

Novita AI는 Speech 02의 네 가지 모델을 출시했을 뿐만 아니라 음성 복제 기능도 도입했습니다. 이 기능의 기본 처리 모드는 Speech 02 HD와 Speech 02 Turbo입니다. API 호출 명령을 보낼 때 “model” 매개변수를 수정하여 원하는 모드를 지정할 수 있습니다.
MiniMax 음성 복제란?
Novita AI의 음성 복제 기능은 Speech 02 모델군(Speech 02 HD 및 Speech 02 Turbo)에 의해 직접 구동됩니다. 두 Speech 02 하위 모델 모두 몇 초(일반적으로 ≥5~10초)의 참조 오디오만 처리하여 매우 유사한 합성 음성을 생성하는 고급 음성 복제(voice-clone)를 지원합니다.
Minimax Speech 02 는 고품질의 자연스러운 오디오 합성을 제공하는 강력한 텍스트 음성 변환(TTS) 솔루션입니다.
주요 기능
- 방대한 음성 라이브러리: 여러 언어로 300개 이상의 정통 음성 중에서 선택할 수 있습니다.
- 고급 음성 제어: 감정, 볼륨, 말하기 속도 및 출력 형식을 쉽게 조정할 수 있습니다.
- 혁신적인 음성 혼합: 기존 음성을 혼합하여 고유한 음성 프로필을 만들 수 있습니다.
- 다양한 오디오 형식: FLAC, WAV, MP3, PCM 등으로 출력할 수 있습니다.
- 실시간 스트리밍: 원활한 통합을 위한 즉각적인 오디오 전달.
- 높은 동시성 지원: 많은 작업 부하에서도 안정적인 성능.
Speech 02 모델 비교
speech‑02‑hd
-
적합한 시나리오: 짧은 텍스트, 실시간 대화, 오디오북 및 장문 콘텐츠.
-
장점: 매우 높은 오디오 품질과 자연스러움을 제공하여 음성 사실성이 중요한 애플리케이션에 이상적입니다.
-
지원 텍스트 길이:
- 텍스트 음성 변환: 최대 ~5,000자.
- 비동기 긴 TTS: 대기열 방식의 비동기 방식으로 수십만 또는 수백만 자의 긴 텍스트 처리를 지원하며 최고의 오디오 품질을 유지합니다.
speech‑02‑turbo
-
적합한 시나리오: 실시간 음성 상호 작용, 대화형 시나리오의 긴 텍스트.
-
