

Points clés
Aperçu du modèle : Llama 3.2 1B est un LLM multilingue léger développé par Meta, conçu pour une utilisation efficace sur les appareils mobiles et de périphérie.
Méthode d’entraînement : Utilise l’élagage structuré et la distillation des connaissances à partir de modèles plus grands.
Configuration matérielle requise : Nécessite 3,14 Go de VRAM pour l’inférence et 14,11 Go pour le fine-tuning.
Llama 3.2 1B est un modèle de langage étendu multilingue avancé créé par Meta, spécifiquement conçu pour un déploiement léger sur les appareils mobiles et de périphérie. Son architecture permet des performances robustes dans diverses tâches de traitement du langage naturel tout en maintenant une utilisation efficace des ressources.
Parrainez vos amis sur Novita AI et vous gagnerez chacun 10 $ de crédits API LLM – jusqu’à 500 $ de récompenses au total.
Pour soutenir la communauté des développeurs, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B sont actuellement disponibles gratuitement sur Novita AI.

Qu’est-ce que Llama 3.2 1B ?
Le modèle Llama 3.2 1B est un modèle de langage étendu multilingue et léger développé par Meta, conçu pour fonctionner efficacement sur les appareils mobiles et de périphérie tout en offrant de bonnes performances pour diverses tâches de traitement du langage naturel.

-
Taille du modèle : 1B
-
Open Source : Oui
-
Architecture : Transformer dense
-
Longueur de contexte : 128 000 tokens
-
Langues multilingues prises en charge :
- Officiellement prises en charge : anglais, allemand, français, italien, portugais, hindi, espagnol, thaï
- Collection élargie : Entraîné sur des langues supplémentaires au-delà des 8 listées.
-
Capacité multimodale :
- Entrée : Texte
- Sortie : Texte et code
-
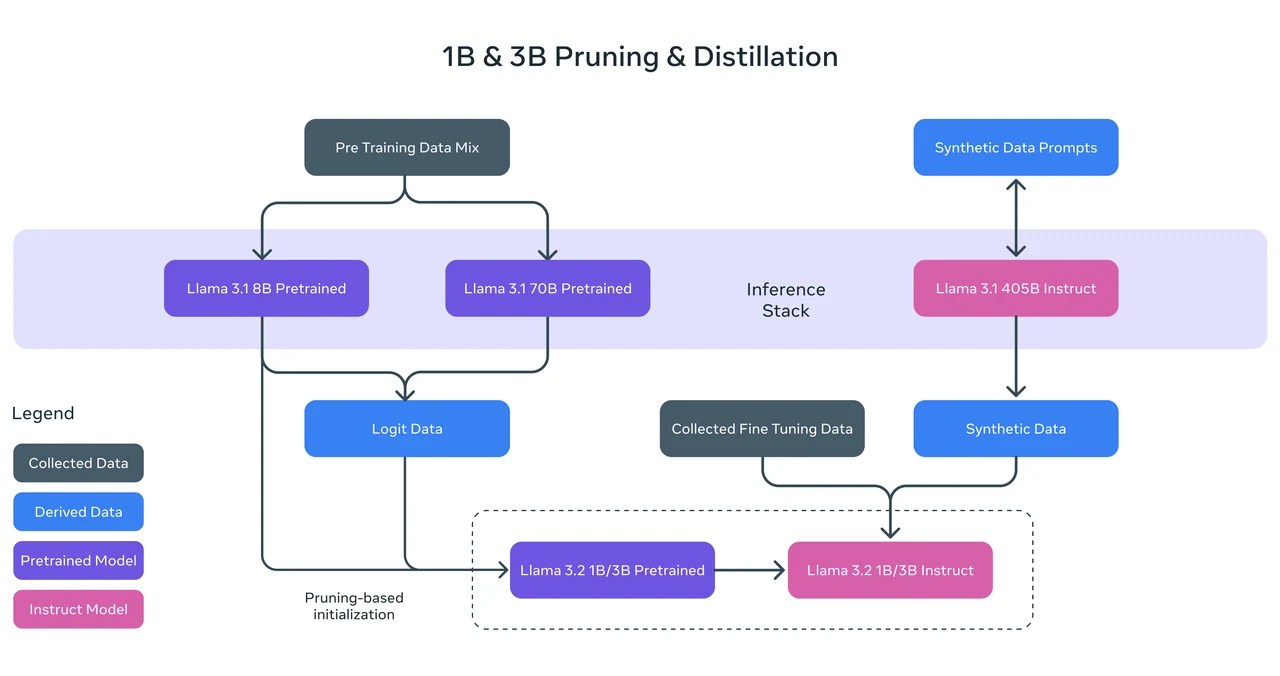
Méthode d’entraînement : Llama 3.2 1B a été entraîné à l’aide d’un élagage structuré à partir du modèle Llama 3.1 8B, en supprimant systématiquement des parties du réseau tout en ajustant les poids pour créer un modèle plus petit et efficace. Il a également utilisé la distillation des connaissances, où les logits des modèles Llama 3.1 8B et 70B ont été utilisés comme cibles au niveau des tokens lors du pré-entraînement. Cette approche a permis à Llama 3.2 1B de tirer parti des informations des modèles plus grands, améliorant ainsi ses performances après le processus d’élagage.
