só precisa de ajuda para escrever e-mails, resumir artigos, traduzir textos ou fazer brainstorming de ideias.
-
Prototipar e Iterar Rapidamente
- Cenário: Você quer testar um novo recurso de IA rapidamente, sem o tempo ou recursos para criar um grande conjunto de dados de alta qualidade.
-
Lidar com Tarefas Diversas e Únicas
- Cenário: Você precisa que o modelo lide com uma grande variedade de solicitações temporárias que não seguem um padrão fixo.
O Que é Necessário para Fazer Fine-Tuning do Deepseek R1 0528?
| Descrição do Item | Preço Unitário (USD) | Quantidade | Total (USD) |
|---|---|---|---|
| GPUs NVIDIA A100 80GB | $22.217,71 | 116 | $2.577.251,96 |
| Nós de Servidor (Dual A100s) | $50.000 | 58 | $2.900.000 |
| Rede de Alta Velocidade (InfiniBand) | $100.000 | 1 | $100.000 |
| Armazenamento (NVMe SSDs, 100TB) | $20.000 | 1 | $20.000 |
| Sistema de Resfriamento Líquido | $80.000 | 1 | $80.000 |
| Fonte de Alimentação e UPS | $50.000 | 1 | $50.000 |
| Gabinete Rack | $10.000 | 1 | $10.000 |
| Licenças de Software (SO, Frameworks) | $10.000 | 1 | $10.000 |
| Manutenção e Suporte Anual | $100.000 | 1 | $100.000 |
| Eletricidade (Anual, 700W por GPU) | $0,15/kWh | 1 | $50.000 |
| Custo Total Estimado | $5.887.251,96 |
O fine-tuning de modelos de linguagem grandes (LLMs) envolve várias técnicas e estratégias, como Fine-Tuning Eficiente em Parâmetros (PEFT), otimização de parâmetros de treinamento e pré-processamento de dados. Embora esses métodos sejam eficazes, eles frequentemente exigem recursos humanos e materiais substanciais, incluindo equipes técnicas especializadas, hardware de computação poderoso e tempo amplo. Portanto, escolher um provedor de serviços em nuvem estável e econômico se torna uma solução mais eficiente.
Uma Escolha Estável e Econômica: Novita AI Cloud GPU
Quando se trata de implantações em escala de produção, encontrar o equilíbrio perfeito entre desempenho e custo é essencial. A Novita AI se destaca com preços líderes do setor, oferecendo as tarifas horárias mais acessíveis para GPUs H100 e H200 dedicadas entre os principais provedores — entregando o máximo poder de computação pelo menor custo!
| Provedor | A100 (1 cartão/H) | H100 (1 cartão/H) | H200 (1 cartão/H) |
| Novita AI | $1,6 | $2,41 | $2,99 |
| Fireworks AI | $2,9 | $5,80 | $9,99 |
| Friendli AI | $2,9 | $4,90 | $5,90 |
| Deepinfra | $1,5 | $2,40 | $3,00 |
Etapas de Implantação e Guia de Uso
Etapa 1: Registre uma conta
Crie sua conta Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e iniciar sua jornada de desenvolvimento de IA.

