

Principais Destaques
Visão Geral do Modelo: Llama 3.2 1B é um LLM multilíngue e leve da Meta, projetado para uso eficiente em dispositivos de borda e móveis.
Método de Treinamento: Utiliza poda estruturada e destilação de conhecimento de modelos maiores.
Requisitos de Hardware: Requer 3,14 GB de VRAM para inferência e 14,11 GB para ajuste fino.
O Llama 3.2 1B é um modelo de linguagem multilíngue avançado criado pela Meta, especialmente projetado para implantação leve em dispositivos móveis e de borda. Sua arquitetura permite desempenho robusto em várias tarefas de processamento de linguagem natural, mantendo o uso eficiente de recursos.
Indique seus amigos para a Novita AI e ambos ganharão $10 em créditos de API LLM — até $500 em recompensas totais.
Para apoiar a comunidade de desenvolvedores, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B estão atualmente disponíveis gratuitamente na Novita AI.

O que é Llama 3.2 1B?
O modelo Llama 3.2 1B é um modelo de linguagem multilíngue e leve desenvolvido pela Meta, projetado para rodar de forma eficiente em dispositivos de borda e móveis, oferecendo desempenho robusto para várias tarefas de processamento de linguagem natural.

-
Tamanho do Modelo: 1B
-
Código Aberto: Sim
-
Arquitetura: Dense Transform
-
Comprimento do Contexto: 128.000 tokens
-
Idiomas Multilíngues Suportados:
- Suporte Oficial: Inglês, Alemão, Francês, Italiano, Português, Hindi, Espanhol, Tailandês
- Coleção Mais Ampla: Treinado em idiomas adicionais além dos 8 listados.
-
Capacidade Multimodal:
- Entrada: Texto
- Saída: Texto e Código
-
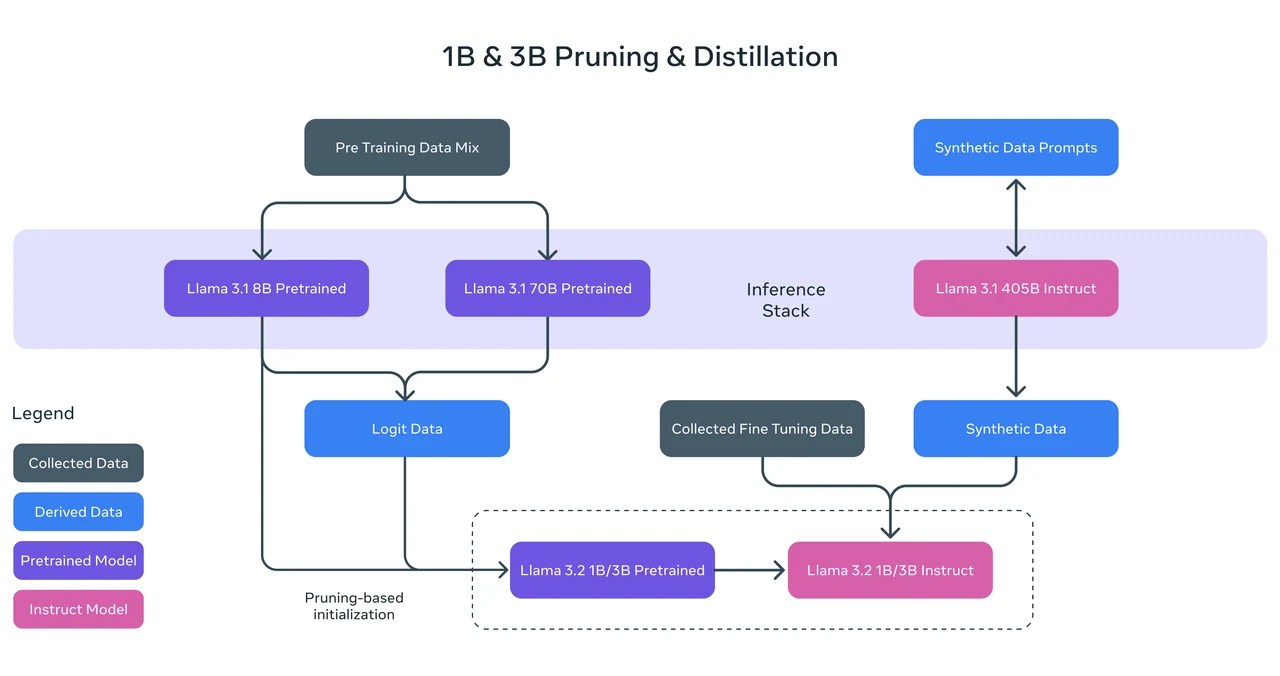
Método de Treinamento: O Llama 3.2 1B foi treinado usando poda estruturada a partir do modelo Llama 3.1 8B, removendo sistematicamente partes da rede enquanto ajustava pesos para criar um modelo menor e eficiente. Também empregou destilação de conhecimento, onde os logits dos modelos Llama 3.1 8B e 70B foram usados como alvos no nível do token durante o pré-treinamento. Essa abordagem permitiu que o Llama 3.2 1B aproveitasse insights de modelos maiores, melhorando seu desempenho após o processo de poda.
