

Novita AI not only launched four models of Speech 02, but also introduced a voice cloning feature. The underlying processing modes for this feature are Speech 02 HD and Speech 02 Turbo. You can specify the desired mode by editing the “model” parameter when sending API call instructions.
Try MiniMax Voice Cloning Now!
What is Minimax Voice Cloning?
Novita AI’s voice cloning feature is powered directly by the Speech 02 family of models-Speech 02 hd and Speech 02 Turbo. Both Speech 02 sub-models support advanced voice cloning (voice-clone) by processing only a few seconds (typically ≥ 5–10 seconds) of reference audio to generate a highly similar synthetic voice.
Minimax Speech 02 is a powerful text-to-speech (TTS) solution offering high-quality, natural-sounding audio synthesis.
Key Features
- Extensive Voice Library: Choose from over 300 authentic voices in multiple languages.
- Advanced Voice Controls: Easily adjust emotion, volume, speaking rate, and output formats.
- Innovative Voice Mixing: Blend existing voices to create unique vocal profiles.
- Multiple Audio Formats: Output in FLAC, WAV, MP3, PCM, and more.
- Real-Time Streaming: Instant audio delivery for seamless integration.
- High Concurrency Support: Reliable performance, even under heavy workloads.
Speech 02 Model Comparsion
speech‑02‑hd
-
Suitable Scenarios: Short text, real-time dialogue, audiobooks, and long-form content.
-
Advantages: Delivers extremely high audio quality and naturalness, making it ideal for applications where voice realism is crucial.
-
Supported Text Length:
- Text to Speech: Up to ~5,000 characters.
- Async Long TTS: Supports processing of long texts (hundreds of thousands or even millions of characters) in a queued, asynchronous manner, while maintaining top audio quality.
speech‑02‑turbo
-
Suitable Scenarios: Real-time voice interaction, long text in interactive scenarios.
-
Advantages: Focuses on fast response and low latency, making it perfect for instant conversations and interactive applications. Also balances speed and scalability for processing longer texts.
-
Supported Text Length:
- Text to Speech: Up to ~5,000 characters.
- Async Long TTS: Can handle long texts efficiently, with faster processing than synchronous mode.
How does MiniMax Improve Voice Cloning Speed?
Using MiniMax Advantages
1. Ultra-Realistic Voice Cloning
- Up to 99% Similarity:
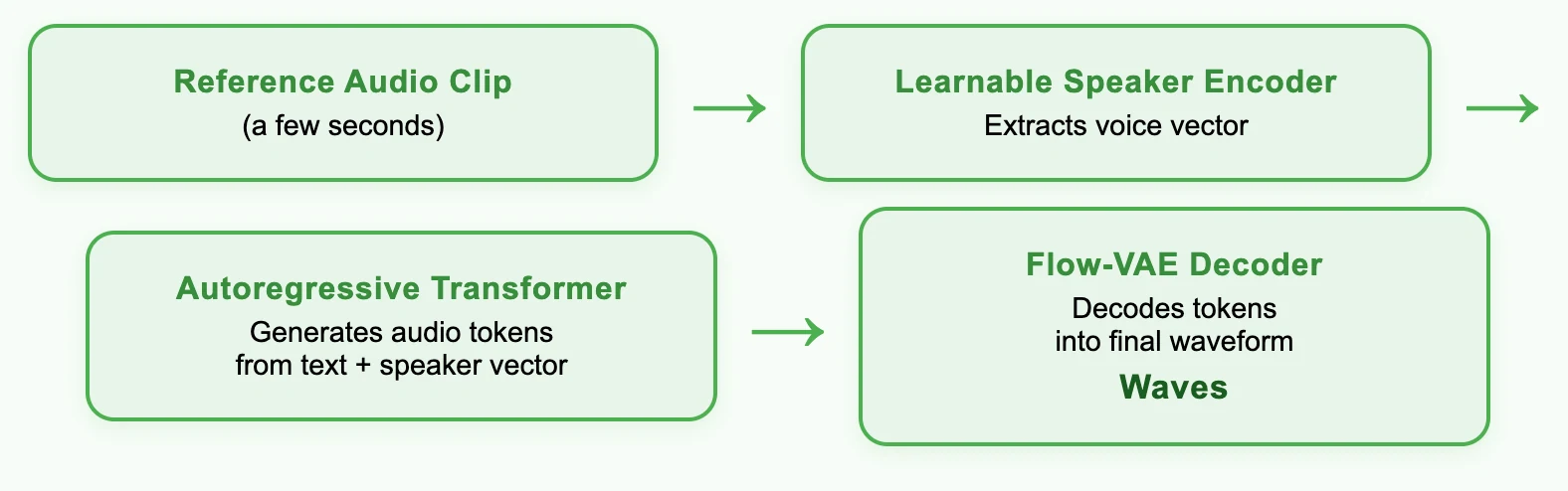
The Speech‑02 HD model achieves up to 99% vocal similarity, delivering exceptionally high fidelity in tone, cadence, and accent—even with as little as 10 seconds of clean reference audio. - Advanced Architecture:
Built on the state-of-the-art MiniMax-Speech zero-shot TTS framework, which includes a learnable speaker encoder and Flow-VAE for superior voice modeling. - Multilingual Zero-Shot & One-Shot Cloning:
Enables one-shot or zero-shot voice cloning across 32 languages, allowing users to capture unique vocal timbres without needing transcribed reference audio.