장점: 빠른 응답과 낮은 지연 시간에 중점을 두어 즉각적인 대화 및 대화형 애플리케이션에 적합합니다. 또한 긴 텍스트 처리 시 속도와 확장성의 균형을 유지합니다.
-
지원 텍스트 길이:
- 텍스트 음성 변환: 최대 ~5,000자.
- 비동기 긴 TTS: 긴 텍스트를 효율적으로 처리할 수 있으며 동기 모드보다 처리 속도가 빠릅니다.
MiniMax가 음성 복제 속도를 어떻게 개선하나요?
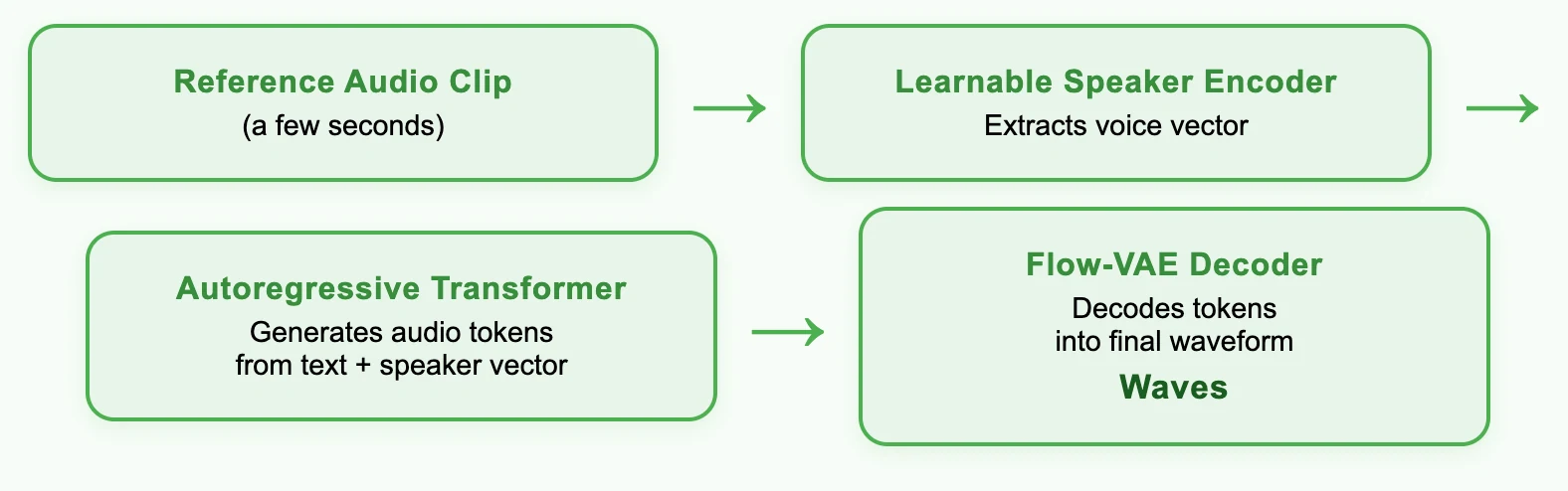
MiniMax 사용의 장점
1. 초현실적인 음성 복제
- 최대 99% 유사도:
Speech‑02 HD 모델은 깨끗한 참조 오디오가 10초만 있어도 최대 99%의 음성 유사도를 달성하여 음색, 억양 및 악센트에서 매우 높은 충실도를 제공합니다. - 고급 아키텍처:
최신 MiniMax-Speech 제로샷 TTS 프레임워크를 기반으로 구축되었으며, 학습 가능한 화자 인코더와 Flow-VAE를 포함하여 우수한 음성 모델링을 제공합니다. - 다국어 제로샷 및 원샷 복제:
32개 언어에서 원샷 또는 제로샷 음성 복제를 지원하여 사용자가 전사된 참조 오디오 없이도 고유한 음색을 포착할 수 있습니다.
2. 다국어 및 감정 지원
Speech-02는 다양한 지역 억양을 포함하여 30개 이상의 언어 로 합성을 지원합니다. 또한 사용자는 감정과 어조를 제어하여 생성된 음성의 자연스러움과 표현력을 더욱 향상시킬 수 있습니다.
3. 유연한 텍스트 음성 변환 도구
Speech-02는 다양한 요구에 맞는 강력한 도구를 제공합니다. 예:
문서/URL 기반 읽기(“Read Anything”)
이 기능은 오디오북 또는 기타 장문 오디오 콘텐츠를 만드는 데 특히 유용합니다.
긴 텍스트 모드(최대 200,000자 지원)
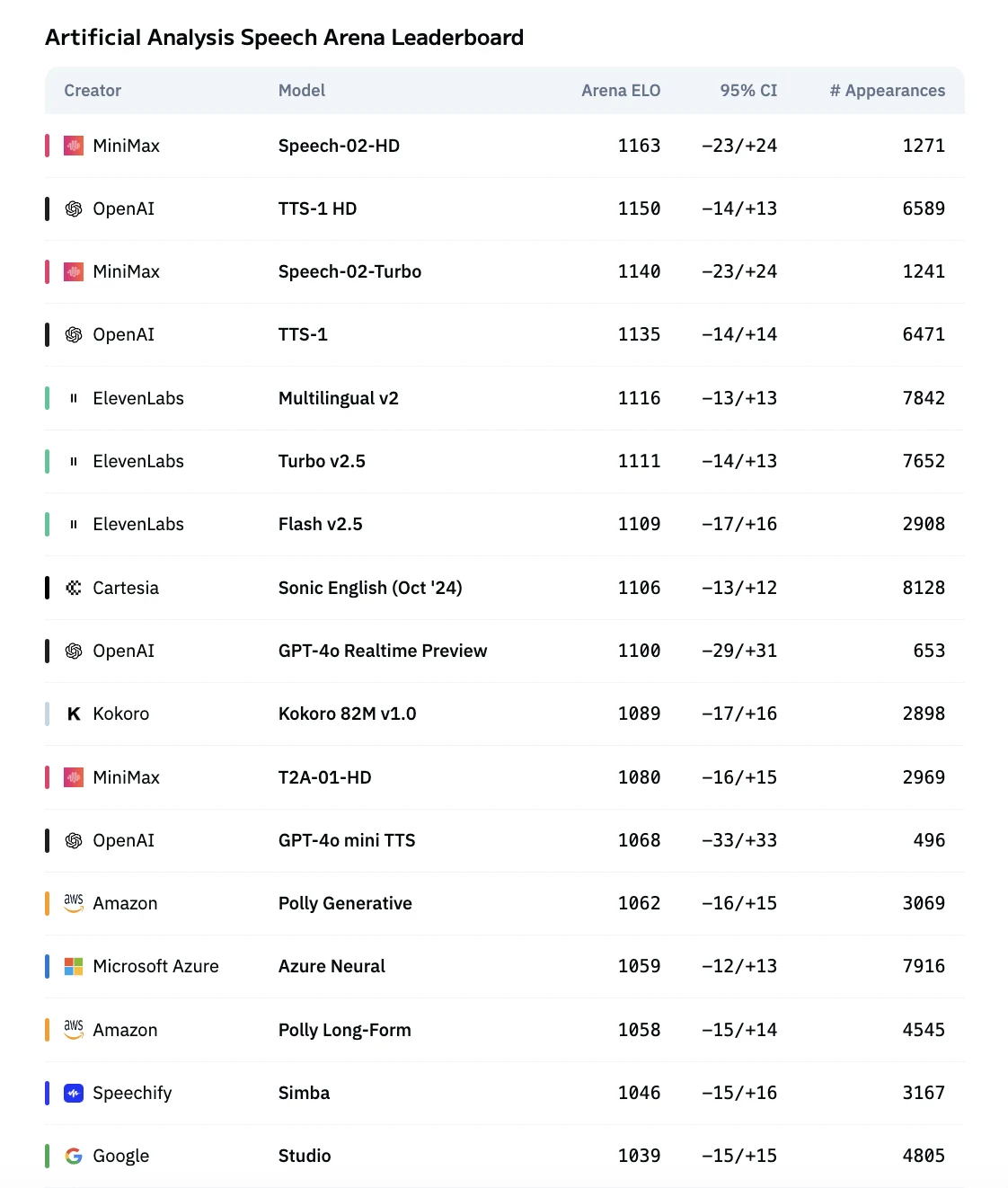
MiniMax vs 기타 음성 복제 알고리즘
MiniMax Speech 02는 Artificial Analysis Speech Arena에서 최고 등급을 받았습니다.
| 모델 | 강점 | 최적 사용 사례 | 권장 지역/국가 |