Etapa 2:Explore Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione a configuração de GPU desejada — as opções incluem as poderosas L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
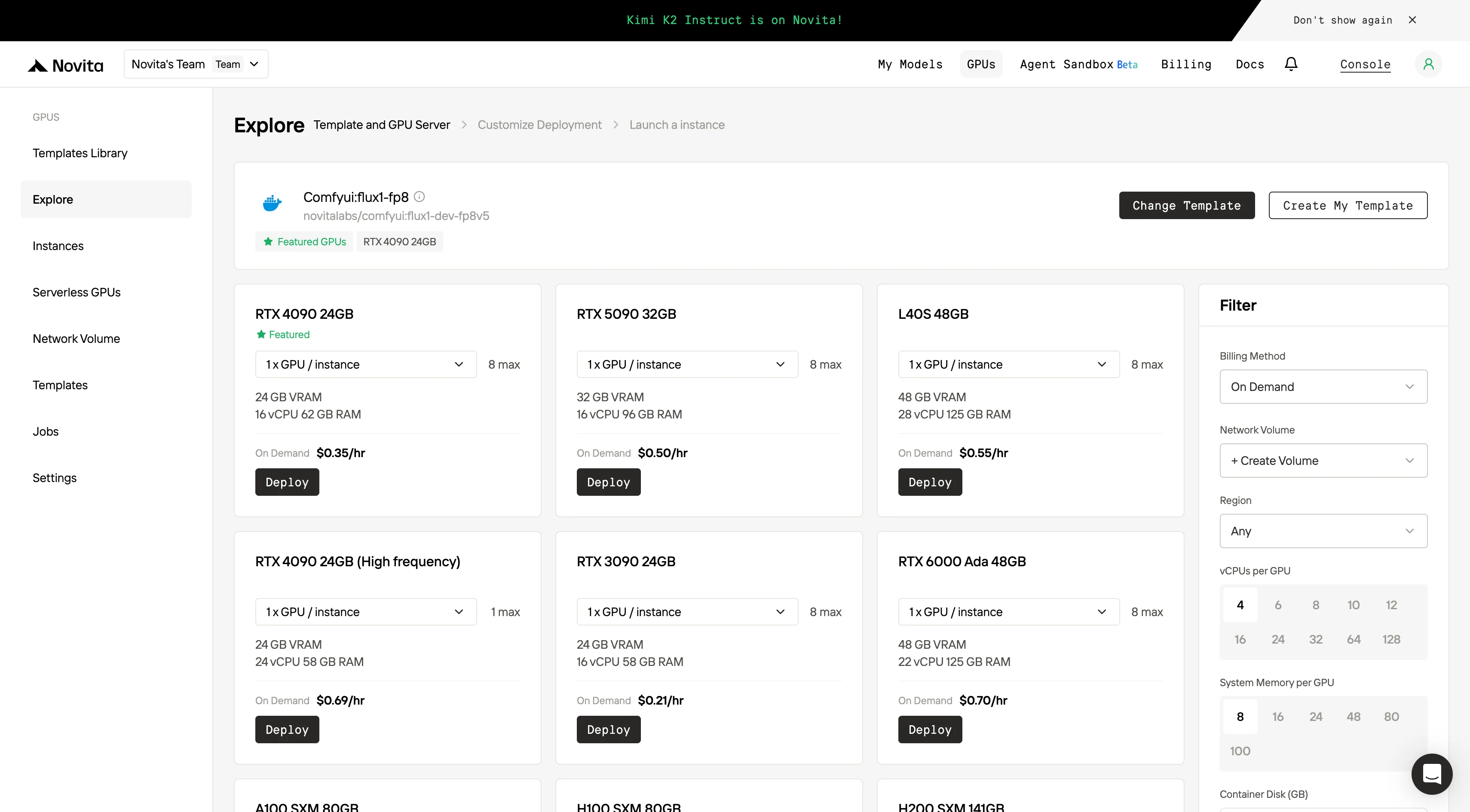
**Etapa 3:Personalize Sua Implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir desempenho ideal para suas cargas de trabalho de IA específicas e necessidades de desenvolvimento.
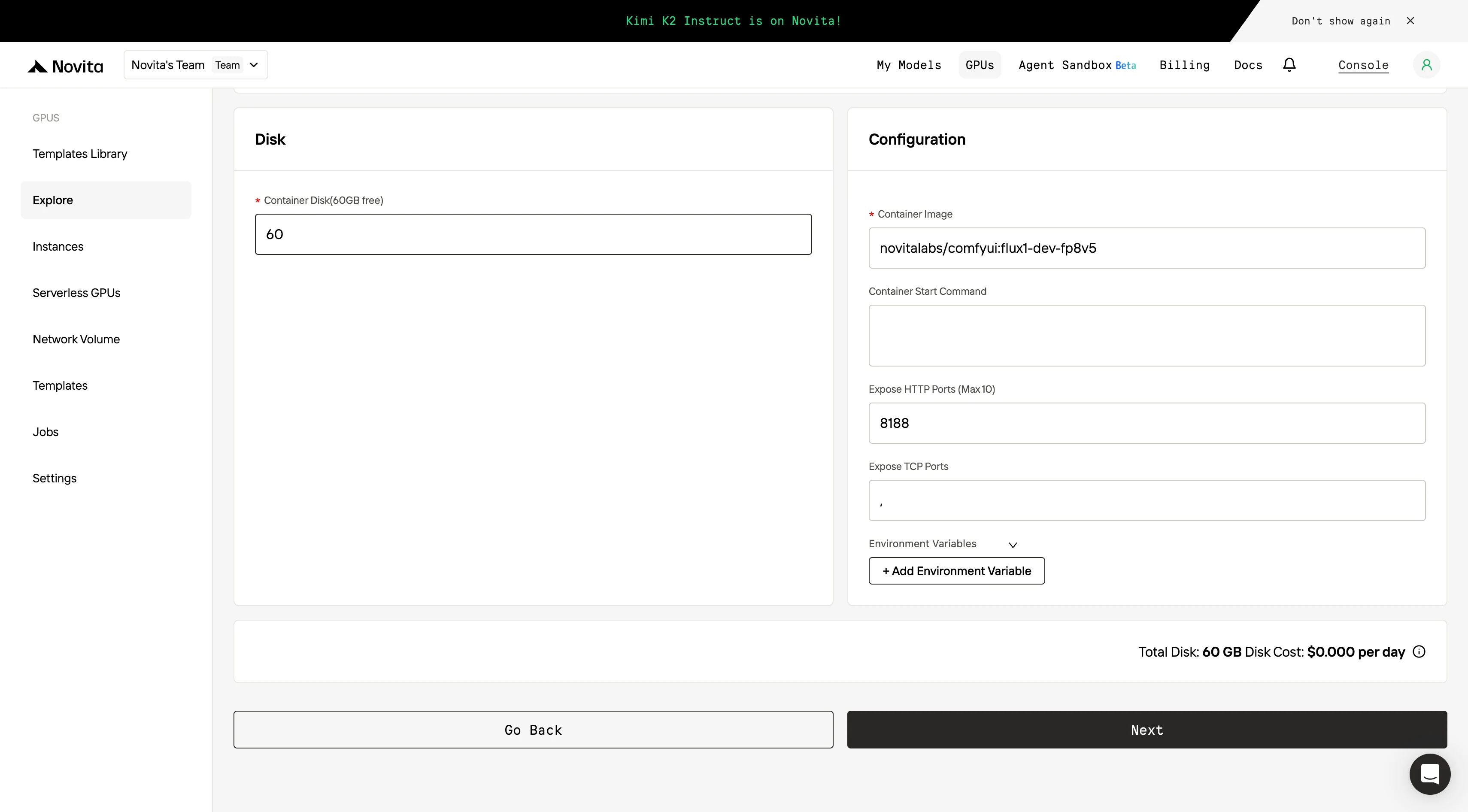
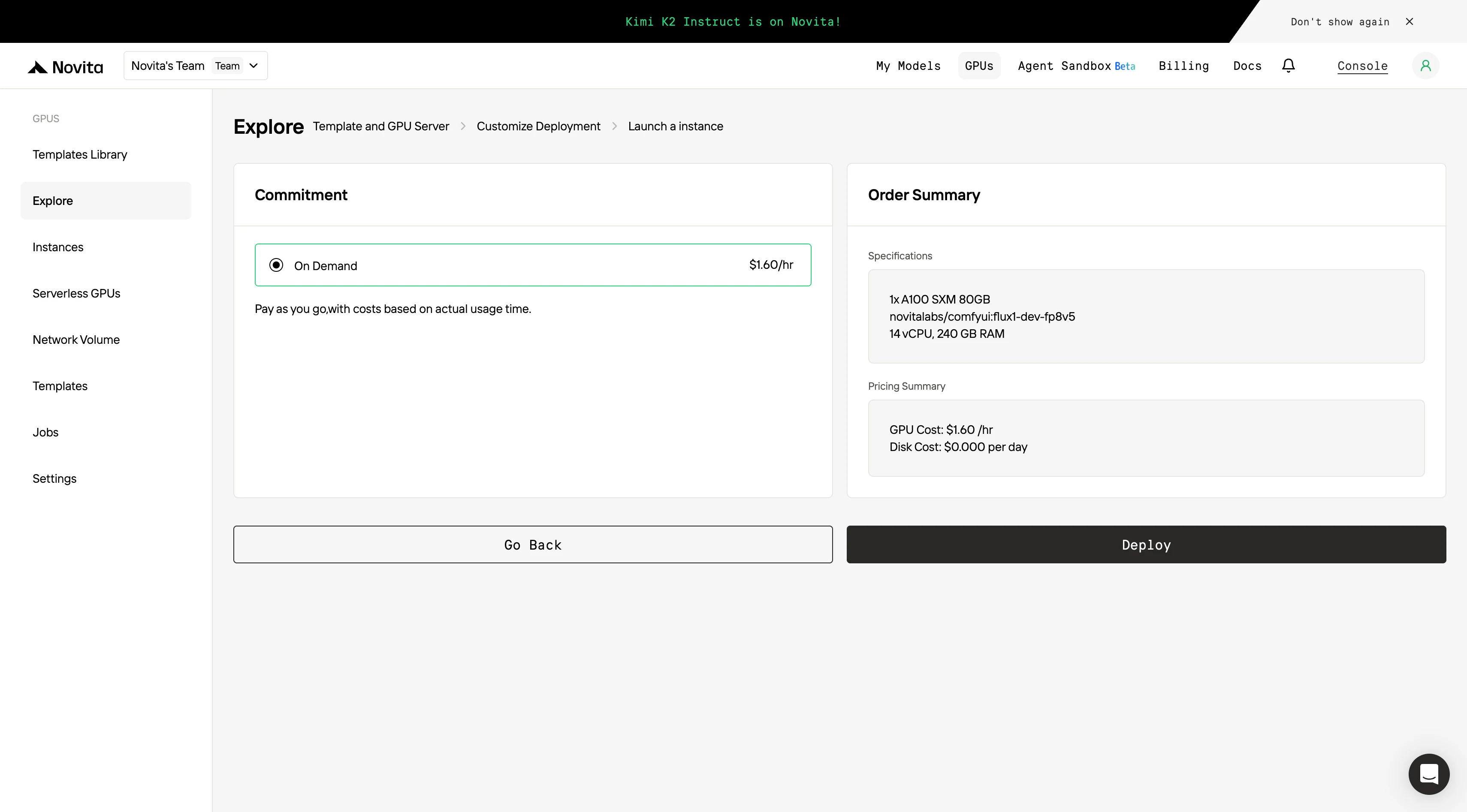
**Etapa 4:Inicie uma instância
Selecione “Iniciar Instância” para começar sua implantação. Seu ambiente de GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computação.
Para Desempenho, Segurança e Economia, Escolha um Endpoint Dedicado
Um endpoint dedicado na Novita AI oferece benefícios significativos, incluindo alto desempenho consistente com rendimento garantido, privacidade total dos dados através de recursos isolados e a capacidade