

لا تقدم Novita AI أربعة نماذج من Speech 02 فقط، بل قدمت أيضًا ميزة استنساخ الصوت. أوضاع المعالجة الأساسية لهذه الميزة هي Speech 02 HD و Speech 02 Turbo. يمكنك تحديد الوضع المطلوب عن طريق تحرير معلمة “model” عند إرسال تعليمات استدعاء API.
جرب استنساخ الصوت MiniMax الآن!
ما هو استنساخ الصوت MiniMax؟
ميزة استنساخ الصوت من Novita AI مدعومة مباشرة من عائلة نماذج Speech 02 - Speech 02 HD و Speech 02 Turbo. كلا النموذجين الفرعيين لـ Speech 02 يدعمان الاستنساخ المتقدم للصوت (voice-clone) من خلال معالجة بضع ثوانٍ فقط (عادةً ≥ 5-10 ثوانٍ) من الصوت المرجعي لتوليد صوت اصطناعي شديد التشابه.
MiniMax Speech 02 هو حل قوي لتحويل النص إلى كلام (TTS) يقدم توليفًا صوتيًا عالي الجودة وطبيعيًا.
الميزات الرئيسية
- مكتبة صوتية واسعة: اختر من بين أكثر من 300 صوت أصلي بعدة لغات.
- التحكم المتقدم في الصوت: اضبط العاطفة، ومستوى الصوت، وسرعة الكلام، وتنسيقات الإخراج بسهولة.
- مزج الصوت المبتكر: ادمج الأصوات الموجودة لإنشاء ملفات صوتية فريدة.
- تنسيقات صوتية متعددة: الإخراج بصيغ FLAC، WAV، MP3، PCM، وغيرها.
- البث المباشر في الوقت الفعلي: توصيل صوتي فوري لتكامل سلس.
- دعم التزامن العالي: أداء موثوق حتى تحت الأحمال الثقيلة.
مقارنة نموذج Speech 02
speech‑02‑hd
- السيناريوهات المناسبة: النصوص القصيرة، الحوار في الوقت الفعلي، الكتب الصوتية، والمحتوى الطويل.
- المزايا: يوفر جودة صوت عالية جدًا وطبيعية، مما يجعله مثاليًا للتطبيقات التي تكون فيها واقعية الصوت أمرًا بالغ الأهمية.
- طول النص المدعوم:
- تحويل النص إلى كلام: حتى ~5000 حرف.
- TTS الطويل غير المتزامن: يدعم معالجة النصوص الطويلة (مئات الآلاف أو حتى ملايين الأحرف) بطريقة قائمة الانتظار وغير متزامنة، مع الحفاظ على جودة صوت عالية.
speech‑02‑turbo
- السيناريوهات المناسبة: التفاعل الصوتي في الوقت الفعلي، النص الطويل في السيناريوهات التفاعلية.
- المزايا: يركز على الاستجابة السريعة وزمن الوصول المنخفض، مما يجعله مثاليًا للمحادثات الفورية والتطبيقات التفاعلية. كما يوازن بين السرعة وقابلية التوسع لمعالجة النصوص الأطول.
- طول النص المدعوم:
- تحويل النص إلى كلام: حتى ~5000 حرف.
- TTS الطويل غير المتزامن: يمكنه التعامل مع النصوص الطويلة بكفاءة، مع معالجة أسرع من الوضع المتزامن.