2. Multilingual & Emotion Support
Speech-02 supports synthesis in over 30 languages, including various regional accents. Users can also control emotion and tone, further enhancing the naturalness and expressiveness of generated speech.
3. Flexible Text-to-Speech Tools
Speech-02 offers powerful tools for diverse needs, such as:
Document/URL-based reading (“Read Anything”)
These features are especially useful for creating audiobooks or other long-form audio content.
Long Text Mode (supports up to 200,000 characters)
MiniMax vs Other Voice Cloning Algorithms
MiniMax Speech 02 has earned top honors on Artificial Analysis Speech Arena
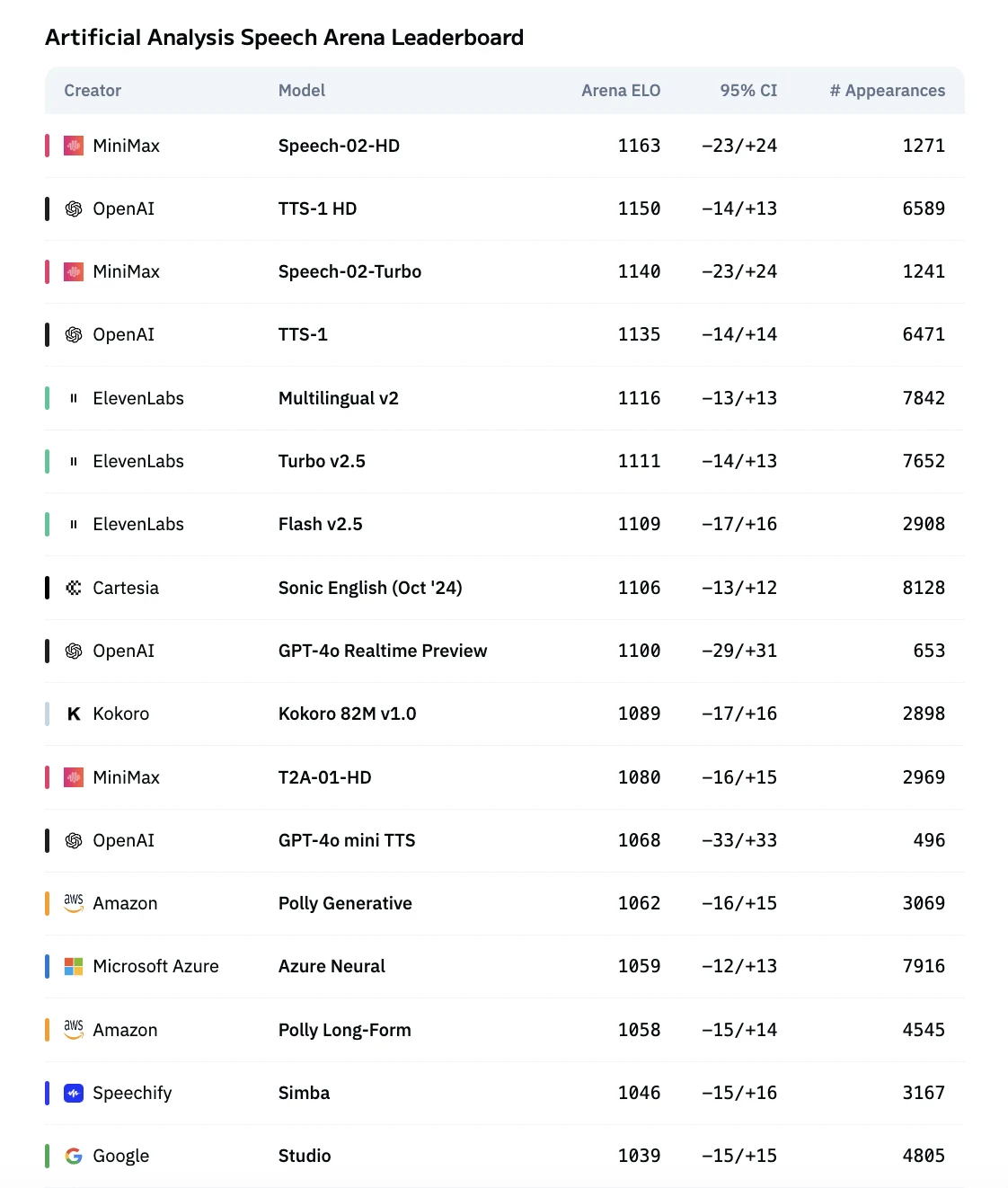
From Artificial Analysis Arena
| Model | Strengths | Best For | Recommended Regions/Countries |
|---|---|---|---|
| Minimax | Fast inference, lightweight deployment, high efficiency | Real-time apps, chatbots, scalable services | China (excellent Mandarin, real-time support); Southeast Asia (Singapore, Malaysia, Vietnam: low latency, Mandarin/English); India (efficient for Hindi, Tamil, etc.) |
| ElevenLabs | Emotionally rich, expressive, great for storytelling and long-form | Podcasts, audiobooks, video narration, marketing | US/Canada (native English, various accents); UK (diverse British English); Australia/New Zealand (natural Australian English); Germany, France, Spain (major European languages); Japan, Korea (engaging voices, selected availability) |
| Cartesia | Multilingual fluency, clear pronunciation, global content-ready | E-learning, translation tools, global voice apps | Europe (strong support for German, French, Spanish, Italian, etc.); Latin America (neutral Spanish for cross-region content); Middle East & Africa (Arabic, local languages); Global EdTech (clear enunciation for language teaching) |
Applications of MiniMax Quick Voice Cloning in Gaming
- Player-AI Dialogue Voices
Enable NPCs or assistants to speak in personalized voices—players record a clip, and AI clones it for in-game dialogue or companion character voices. - Custom Character Voice Packs
Stream DCs or TTRPG players can create custom speaking characters using their own or cast-provided voice clips for richer roleplay. - Dynamic Voice Effects
Switch between voices (e.g., underwater filter, twisted baddie, robotic tone) but keep the same underlying cloned voice traits for immersion. - Localization Without Losing Voice Identity
Narrators or characters can speak multiple languages using the same cloned voice, maintaining personality across translations. - Immersive Marketing & Trailers
Voice clips for game trailers or promo materials using brand-accented voice clones to maintain identity across media.
How to Use MiniMax for Quick Voice Cloning in Novita AI?
Novita AI provides a simple yet powerful API to enable quick cloning.Below is a step-by-step guide on how to ude MInimax Speech 02 API for voice cloning.
Step 1: Upload An Audio File
- The uploaded audio file must be in mp3, m4a, or wav format.
- The duration of the uploaded audio must be at least 10 seconds and no more than 5 minutes.