de implantar modelos Hugging Face personalizados ou com fine-tuning. Ele também oferece escalabilidade flexível de até 8 GPUs (ou mais para usuários empresariais), preços transparentes e previsíveis para cargas de trabalho sustentadas e um SLA de 99,5% para confiabilidade em nível de produção.
Etapas de Implantação e Guia de Uso
1. Acesse o Console
- Faça login no seu Novita AI Console.
- Na barra lateral esquerda, clique em LLM Dedicated Endpoints.
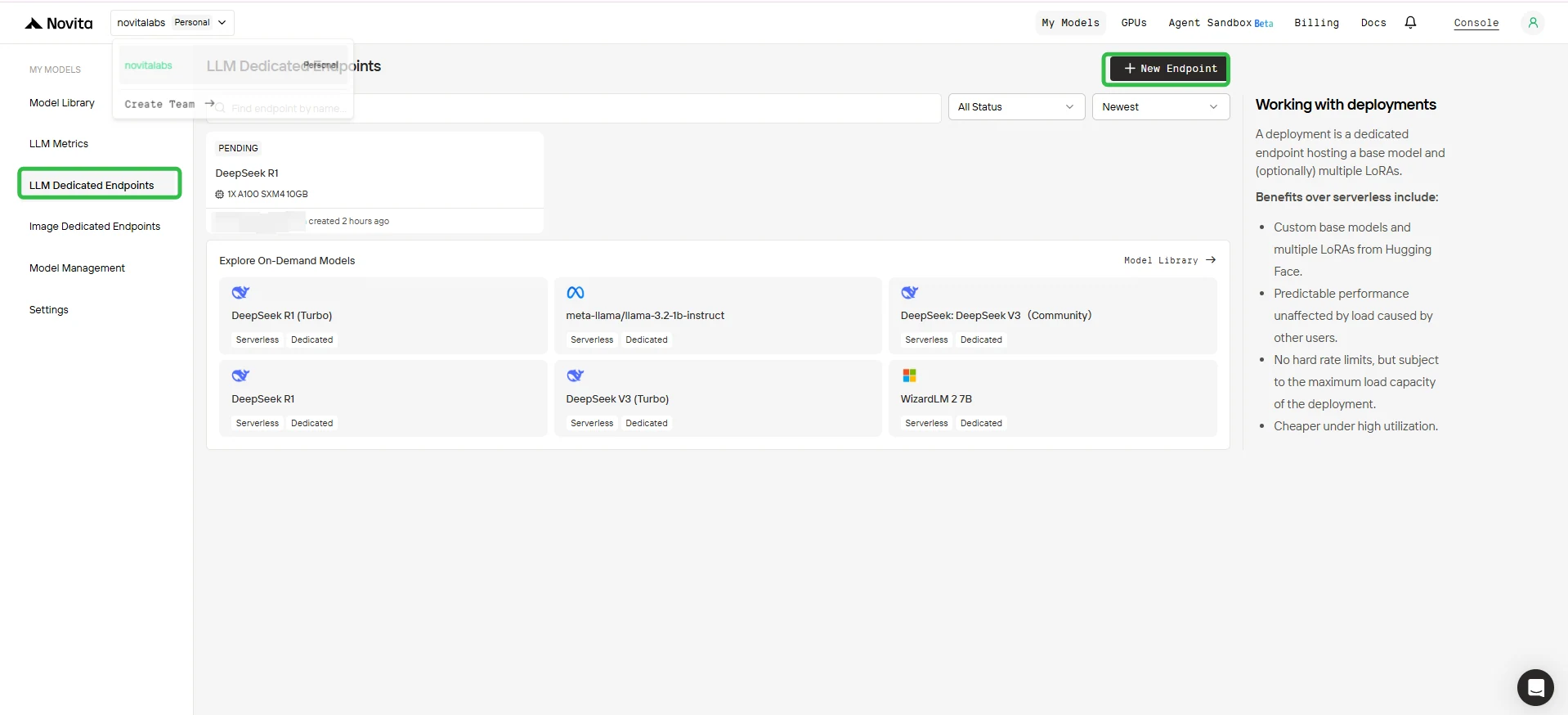
2. Crie um Novo Endpoint
- Clique no botão + New Endpoint no canto superior direito.
3. Configure Seu Endpoint
Preencha o formulário de configuração com as seguintes opções:
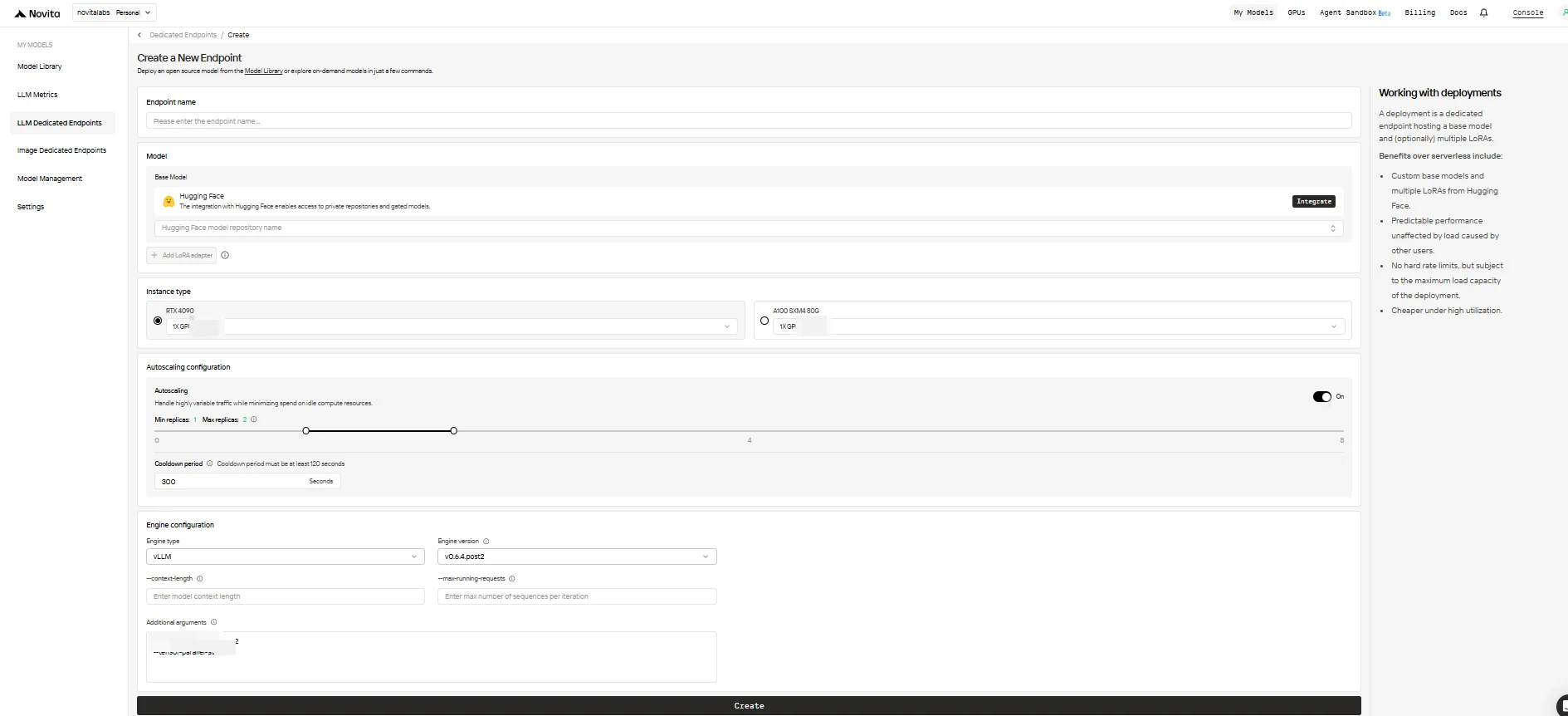
-
Endpoint Name: Dê ao seu deployment um nome único e descritivo.
-
Base Model: Insira o nome do repositório Hugging Face do seu modelo base (apenas modelos Hugging Face são suportados, incluindo públicos, privados ou com acesso restrito).
