

主なハイライト
モデル概要: Llama 3.2 1B は、エッジおよびモバイルデバイスでの効率的な利用を目的とした、Meta による軽量マルチリンガル LLM です。
トレーニング手法: 大規模モデルからの構造化プルーニングと知識蒸留を採用。
ハードウェア要件: 推論には 3.14 GB の VRAM、ファインチューニングには 14.11 GB の VRAM が必要です。
Llama 3.2 1B は Meta が開発した高度なマルチリンガル大規模言語モデルであり、モバイルおよびエッジデバイスでの軽量な展開に特化しています。そのアーキテクチャにより、リソースを効率的に使用しながら、さまざまな自然言語処理タスクで堅牢なパフォーマンスを発揮します。
友人を Novita AI に紹介すると、あなたと友人の両方に $10 の LLM API クレジットが付与されます。最大 $500 の報酬が得られます。
開発者コミュニティを支援するため、Llama 3.2 1B、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B は現在 Novita AI で無料でご利用いただけます。

Llama 3.2 1B とは?
Llama 3.2 1B モデルは Meta が開発した軽量マルチリンガル大規模言語モデルで、エッジおよびモバイルデバイス上で効率的に動作しながら、さまざまな自然言語処理タスクに強力なパフォーマンスを提供します。

-
モデルサイズ: 1B
-
オープンソース: はい
-
アーキテクチャ: Dense Transformer
-
コンテキスト長: 128,000 トークン
-
対応マルチリンガル言語:
- 正式対応: 英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語
- より広範な収集: 上記 8 言語以外の追加言語でもトレーニング済み。
-
マルチモーダル機能:
- 入力: テキスト
- 出力: テキストとコード
-
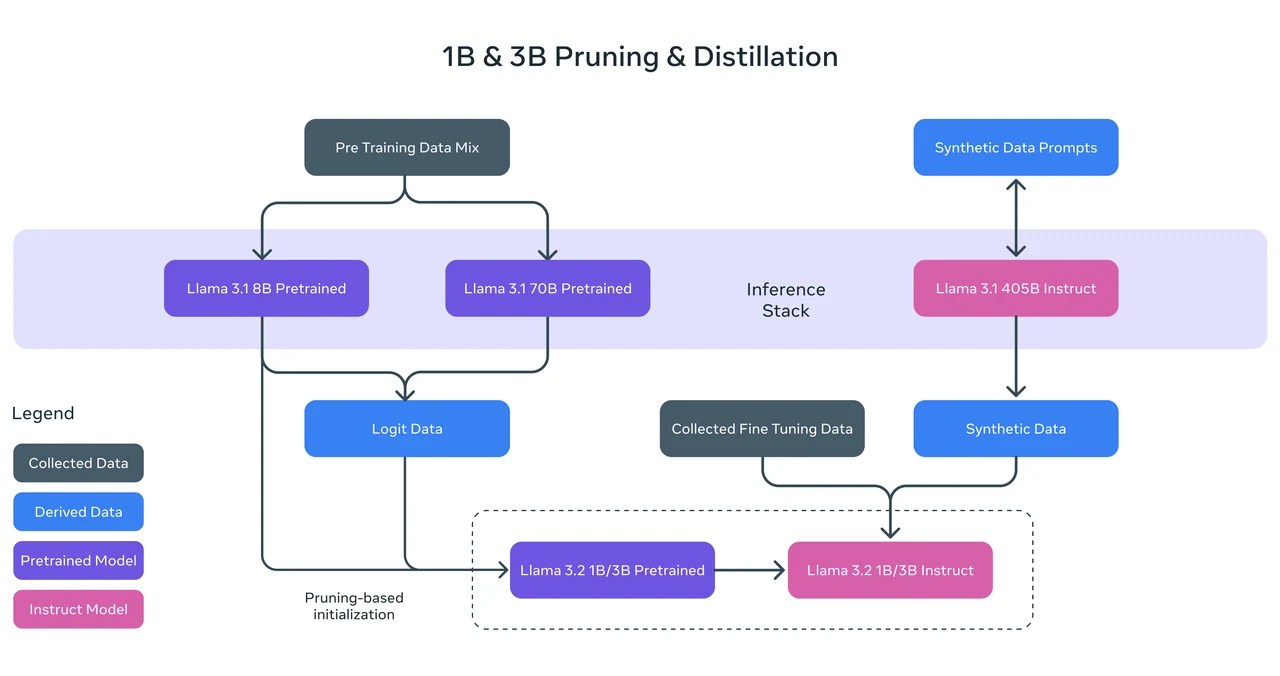
トレーニング手法: Llama 3.2 1B は、Llama 3.1 8B モデルからの構造化プルーニングを使用してトレーニングされ、ネットワークの一部を体系的に削除し、重みを調整してより小さく効率的なモデルを作成しました。また、知識蒸留を採用し、Llama 3.1 8B および 70B モデルからのロジットをプリトレーニング中のトークンレベルのターゲットとして使用しました。このアプローチにより、Llama 3.2 1B は大規模モデルからの知見を活用し、プルーニング後のパフォーマンスを向上させました。
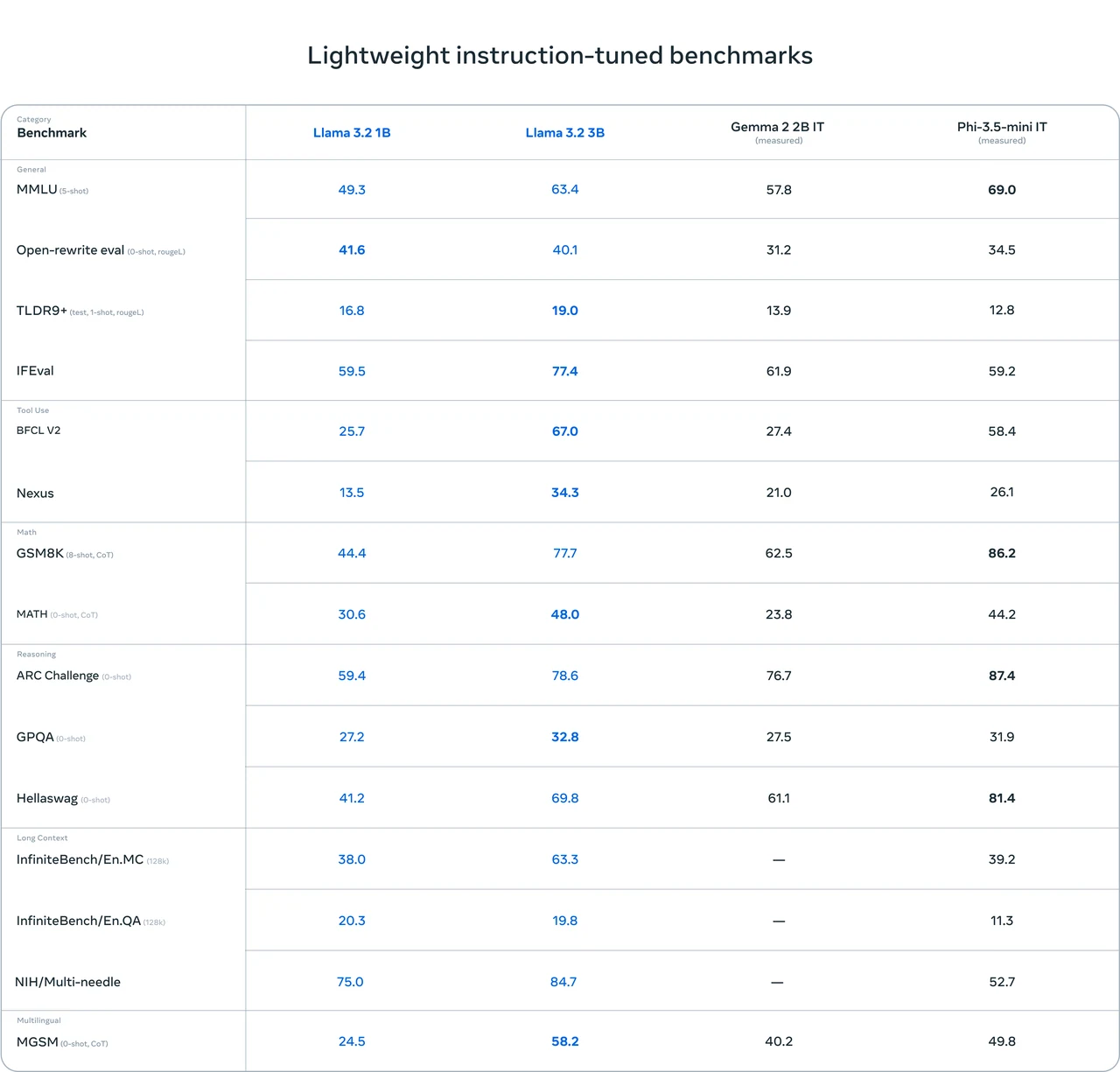
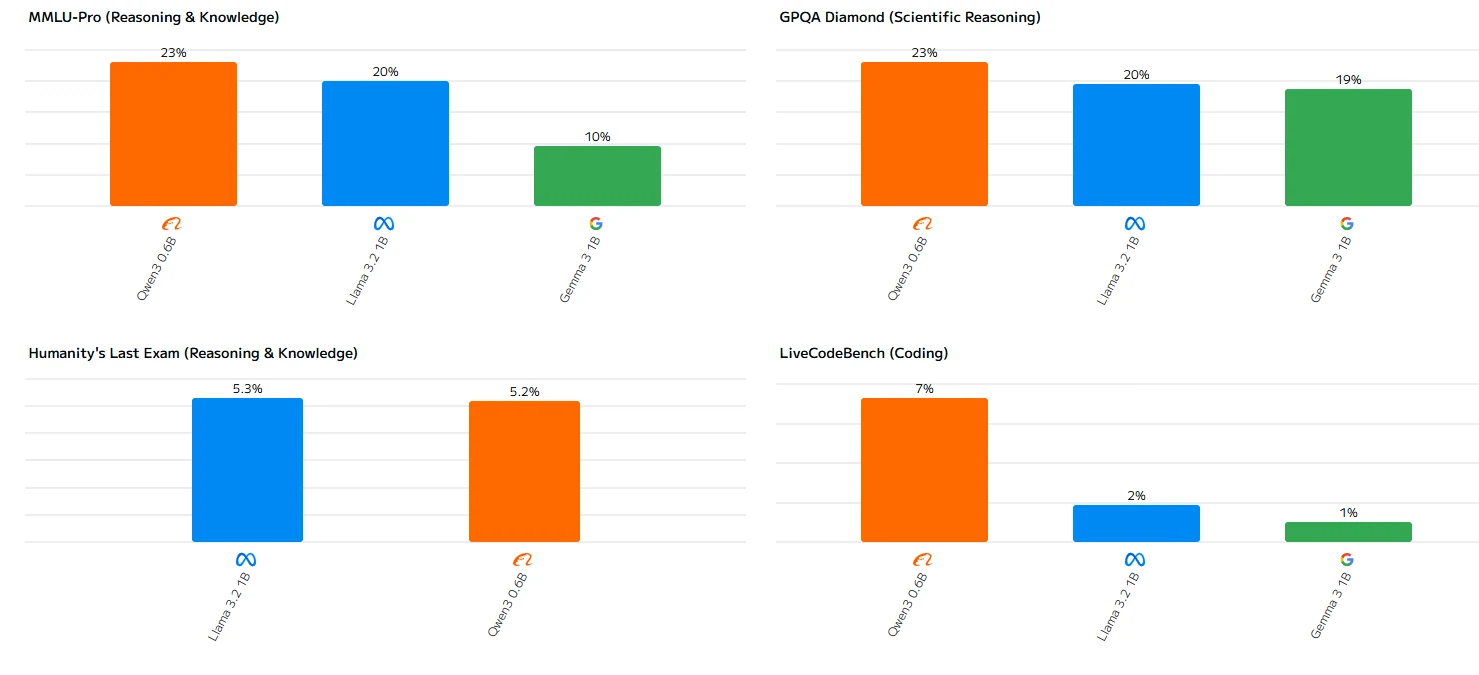
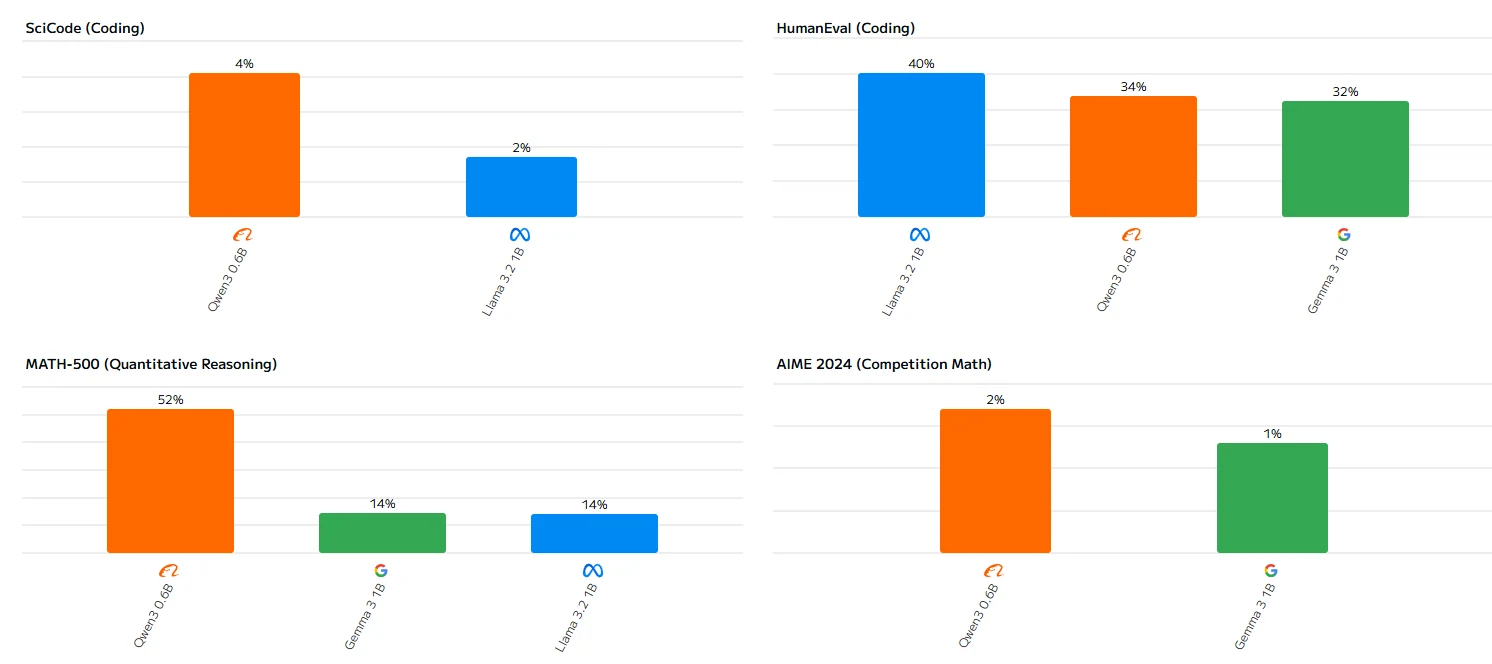
