

Key Highlights
Model Overview: Llama 3.2 1B is a lightweight, multilingual LLM by Meta designed for efficient use on edge and mobile devices.
Training Method: Employs structured pruning and knowledge distillation from larger models.
Hardware Requirements: Requires 3.14 GB VRAM for inference and 14.11 GB for fine-tuning.
Llama 3.2 1B is an advanced multilingual large language model created by Meta, specifically engineered for lightweight deployment on mobile and edge devices. Its architecture allows for robust performance across various natural language processing tasks while maintaining efficient resource usage.
Refer your friends to Novita AI and both of you will earn $10 in LLM API credits—up to $500 in total rewards.
To support the developer community, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B is currently available for free on Novita AI.

What is Llama 3.2 1B?
The Llama 3.2 1B model is a lightweight, multilingual large language model developed by Meta, designed to run efficiently on edge and mobile devices while providing strong performance for various natural language processing tasks.

-
Model Size: 1B
-
Open Source: Yes
-
Architecture: Dense Transform
-
Context Length: 128,000 tokens
-
Supported Multilingual Languages:
- Officially Supported: English, German, French, Italian, Portuguese, Hindi, Spanish, Thai
- Broader Collection: Trained on additional languages beyond the 8 listed.
-
Multimodal Capability:
- Input: Text
- Output: Text and Code
-
Trained Method: Llama 3.2 1B was trained using structured pruning from the Llama 3.1 8B model, systematically removing parts of the network while adjusting weights to create a smaller, efficient model. It also employed knowledge distillation, where logits from the Llama 3.1 8B and 70B models were used as token-level targets during pre-training. This approach enabled Llama 3.2 1B to leverage insights from larger models, enhancing its performance after the pruning process.