-
LoRA Adapters (opcional): Adicione um ou mais IDs de modelo Hugging Face para anexar adaptadores LoRA ao seu modelo base.
-
Instance Type: Selecione o hardware de GPU (ex.: H100, H200, RTX4090). Cada usuário pode usar até 8 GPUs em todos os endpoints.
-
Autoscaling Configuration:
- Minimum Replicas: Defina como
0para permitir que o endpoint entre em repouso quando ocioso (economia de custos), ou um valor maior para manter sempre um número mínimo de réplicas ativas. - Maximum Replicas: Defina o número máximo de réplicas para escalar (até 10).
- Cooldown Period: Defina o atraso (em segundos) antes de reduzir as réplicas para evitar redução prematura durante quedas breves de tráfego.
- Minimum Replicas: Defina como
-
Engine Configuration:
- Engine Type: Escolha o motor de inferência (
vLLMouSGLang). - Engine Version: Use o padrão (mais recente) ou especifique uma versão.
- Context Length: Opcionalmente, defina o comprimento máximo do contexto de tokens; se omitido, será derivado da configuração do modelo.
- Max Running Requests: Defina o número máximo de sequências processadas por iteração.
- Additional Arguments: Adicione quaisquer parâmetros extras do motor para personalização avançada.
- Engine Type: Escolha o motor de inferência (
Quando terminar, clique em Create para implantar seu endpoint.
4. Status de Implantação do Endpoint
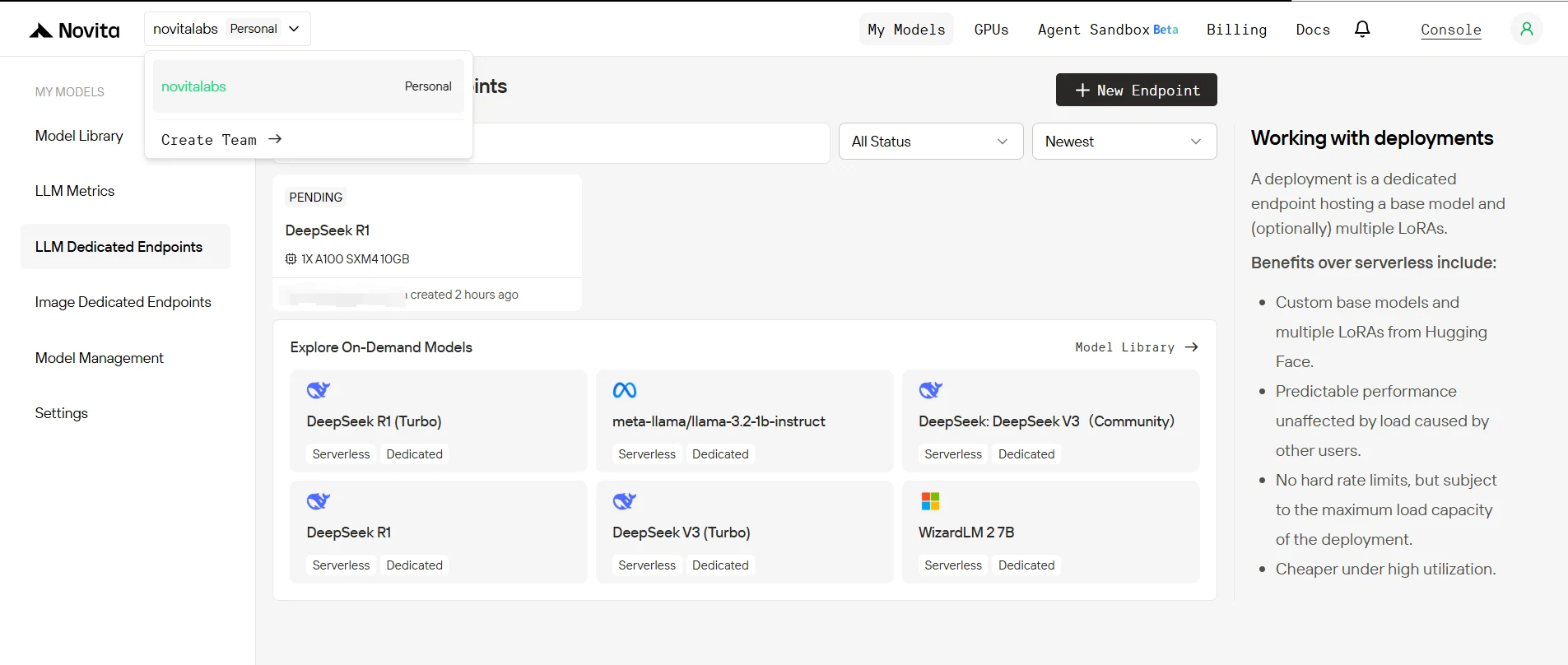
Após a criação, seu endpoint passará por vários status:
- Sleeping: O endpoint está ocioso, sem consumir recursos de computação (se as réplicas mínimas estiverem definidas como 0).
- Pending: A implantação está sendo inicializada.
- Rolling: O modelo e a infraestrutura estão sendo configurados.
- Running: O endpoint está ativo e pronto para atender solicitações.
Você pode monitorar esse status na página de Endpoints no console.
5. Teste Seu Endpoint no Playground