كيف يحسن MiniMax سرعة استنساخ الصوت؟
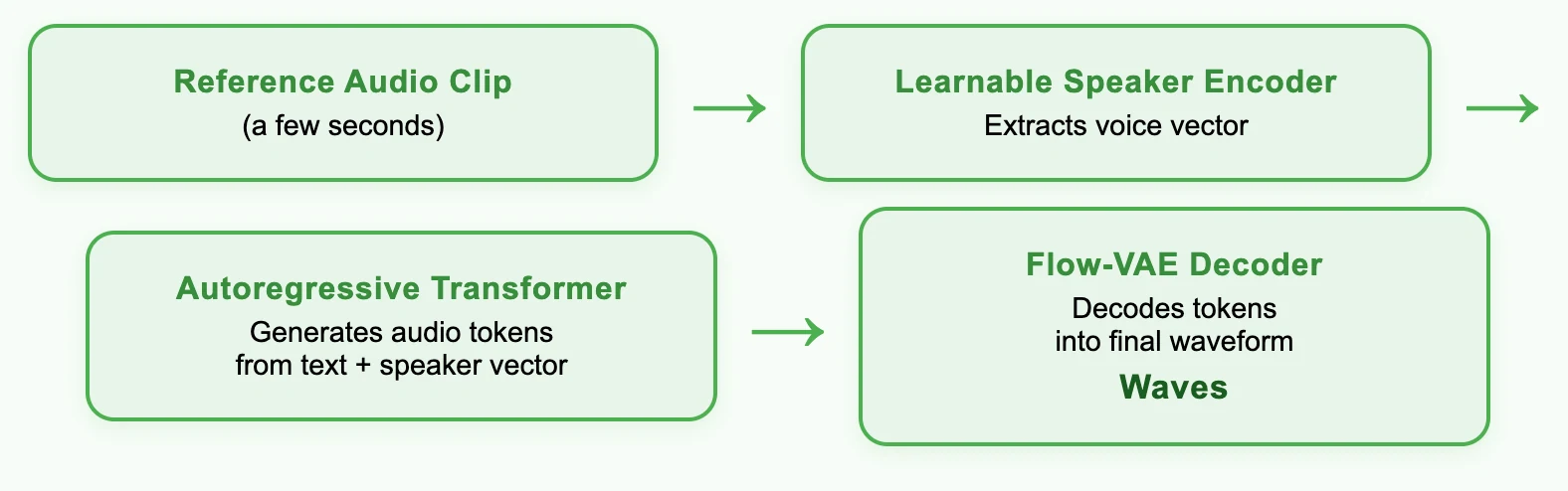
استخدام مزايا MiniMax
1. استنساخ صوت فائق الواقعية
- تشابه يصل إلى 99%:
يحقق نموذج Speech‑02 HD تشابهًا صوتيًا يصل إلى 99%، مما يوفر دقة عالية استثنائية في النبرة والإيقاع واللهجة - حتى مع 10 ثوانٍ فقط من الصوت المرجعي النظيف. - بنية متقدمة:
مبني على إطار عمل MiniMax-Speech zero-shot TTS الأحدث، والذي يتضمن مشفر متحدث قابل للتعلم و Flow-VAE لنمذجة صوتية فائقة. - الاستنساخ متعدد اللغات بدون عينة أو بعينة واحدة:
يتيح استنساخ الصوت بعينة واحدة أو بدون عينة عبر 32 لغة، مما يسمح للمستخدمين بالتقاط جرس صوتي فريد دون الحاجة إلى صوت مرجعي مكتوب.
2. دعم متعدد اللغات والعواطف
يدعم Speech-02 التوليف بأكثر من 30 لغة، بما في ذلك لهجات إقليمية مختلفة. يمكن للمستخدمين أيضًا التحكم في العاطفة والنبرة، مما يعزز طبيعة وتعبيرية الكلام المُولَّد.
3. أدوات مرنة لتحويل النص إلى كلام
يقدم Speech-02 أدوات قوية لاحتياجات متنوعة، مثل:
القراءة من مستند/رابط URL (“اقرأ أي شيء”)
هذه الميزات مفيدة بشكل خاص لإنشاء الكتب الصوتية أو محتوى صوتي طويل.