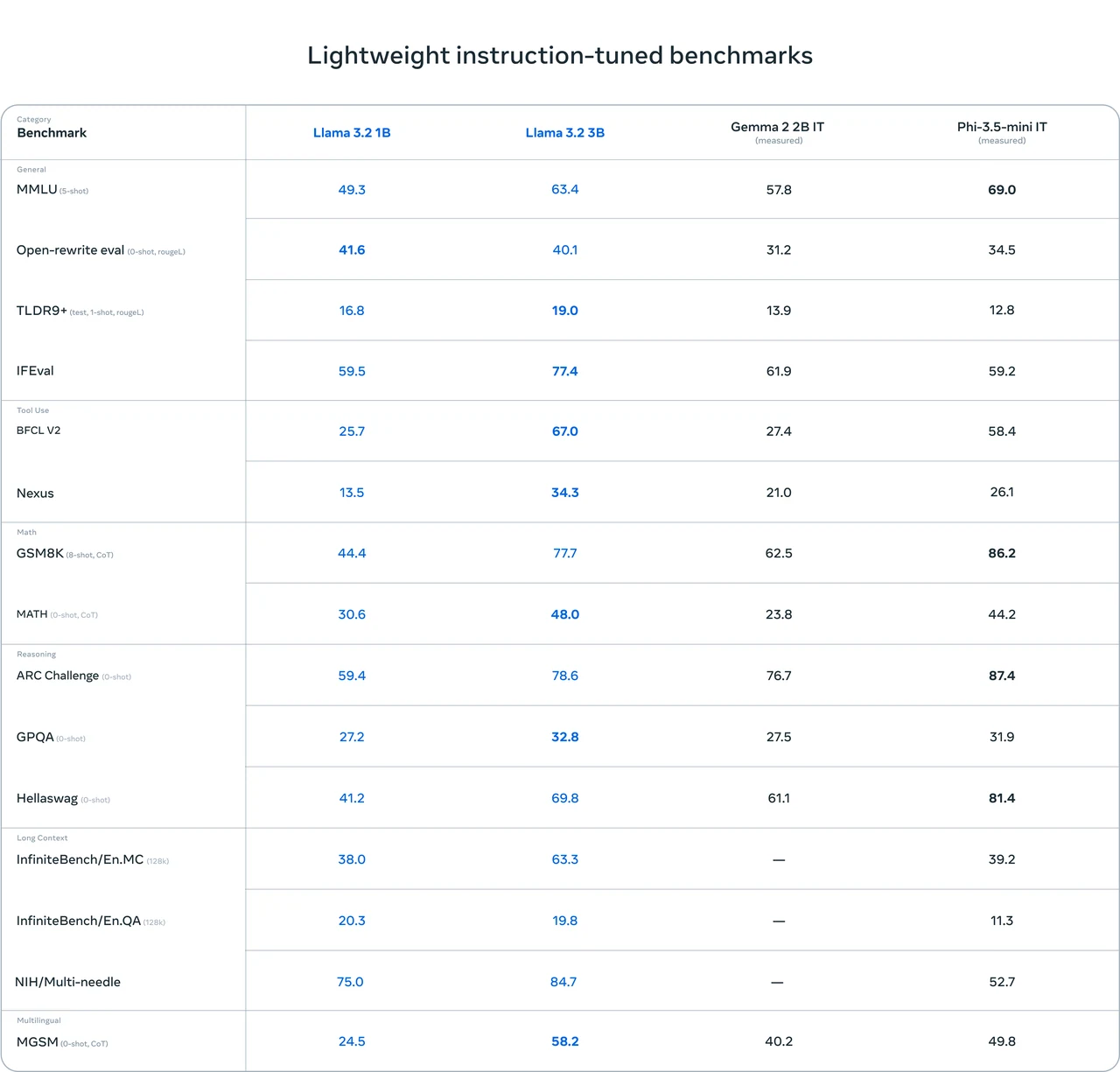
Benchmark do Llama 3.2 1B
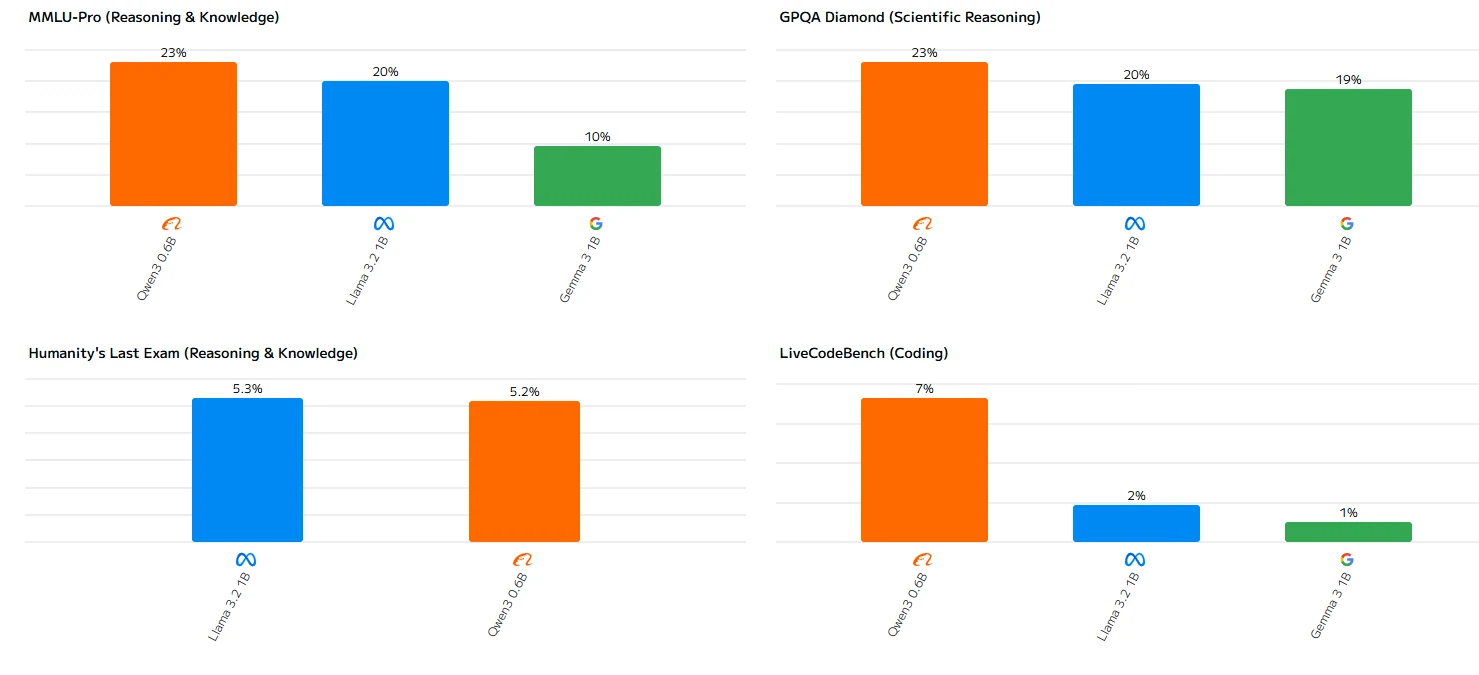
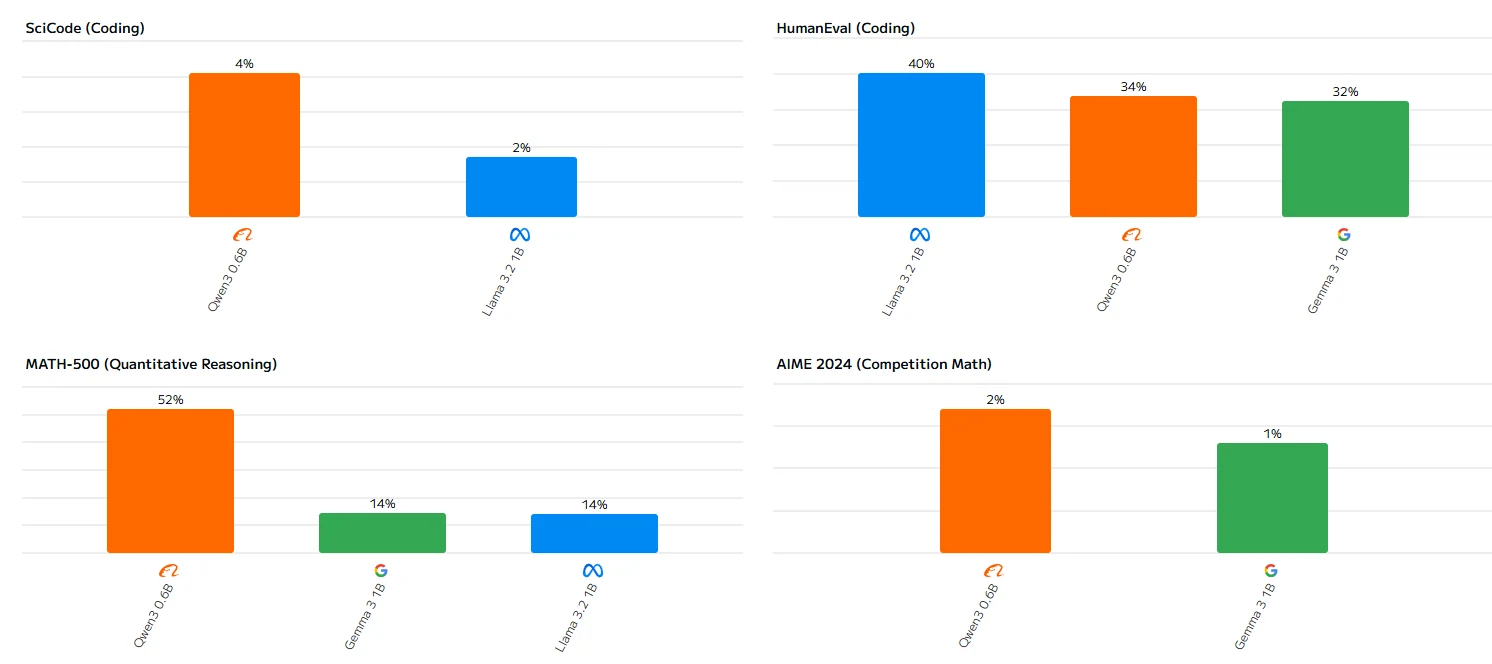
Requisitos de Hardware do Llama 3.2 1B
Detalhes de Inferência
-
Modelo: Llama 3.2 1B
-
Quantização: FP16
-
VRAM Necessária (Inferência): 3,14 GB
-
GPUs Compatíveis:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
Detalhes de Fine-Tuning
- Modelo: Llama 3.2 1B
- Quantização: FP16
- VRAM Necessária (Fine-Tuning): 14,11 GB
- GPU Compatível: RTX 4090 (24 GB)
A Meta lançou versões quantizadas dos modelos Llama 3.2 1B e 3B, reduzindo significativamente seu tamanho e requisitos computacionais. Esses modelos quantizados oferecem uma redução de até 56% no tamanho do modelo e uma diminuição de 41% no uso de memória em comparação com suas versões originais. Essas otimizações os tornam adequados para implantação em dispositivos móveis, incluindo smartphones com CPUs baseadas em ARM.
Como Acessar o Llama 3.2 1B?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entre na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Em resumo, o Llama 3.2 1B se destaca por sua capacidade de oferecer poderosas capacidades de processamento de linguagem em dispositivos com recursos limitados. Com sua natureza de código aberto e arquitetura otimizada, é uma ferramenta valiosa para desenvolvedores que buscam soluções de IA eficientes.
Perguntas Frequentes
O que é o Llama 3.2 1B?
Um modelo de linguagem multilíngue e leve, projetado para implantação eficiente em dispositivos móveis.
Quais são os requisitos de hardware do Llama 3.2 1B?
Inferência requer 3,14 GB de VRAM; fine-tuning precisa de 14,11 GB de VRAM.
Os modelos Llama 3.2 1B são gratuitos?
Sim! A Novita AI oferece acesso gratuito aos modelos Llama 3.2 1B com integração de API fácil.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a GPU em nuvem acessível e confiável para construir e escalar.