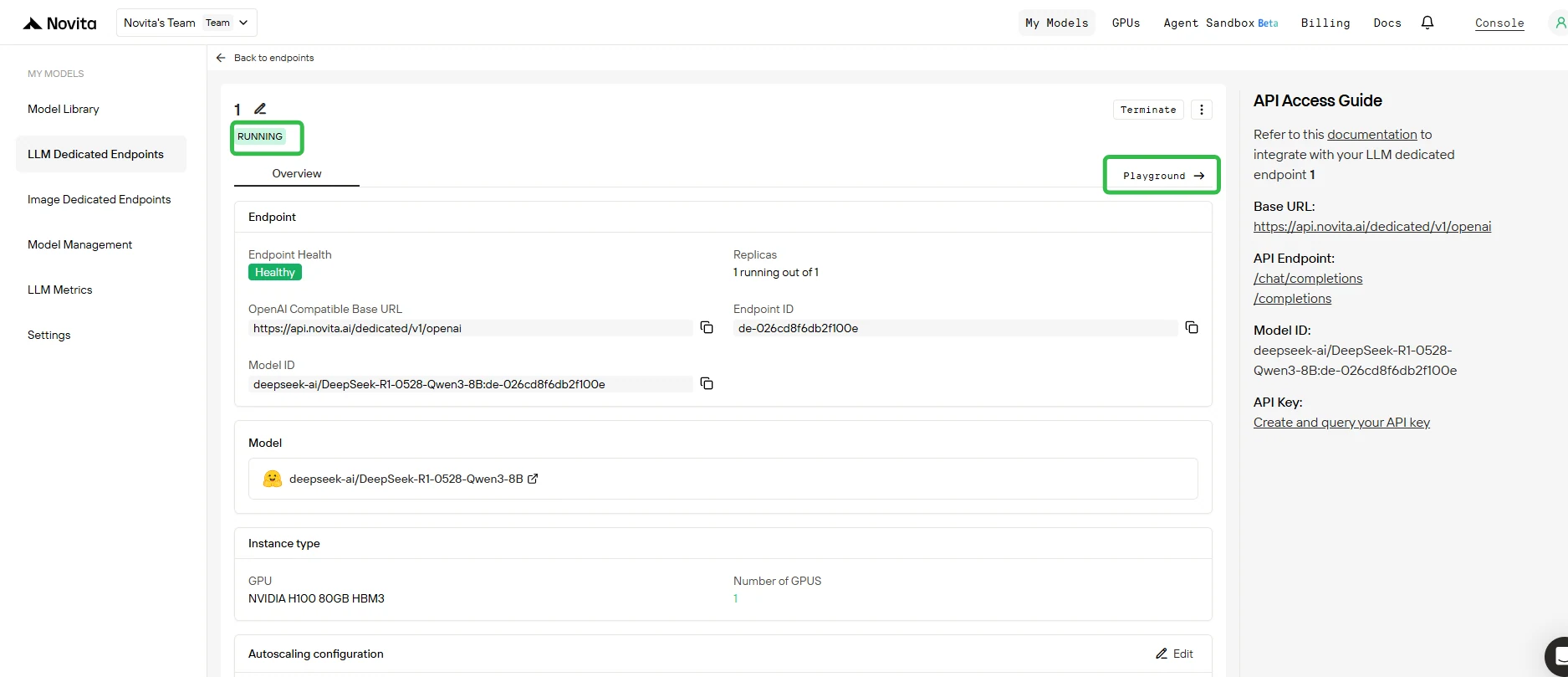
- Assim que a implantação estiver concluída e o status for Running, clique no seu endpoint e abra a aba Playground.
- No Playground, você pode:
- Enviar prompts de teste para seu modelo base e quaisquer adaptadores LoRA anexados.
- Comparar instantaneamente a saída de diferentes adaptadores versus o modelo base.
Experimente o Dedicated Endpoint agora
6. Próximos Passos
- Multi-LoRA Endpoints: Implante vários adaptadores LoRA em um único endpoint para alternância flexível de modelos.
- Integração com API: Use os endpoints de API fornecidos para enviar solicitações e integrar seu modelo em suas próprias aplicações.
- Otimize e Escalone: Ajuste o autoscaling, a configuração do motor e a cota de GPU conforme suas necessidades crescerem.
- Precisa de Mais Recursos? Entre em contato com nossa equipe de vendas para uma solução empresarial se você precisar de mais de 8 GPUs ou de recursos de nível empresarial.