وضع النص الطويل (يدعم حتى 200000 حرف)
MiniMax مقابل خوارزميات استنساخ الصوت الأخرى
حصل MiniMax Speech 02 على أعلى التصنيفات في Artificial Analysis Speech Arena
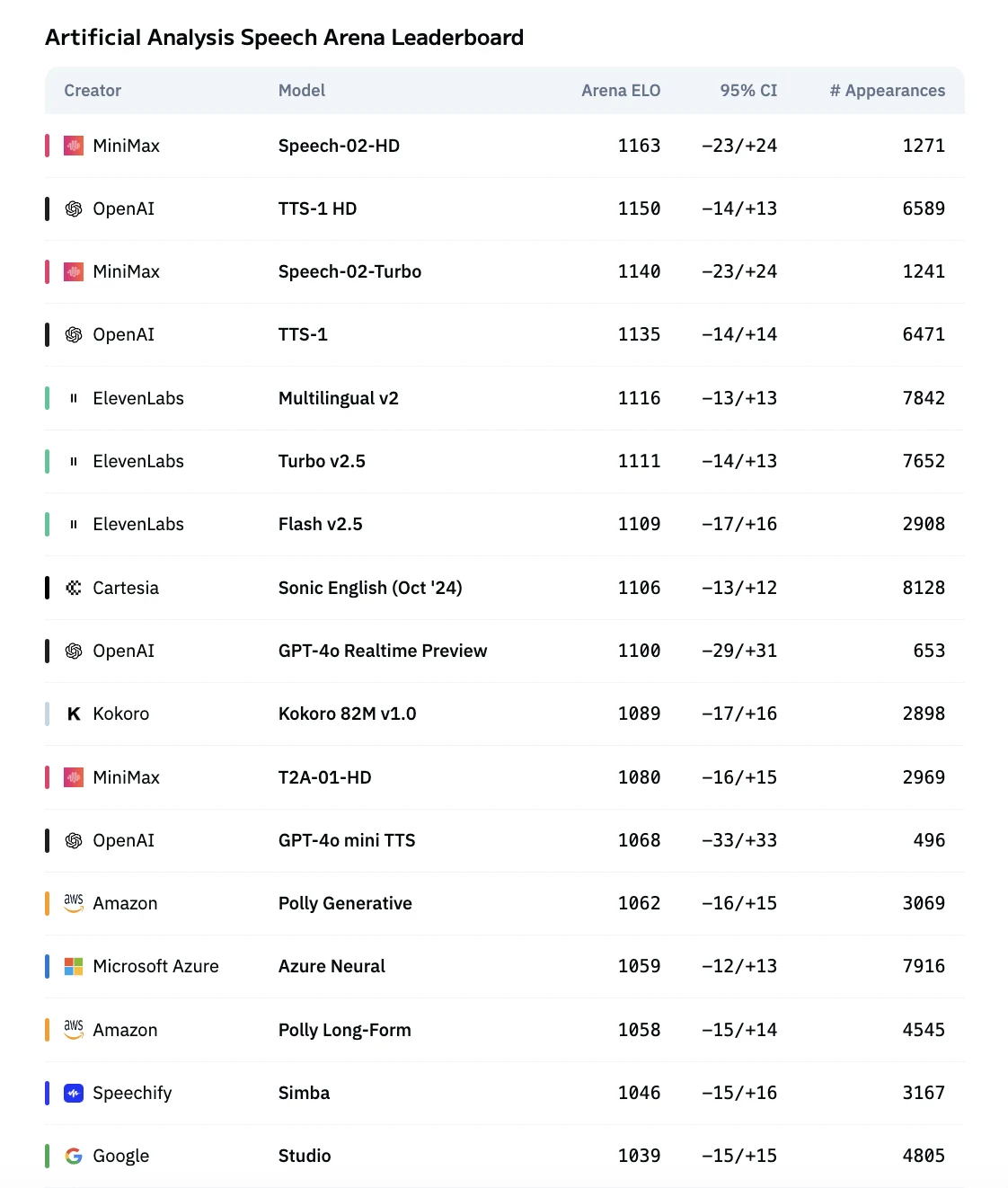
| النموذج | نقاط القوة | الأفضل لـ | المناطق/البلدان الموصى بها |
|---|---|---|---|
| Minimax | استدلال سريع، نشر خفيف الوزن، كفاءة عالية | تطبيقات الوقت الفعلي، روبوتات المحادثة، خدمات قابلة للتوسع | الصين (لغة ماندرين ممتازة، دعم في الوقت الفعلي)؛ جنوب شرق آسيا (سنغافورة، ماليزيا، فيتنام: زمن انتقال منخفض، ماندرين/إنجليزية)؛ الهند (فعالة للهندية، التاميل، إلخ.) |
| ElevenLabs | غني عاطفيًا، تعبيري، رائع لسرد القصص والمحتوى الطويل | البودكاست، الكتب الصوتية، سرد الفيديو، التسويق | الولايات المتحدة/كندا (الإنجليزية الأصلية، لهجات متنوعة)؛ المملكة المتحدة (الإنجليزية البريطانية المتنوعة)؛ أستراليا/نيوزيلندا (الإنجليزية الأسترالية الطبيعية)؛ ألمانيا، فرنسا، إسبانيا (اللغات الأوروبية الرئيسية)؛ اليابان، كوريا (أصوات جذابة، توفر محدود) |
| Cartesia | طلاقة متعددة اللغات، نطق واضح، محتوى جاهز عالميًا | التعلم الإلكتروني، أدوات الترجمة، تطبيقات الصوت العالمية | أوروبا (دعم قوي للألمانية، الفرنسية، الإسبانية، الإيطالية، إلخ.)؛ أمريكا اللاتينية (الإسبانية المحايدة للمحتوى عبر المناطق)؛ الشرق الأوسط وأفريقيا (العربية، اللغات المحلية)؛ EdTech العالمي (نطق واضح لتعليم اللغة) |