- The uploaded audio file size must not exceed 20 MB.
Step 2: Set Parameters
Header
| Header | Type | Required | Meaning / Description |
|---|---|---|---|
| Content-Type | string | Yes | Specifies the media type of the request body. Use application/json. |
| Authorization | string | Yes | Bearer token for API authentication. Format: Bearer {API Key}. Example: Bearer sk-xxxxxx |
Body
| Parameter | Type | Meaning / Description |
|---|---|---|
audio_url | string | The URL of the audio file to be cloned. Supported formats: mp3, m4a, wav. |
clone_prompt | object | Voice cloning parameters to improve similarity/stability. Requires a short sample audio (<8s) and transcript. |
text_validation | string | Up to 200 characters. If provided, the service checks if the audio and text match; error 1043 if not. |
text | string | Text (up to 2000 characters) to synthesize for preview. The result is returned as an audio URL. |
model | string | Specifies the speech model for preview. Options: speech-02-hd, speech-02-turbo. |
accuracy | float | Value between 0 and 1. Sets the accuracy threshold for text validation. Default: 0.7. |
need_noise_reduction | bool | Enables noise reduction. Default: false. |
need_volume_normalization | bool | Enables volume normalization. Default: false. |
Step 3: Get API Key

Step 4: A Python Example
import requests
url = "https://api.novita.ai/v3/minimax-voice-cloning"
payload = {
"audio_url": "<string>",
"text_validation": "<string>",
"text": "<string>",
"model": "<string>",
"accuracy": 123,
"need_noise_reduction": True,
"need_volume_normalization": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())Response
{
"demo_audio_url": "<string>",
"voice_id": "<string>"
}Novita AI’s new MiniMax Voice Cloning, powered by the Speech 02 HD and Speech 02 Turbo models, sets a new standard for ultra-realistic, high-fidelity voice synthesis. With support for over 300 unique voices across 32+ languages, advanced emotion and accent control, and both real-time and long-form text-to-speech capabilities, MiniMax is ideal for applications ranging from gaming and audiobooks to chatbots and localization. The platform offers a generous free tier and quick API integration, making professional voice cloning accessible to everyone.
Frequently Asked Questions
What is MiniMax Voice Cloning?
It’s Novita AI’s advanced voice synthesis feature, using the Speech 02 HD and Turbo models to clone voices from just 10 seconds of reference audio, producing highly natural speech.
What are the differences between Speech 02 HD and Turbo?
Speech 02 HD: Focuses on maximum audio quality and realism, great for audiobooks, dialogue, and long-form content.
Speech 02 Turbo: Optimized for speed and low latency, perfect for real-time interactions and longer texts.
How does MiniMax compare to other voice models?
MiniMax excels in speed, efficiency, and Mandarin performance (especially for China/Asia), while also providing competitive global language support and voice quality compared to ElevenLabs and Cartesia.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