|---|---|---|---|
| Minimax | 빠른 추론, 가벼운 배포, 높은 효율성 | 실시간 앱, 챗봇, 확장 가능한 서비스 | 중국(뛰어난 Mandarin, 실시간 지원), 동남아시아(싱가포르, 말레이시아, 베트남: 낮은 지연 시간, Mandarin/영어), 인도(힌디어, 타밀어 등 효율적) |
| ElevenLabs | 감정이 풍부하고 표현력이 뛰어나며 스토리텔링과 장문에 적합 | 팟캐스트, 오디오북, 비디오 내레이션, 마케팅 | 미국/캐나다(원어민 영어, 다양한 억양), 영국(다양한 영국 영어), 호주/뉴질랜드(자연스러운 호주 영어), 독일, 프랑스, 스페인(주요 유럽 언어), 일본, 한국(매력적인 음성, 제한적 가용성) |
| Cartesia | 다국어 능력, 명확한 발음, 글로벌 콘텐츠 준비 완료 | 이러닝, 번역 도구, 글로벌 음성 앱 | 유럽(독일어, 프랑스어, 스페인어, 이탈리아어 등 강력 지원), 라틴 아메리카(지역 간 콘텐츠를 위한 중립 스페인어), 중동 및 아프리카(아랍어, 현지 언어), 글로벌 에드테크(언어 교육을 위한 명확한 발음) |
게임에서 MiniMax 빠른 음성 복제의 응용
- 플레이어-AI 대화 음성
NPC 또는 어시스턴트가 개인화된 음성으로 말할 수 있도록 지원합니다. 플레이어가 클립을 녹음하면 AI가 이를 복제하여 게임 내 대화나 동반자 캐릭터 음성에 사용합니다. - 맞춤형 캐릭터 음성 팩
스트리밍 DC 또는 TTRPG 플레이어는 자신 또는 캐스트가 제공한 음성 클립을 사용하여 맞춤형 말하는 캐릭터를 만들 수 있어 롤플레이가 더욱 풍부해집니다. - 동적 음성 효과
음성 전환(예: 수중 필터, 왜곡된 악당, 로봇 톤)을 하면서도 동일한 복제 음성 특성을 유지하여 몰입감을 높입니다. - 음성 아이덴티티를 유지하는 현지화
내레이터나 캐릭터가 동일한 복제 음성을 사용하여 여러 언어로 말할 수 있으므로 번역 전반에 걸쳐 개성을 유지합니다. - 몰입형 마케팅 및 트레일러
브랜드 악센트를 가진 음성 복제를 사용하여 게임 트레일러나 프로모션 자료의 음성 클립을 제작, 미디어 전반에서 아이덴티티를 유지합니다.