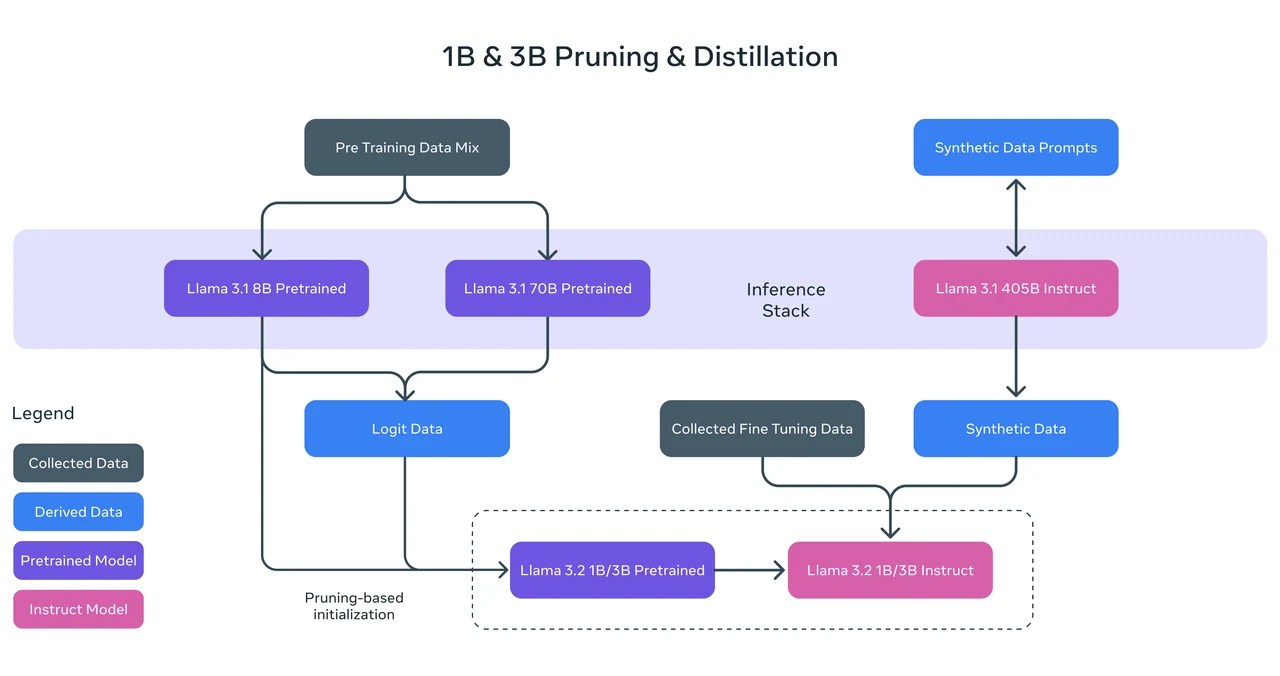
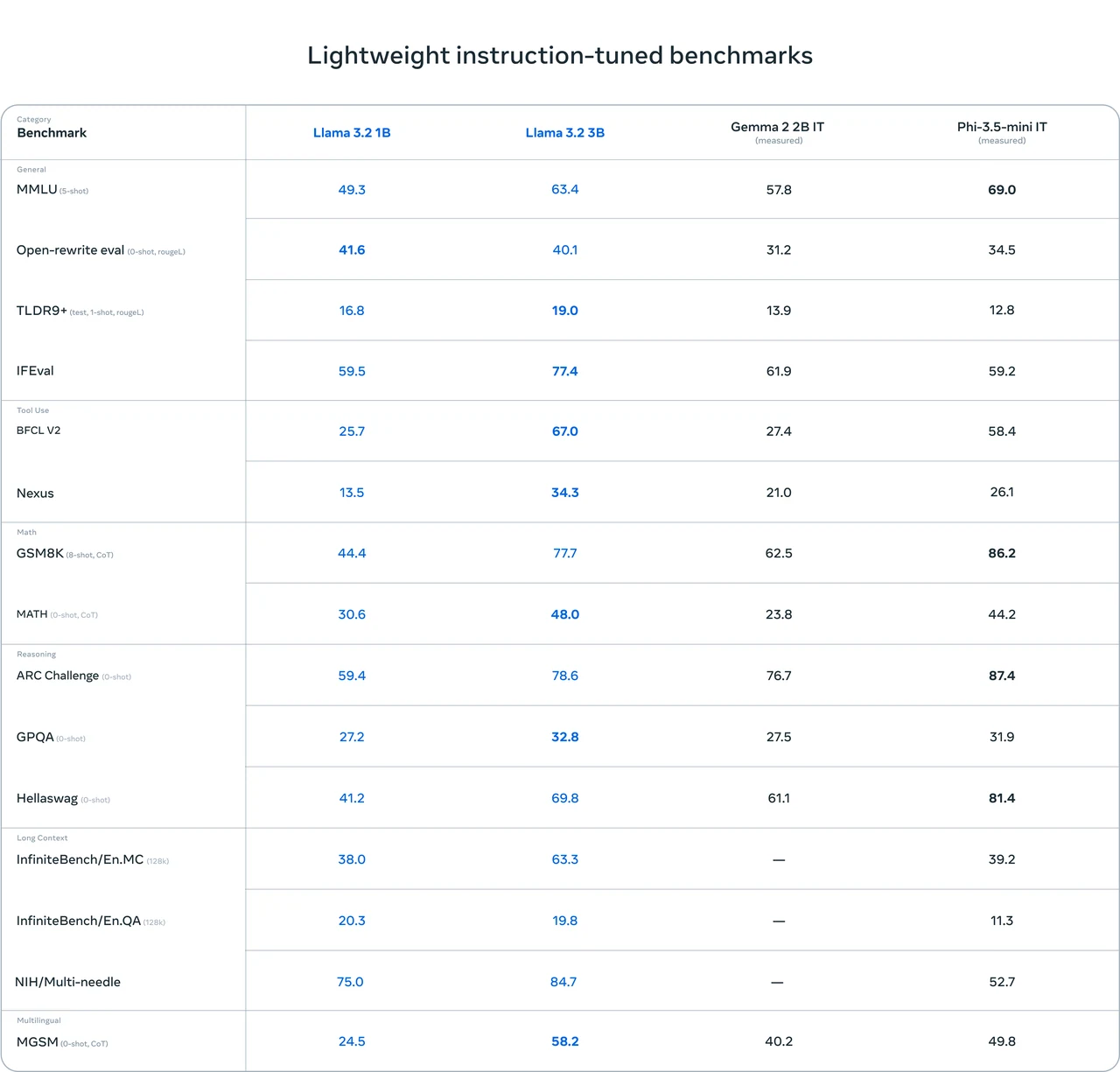
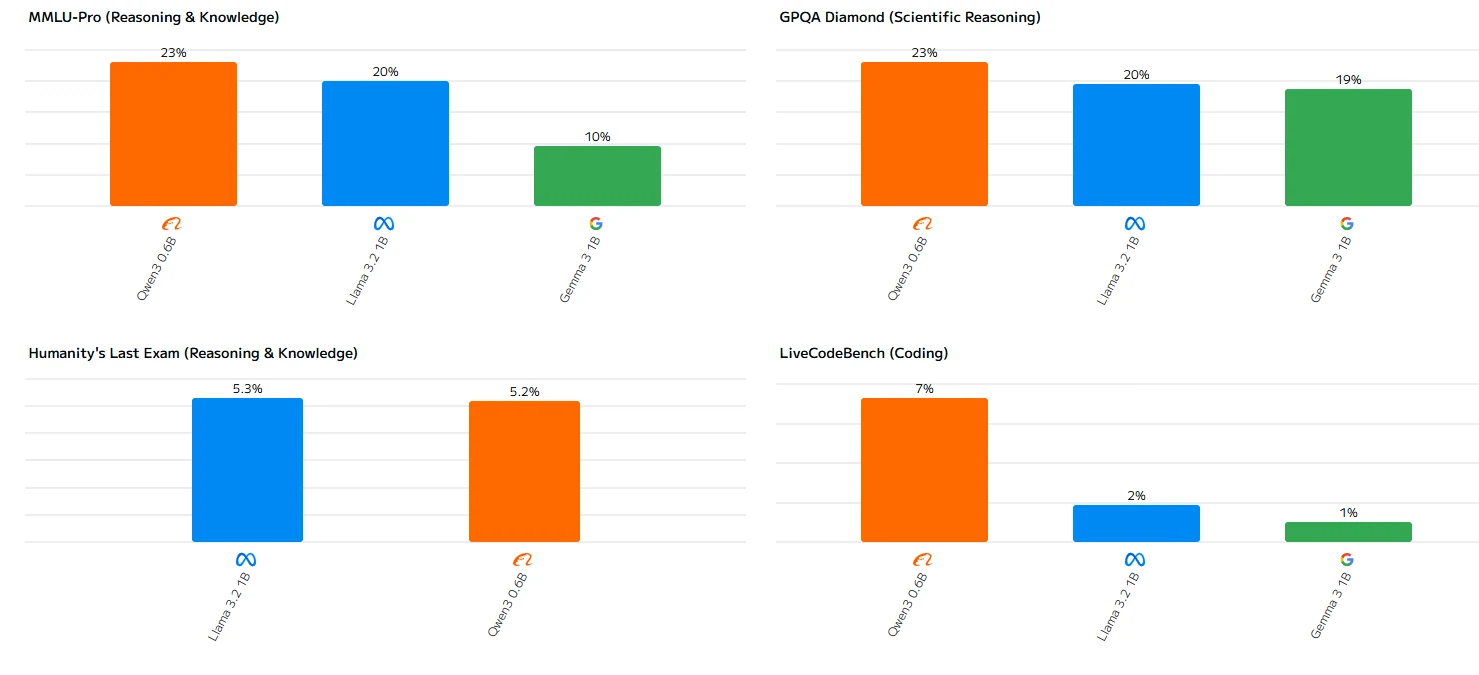
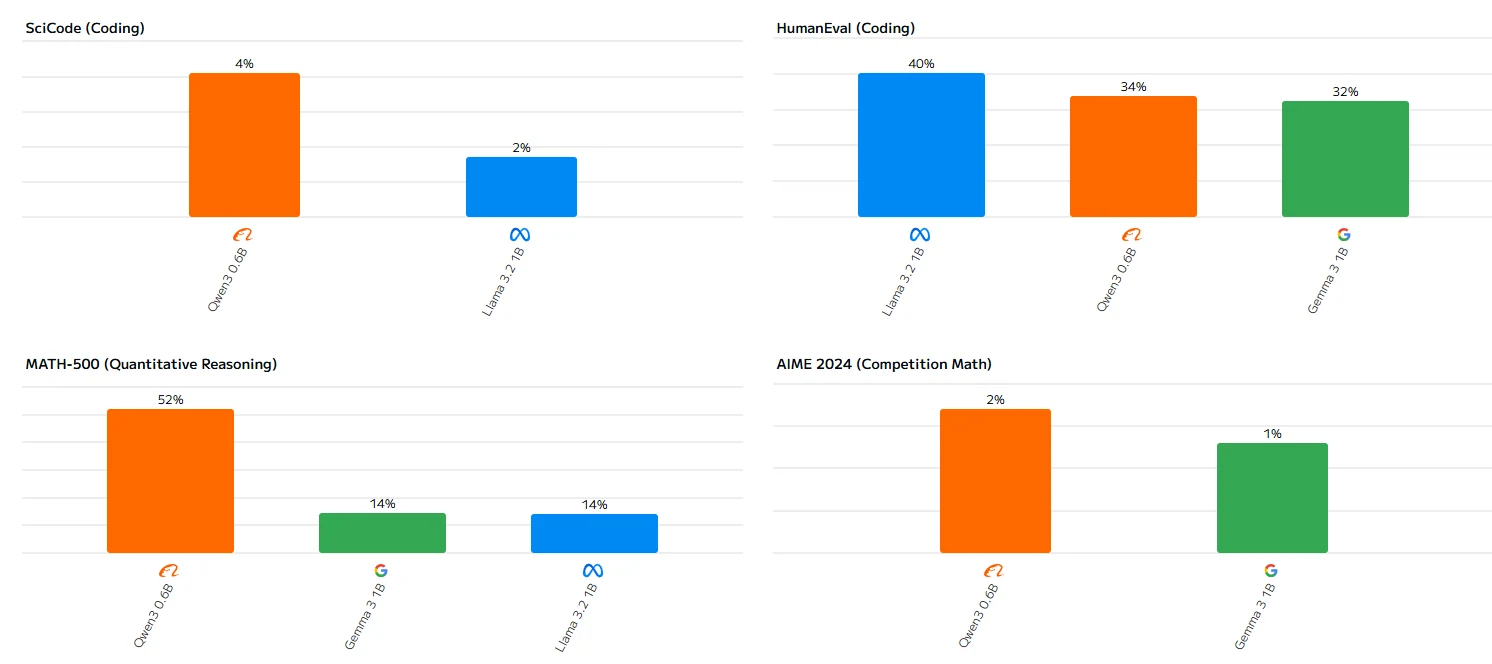
Llama 3.2 1B Benchmark
Llama 3.2 1B Hardware Requirements
Inference Details
-
Model: Llama 3.2 1B
-
Quantization: FP16
-
VRAM Required (Inference): 3.14 GB
-
Compatible GPUs:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
Fine-Tuning Details
- Model: Llama 3.2 1B
- Quantization: FP16
- VRAM Required (Fine-Tuning): 14.11 GB
- Compatible GPU: RTX 4090 (24 GB)
Meta has released quantized versions of Llama 3.2 1B and 3B models, significantly reducing their size and computational requirements. These quantized models offer up to a 56% reduction in model size and a 41% decrease in memory usage compared to their original counterparts. Such optimizations make them suitable for deployment on mobile devices, including smartphones with ARM-based CPUs .
How to Access Llama 3.2 1B?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
In summary, Llama 3.2 1B stands out for its ability to deliver powerful language processing capabilities on constrained devices. With its open-source nature and optimized architecture, it serves as a valuable tool for developers seeking efficient AI solutions.
Frequently Asked Questions
What is Llama 3.2 1B?
A multilingual lightweight language model designed for efficient deployment on mobile devices.
What are the hardware requirements of Llama 3.2 1B?
Inference requires 3.14 GB VRAM; fine-tuning needs 14.11 GB VRAM.
Are Llama 3.2 1B models free to use?
Yes! Novita AI offers free access to Llama 3.2 1B models with easy API integration.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