تطبيقات الاستنساخ السريع للصوت MiniMax في الألعاب
- أصوات حوار اللاعب مع الذكاء الاصطناعي
تمكين الشخصيات غير القابلة للعب أو المساعدين من التحدث بأصوات مخصصة - يسجل اللاعب مقطعًا، ويقوم الذكاء الاصطناعي باستنساخه لحوار داخل اللعبة أو أصوات الشخصيات المرافقة. - حزم أصوات الشخصيات المخصصة
يمكن لمنسقي البث المباشر أو لاعبي ألعاب تقمص الأدوار على الطاولة إنشاء شخصيات متحدثة مخصصة باستخدام مقاطع الصوت الخاصة بهم أو المقدمة من فريق التمثيل لإثراء لعب الأدوار. - تأثيرات صوتية ديناميكية
التبديل بين الأصوات (مثل مرشح تحت الماء، شرير مشوه، نغمة آلية) مع الحفاظ على نفس سمات الصوت المستنسخ الأساسي للانغماس. - التعريب دون فقدان هوية الصوت
يمكن للرواة أو الشخصيات التحدث بعدة لغات باستخدام نفس الصوت المستنسخ، والحفاظ على الشخصية عبر الترجمات. - التسويق والإعلانات التشويقية التفاعلية
مقاطع صوتية لإعلانات الألعاب أو المواد الترويجية باستخدام نسخ صوتية ذات لهجة العلامة التجارية للحفاظ على الهوية عبر الوسائط.
كيفية استخدام MiniMax للاستنساخ السريع للصوت في Novita AI؟
توفر Novita AI واجهة برمجة تطبيقات (API) بسيطة وقوية لتمكين الاستنساخ السريع. فيما يلي دليل خطوة بخطوة حول كيفية استخدام واجهة API MiniMax Speech 02 لاستنساخ الصوت.
الخطوة 1: رفع ملف صوتي
- يجب أن يكون ملف الصوت المرفوع بصيغة mp3 أو m4a أو wav.
- يجب أن تكون مدة الصوت المرفوع 10 ثوانٍ على الأقل ولا تزيد عن 5 دقائق.
- يجب ألا يتجاوز حجم ملف الصوت المرفوع 20 ميغابايت.