Novita AI에서 MiniMax 빠른 음성 복제를 사용하는 방법은?
Novita AI는 빠른 복제를 가능하게 하는 간단하면서도 강력한 API를 제공합니다. 아래는 MInimax Speech 02 API를 사용한 음성 복제 단계별 가이드입니다.
1단계: 오디오 파일 업로드
- 업로드된 오디오 파일은 mp3, m4a 또는 wav 형식이어야 합니다.
- 업로드된 오디오의 길이는 최소 10초 이상, 최대 5분 이하여야 합니다.
- 업로드된 오디오 파일 크기는 20MB를 초과할 수 없습니다.
2단계: 매개변수 설정
헤더
| 헤더 | 유형 | 필수 | 의미 / 설명 |
|---|---|---|---|
| Content-Type | string | 예 | 요청 본문의 미디어 유형을 지정합니다. application/json을 사용하세요. |
| Authorization | string | 예 | API 인증을 위한 Bearer 토큰입니다. 형식: Bearer {API Key}. 예: Bearer sk-xxxxxx |
본문
| 매개변수 | 유형 | 의미 / 설명 |
|---|---|---|
audio_url |
string | 복제할 오디오 파일의 URL입니다. 지원 형식: mp3, m4a, wav. |
clone_prompt |
object | 유사도/안정성을 개선하기 위한 음성 복제 매개변수입니다. 짧은 샘플 오디오(<8초)와 대본이 필요합니다. |
text_validation |
string | 최대 200자. 제공되면 서비스가 오디오와 텍스트가 일치하는지 확인합니다. 일치하지 않으면 오류 1043이 반환됩니다. |
text |
string | 미리 보기용으로 합성할 텍스트(최대 2000자)입니다. 결과는 오디오 URL로 반환됩니다. |
model |
string | 미리 보기에 사용할 음성 모델을 지정합니다. 옵션: speech-02-hd, speech-02-turbo. |
accuracy |
float | 0과 1 사이의 값입니다. 텍스트 검증의 정확도 임계값을 설정합니다. 기본값: 0.7. |
need_noise_reduction |
bool | 노이즈 감소를 활성화합니다. 기본값: false. |
need_volume_normalization |
bool | 볼륨 정규화를 활성화합니다. 기본값: false. |
3단계: API 키 가져오기

4단계: Python 예제
import requests
url = "https://api.novita.ai/v3/minimax-voice-cloning"
payload = {
"audio_url": "<string>",
"text_validation": "<string>",
"text": "<string>",
"model": "<string>",
"accuracy": 123,
"need_noise_reduction": True,
"need_volume_normalization": True
}
headers = {
"Content-Type": "<content-type>",
"Authorization": "<authorization>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
응답
{
"demo_audio_url": "<string>",
"voice_id": "<string>"
}
Speech 02 HD 및 Speech 02 Turbo 모델로 구동되는 Novita AI의 새로운 MiniMax 음성 복제는 초현실적이고 고충실도의 음성 합성에 대한 새로운 표준을 제시합니다. 32개 이상의 언어로 300개 이상의 고유 음성, 고급 감정 및 악센트 제어, 실시간 및 장문 텍스트 음성 변환 기능을 갖춘 MiniMax는 게임, 오디오북, 챗봇, 현지화 등 다양한 애플리케이션에 이상적입니다. 이 플랫폼은 넉넉한 무료 티어와 빠른 API 통합을 제공하여 전문가 수준의 음성 복제를 누구나 사용할 수 있게 합니다.
자주 묻는 질문
MiniMax 음성 복제란 무엇인가요?
Novita AI의 고급 음성 합성 기능으로, Speech 02 HD 및 Turbo 모델을 사용하여 10초의 참조 오디오만으로 음성을 복제하고 매우 자연스러운 음성을 생성합니다.
Speech 02 HD와 Turbo의 차이점은 무엇인가요?
Speech 02 HD: 최대 오디오 품질과 사실성에 중점을 두며 오디오북, 대화, 장문 콘텐츠에 적합합니다.
Speech 02 Turbo: 속도와 낮은 지연 시간에 최적화되어 실시간 상호작용 및 긴 텍스트에 적합합니다.
MiniMax는 다른 음성 모델과 어떻게 비교되나요?
MiniMax는 속도, 효율성 및 Mandarin 성능(특히 중국/아시아)에서 탁월하며, ElevenLabs 및 Cartesia와 비교하여 경쟁력 있는 글로벌 언어 지원 및 음성 품질을 제공합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구입니다. 인프라를 없애고 무료로 시작하여 AI 비전을 현실로 만드세요.