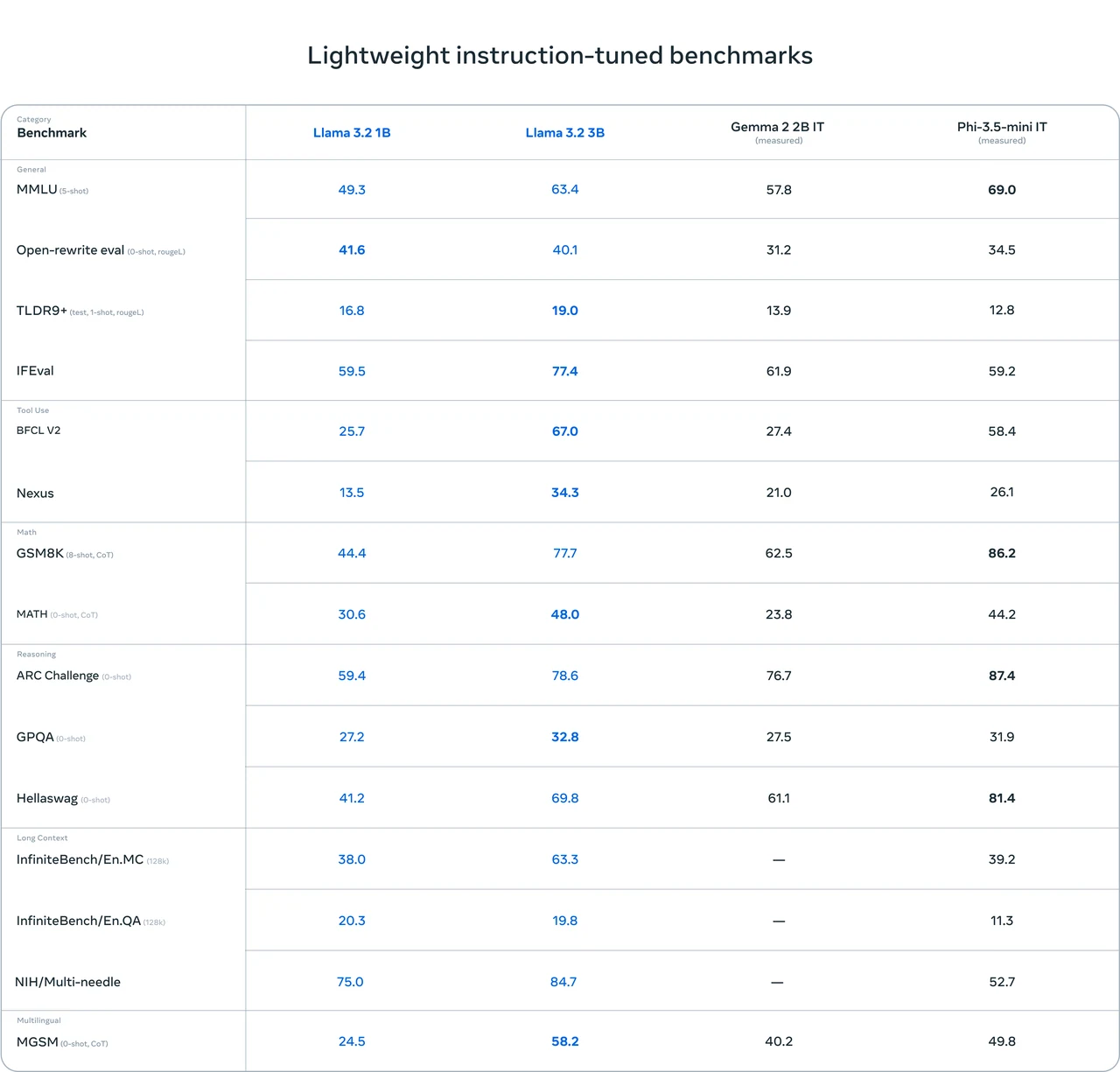
Benchmarks de Llama 3.2 1B
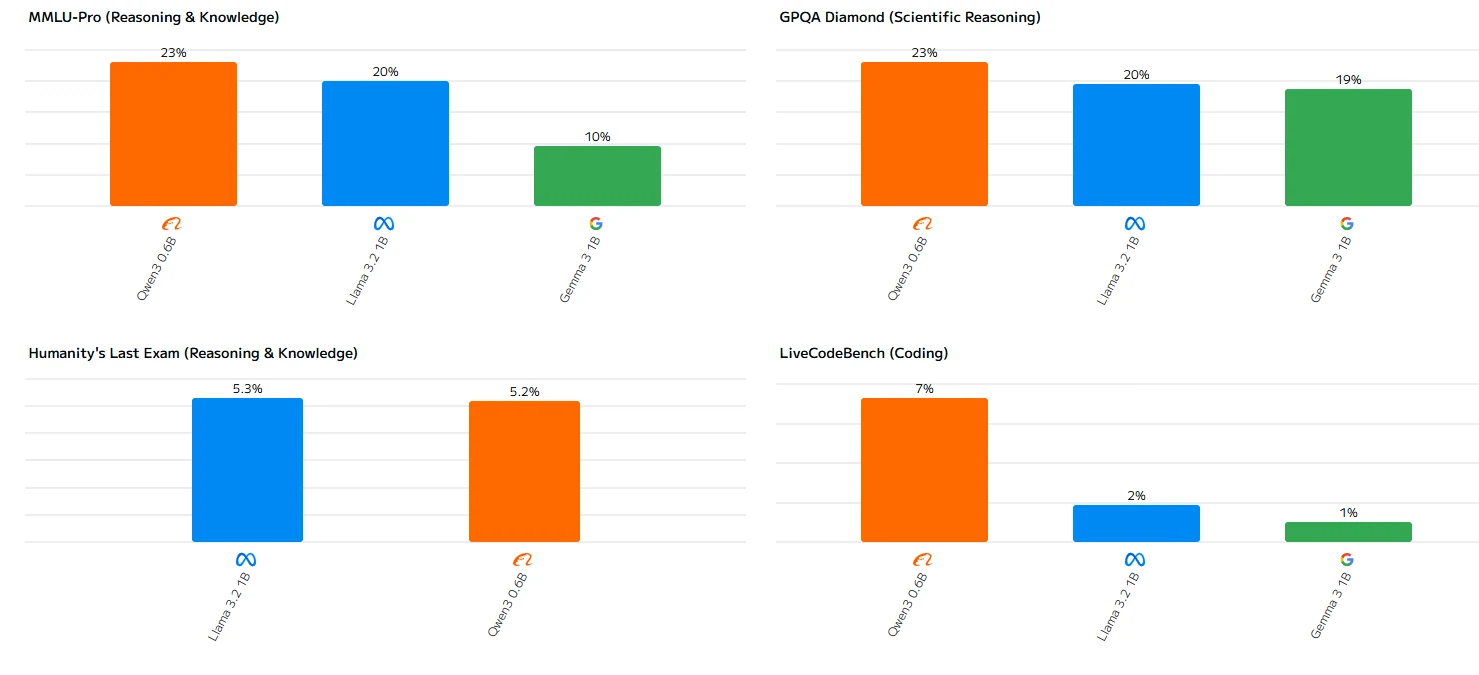
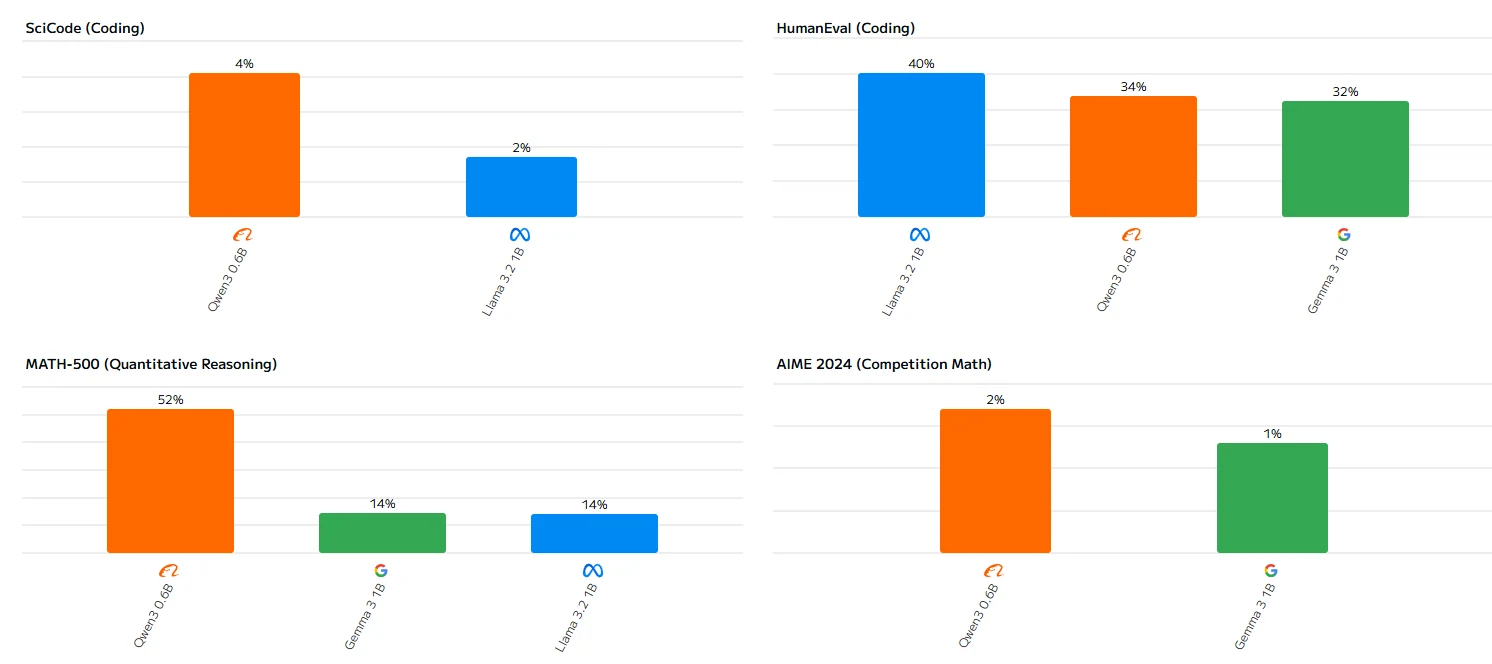
Configuration matérielle requise pour Llama 3.2 1B
Détails d’inférence
-
Modèle : Llama 3.2 1B
-
Quantification : FP16
-
VRAM requise (inférence) : 3,14 Go
-
GPU compatibles :
- RTX 3090 (12 Go)
- RTX 4060 (8 Go)
Détails du fine-tuning
- Modèle : Llama 3.2 1B
- Quantification : FP16
- VRAM requise (fine-tuning) : 14,11 Go
- GPU compatible : RTX 4090 (24 Go)
Meta a publié des versions quantifiées des modèles Llama 3.2 1B et 3B, réduisant considérablement leur taille et leurs besoins en calcul. Ces modèles quantifiés offrent une réduction allant