Exemplos de Código (Para usuários Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/dedicated/v1/openai",
api_key="<Your API Key>",
)
model = "deepseek-ai/DeepSeek-R1-0528-"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "you are a professional AI helper.",
},
{
"role": "user",
"content": "Where can the example of GPU provided by novita ai be adapted?",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fazer fine-tuning do DeepSeek R1 0528 permite que você aproveite todo o seu potencial para tarefas específicas de domínio, permitindo que ele entregue saídas precisas, confiáveis e personalizadas. Ao aproveitar técnicas eficientes como adaptadores LoRA e implantar em plataformas econômicas como a Novita AI, você pode reduzir despesas enquanto alcança alto desempenho. Seja para expertise profunda, confiabilidade estrita ou uma personalidade única, o fine-tuning garante que o modelo atenda aos seus requisitos específicos.
Perguntas Frequentes
Qual é o custo do fine-tuning do DeepSeek R1 0528?
O custo estimado para construir sua própria infraestrutura é de cerca de US$ 5,89 milhões. No entanto, usar as GPUs em nuvem da Novita AI reduz significativamente os custos iniciais, com GPUs H100 a partir de US$ 2,41/hora.
Como posso garantir que o modelo com fine-tuning atenda às minhas necessidades?
Prepare um conjunto de dados limpo e relevante e use adaptadores LoRA ou métodos PEFT para ajustar eficientemente camadas específicas do modelo. Isso garante alto desempenho sem overfitting.
Posso implantar meu modelo com fine-tuning na Novita AI?
Sim, a Novita AI suporta a implantação de modelos com fine-tuning como endpoints dedicados, com opções de autoscaling, configurações multi-LoRA e integração com API para uso contínuo em suas aplicações.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a GPU em nuvem acessível e confiável para construir e escalar.