الخطوة 2: تعيين المعلمات
الرأس (Header)
| الرأس | النوع | مطلوب | المعنى / الوصف |
|---|---|---|---|
| Content-Type | string | نعم | يحدد نوع الوسائط لنص الطلب. استخدم application/json. |
| Authorization | string | نعم | رمز التوثيق (Bearer token) لمصادقة API. التنسيق: Bearer {مفتاح API}. مثال: Bearer sk-xxxxxx |
الجسم (Body)
| المعامل | النوع | المعنى / الوصف |
|---|---|---|
audio_url |
string | عنوان URL لملف الصوت المراد استنساخه. التنسيقات المدعومة: mp3, m4a, wav. |
clone_prompt |
object | معلمات استنساخ الصوت لتحسين التشابه/الاستقرار. يتطلب عينة صوتية قصيرة (<8 ثوانٍ) ونصًا مكتوبًا. |
text_validation |
string | حتى 200 حرف. إذا تم توفيره، يتحقق الخدمة من تطابق الصوت والنص؛ خطأ 1043 إذا لم يتطابقا. |
text |
string | نص (حتى 2000 حرف) لتوليفه للمعاينة. النتيجة تُرجع كعنوان URL للصوت. |
model |
string | يحدد نموذج الكلام للمعاينة. الخيارات: speech-02-hd، speech-02-turbo. |
accuracy |
float | قيمة بين 0 و 1. يحدد عتبة الدقة للتحقق من النص. القيمة الافتراضية: 0.7. |
need_noise_reduction |
bool | تفعيل تقليل الضوضاء. القيمة الافتراضية: false. |
need_volume_normalization |
bool | تفعيل تطبيع مستوى الصوت. القيمة الافتراضية: false. |
الخطوة 3: الحصول على مفتاح API

الخطوة 4: مثال بلغة Python
import requests
url = "https://api.novita.ai/v3/minimax-voice-cloning"
payload = {
"audio_url": "<string>",
"text_validation": "<string>",
"text": "<string>",
"model": "<string>",
"accuracy": 123,
"need_noise_reduction": True,
"need_volume_normalization": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
الاستجابة
{
"demo_audio_url": "<string>",
"voice_id": "<string>"
}
إن ميزة استنساخ الصوت MiniMax الجديدة من Novita AI، المدعومة بنماذج Speech 02 HD و Speech 02 Turbo، تضع معيارًا جديدًا للتوليف الصوتي فائق الواقعية وعالي الدقة. مع دعم أكثر من 300 صوت فريد عبر أكثر من 32 لغة، والتحكم المتقدم في العاطفة واللهجة، وقدرات تحويل النص إلى كلام في الوقت الفعلي والطويلة، فإن MiniMax مثالي للتطبيقات التي تتراوح من الألعاب والكتب الصوتية إلى روبوتات المحادثة والتعريب. توفر المنصة طبقة مجانية سخية وتكاملًا سريعًا مع واجهة API، مما يجعل استنساخ الصوت الاحترافي في متناول الجميع.
الأسئلة الشائعة
ما هو استنساخ الصوت MiniMax؟
هي ميزة توليف صوتي متقدمة من Novita AI، تستخدم نماذج Speech 02 HD و Turbo لاستنساخ الأصوات من 10 ثوانٍ فقط من الصوت المرجعي، مما ينتج كلامًا طبيعيًا للغاية.
ما الفروق بين Speech 02 HD و Turbo؟
Speech 02 HD: يركز على أقصى جودة صوتية وواقعية، رائع للكتب الصوتية والحوار والمحتوى الطويل.
Speech 02 Turbo: مُحسَّن للسرعة وزمن الوصول المنخفض، مثالي للتفاعلات في الوقت الفعلي والنصوص الأطول.
كيف يقارن MiniMax بنماذج الصوت الأخرى؟
يتفوق MiniMax في السرعة والكفاءة وأداء لغة الماندرين (خاصة للصين/آسيا)، مع تقديم دعم تنافسي للغات العالمية وجودة صوتية مقارنة بـ ElevenLabs و Cartesia.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، وخدمات غير خادمية، ومثيلات GPU - الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، وابدأ مجانًا، واجعل رؤيتك للذكاء الاصطناعي حقيقة.