jusqu’à 56 % de la taille du modèle et une diminution de 41 % de l’utilisation de la mémoire par rapport à leurs versions originales. Ces optimisations les rendent adaptés au déploiement sur des appareils mobiles, y compris les smartphones équipés de processeurs ARM.
Comment accéder à Llama 3.2 1B ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez Llama 3.2 1B maintenant !
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API Chat Completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En résumé, Llama 3.2 1B se distingue par sa capacité à offrir des capacités de traitement du langage performantes sur des appareils aux ressources limitées. Grâce à sa nature open source et à son architecture optimisée, il constitue un outil précieux pour les développeurs à la recherche de solutions IA efficaces.
Questions fréquentes
Qu’est-ce que Llama 3.2 1B ?
Un modèle de langage léger et multilingue conçu pour un déploiement efficace sur les appareils mobiles.
Quels sont les besoins matériels de Llama 3.2 1B ?
L’inférence nécessite 3,14 Go de VRAM ; le fine-tuning nécessite 14,11 Go de VRAM.
Les modèles Llama 3.2 1B sont-ils gratuits ?
Oui ! Novita AI offre un accès gratuit aux modèles Llama 3.2 1B avec une intégration API facile.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API facile, tout en fournissant un cloud GPU abordable et fiable pour la création et la montée en charge.