Llama 3.2 1B ベンチマーク
Llama 3.2 1B のハードウェア要件
推論の詳細
-
モデル: Llama 3.2 1B
-
量子化: FP16
-
必要 VRAM(推論): 3.14 GB
-
対応 GPU:
- RTX 3090(12 GB)
- RTX 4060(8 GB)
ファインチューニングの詳細
- モデル: Llama 3.2 1B
- 量子化: FP16
- 必要 VRAM(ファインチューニング): 14.11 GB
- 対応 GPU: RTX 4090(24 GB)
Meta は Llama 3.2 1B および 3B モデルの量子化版をリリースしており、サイズと計算要件を大幅に削減しています。これらの量子化モデルは、元のモデルと比較して最大 56% のモデルサイズ削減と 41% のメモリ使用量削減を実現しています。この最適化により、ARM ベースの CPU を搭載したスマートフォンを含むモバイルデバイスへの展開に適しています。
Llama 3.2 1B にアクセスする方法
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションからニーズに合ったモデルを選択します。

ステップ 3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに進み、画像のように API キーをコピーします。

ステップ 5: API をインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。
インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。以下は、Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
まとめると、Llama 3.2 1B は、リソースが制約されたデバイスでも強力な言語処理能力を発揮できる点で際立っています。オープンソースであり、最適化されたアーキテクチャにより、効率的な AI ソリューションを求める開発者にとって貴重なツールです。
よくある質問
Llama 3.2 1B とは何ですか?
モバイルデバイスへの効率的な展開向けに設計された、マルチリンガル軽量言語モデルです。
Llama 3.2 1B のハードウェア要件は?
推論には 3.14 GB の VRAM、ファインチューニングには 14.11 GB の VRAM が必要です。
Llama 3.2 1B モデルは無料で使用できますか?
はい! Novita AI では、簡単な API 統合により、Llama 3.2 1B モデルへの無料アクセスを提供しています。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、手頃で信頼性の高い GPU クラウドを提供してスケーリングを支援します。



