

Kimi K2.5를 탐구하는 개발자라면 곧 한 가지 핵심 문제에 직면하게 됩니다. 1T 파라미터 MoE 설계와 256K 컨텍스트 윈도우는 VRAM 요구 사항을 일반 소비자용 GPU 수준을 훨씬 넘어서게 만듭니다. 특히 긴 컨텍스트 + 동시성이 필요할 때 더욱 그렇습니다.
이 글에서는 실제로 VRAM을 소비하는 요소(가중치 vs KV 캐시)를 설명하고, FP16 / INT8 / INT4 간의 메모리 요구 사항을 비교하며, 실용적이고 저비용의 배포 경로(양자화, KV-캐시 압축, 오프로딩 전략, 클라우드 GPU, API 사용)를 제공합니다.
Kimi K2.5 VRAM 요구 사항
Kimi K2.5는 여러 GGUF 양자화 변형으로 출시되었으며, 각 변형은 메모리 사용량이 크게 다릅니다. 실제로 VRAM 요구 사항은 주로 선택한 양자화에 의해 결정되며, 긴 컨텍스트와 동시성은 KV 캐시를 통해 메모리 압력을 더욱 증가시킵니다.
아래 표는 Unsloth의 보고된 메모리 요구 사항과 Novita AI의 권장 인스턴스 설정을 기반으로 일반적으로 사용되는 GGUF 양자화 수준과 권장 GPU 구성을 요약한 것입니다.
| 양자화 | 메모리 요구 사항 | 권장 구성 |
| Q8_0 | 1093 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q6_K | 845 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q4_K_M | 623 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q4_0 | 583 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q3_K_M | 492 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q2_K | 376 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
양자화별 권장 GPU 구성
이 구성들은 원시 모델 풋프린트 위에 최소한이지만 실용적인 여유 공간을 제공하여 런타임 오버헤드와 제한된 KV 캐시 사용을 허용합니다. 더 높은 비트 양자화(예: Q8_0, Q6_K)는 일반적으로 H200급 GPU가 필요하며, Q4–Q2 변형은 A100 80GB 클러스터에서 비용 효율적으로 배포할 수 있습니다.
실제 배포에서는 컨텍스트 길이나 동시성을 늘리면 낮은 비트 GGUF 양자화를 사용하더라도 KV 캐시 메모리가 VRAM의 주요 소비자가 될 수 있습니다.
Kimi K2.5에 대규모 VRAM이 필요한 이유는 무엇인가요?
모델 개요:
| 사양 | 값 |
| 아키텍처 | Mixture of Experts (MoE) |
| 총 파라미터 수 | 1T |
| 전문가 수 | 총 384개, 토큰당 8개 활성 |
| 컨텍스트 길이 | 256K |
| 어텐션 메커니즘 | MLA (모델 사양 기준) |
Kimi K2.5의 메모리 압력은 두 가지 별도 승수에서 발생합니다. (1) 1T MoE의 가중치 저장/샤딩과 (2) 256K 컨텍스트에서 KV-캐시 증가입니다. 후자는 동시성을 확장하면 총 VRAM을 지배할 수 있습니다.
Mixture of Experts (MoE)
- MoE를 사용하면 "모든 토큰에서 모든 파라미터를 사용"하지는 않지만, 전문가 가중치를 효율적으로 저장하고 라우팅해야 하며, 실제로는 멀티 GPU 샤딩(텐서/전문가 병렬화)이 필요합니다.
256K 컨텍스트 = KV 캐시가 빠르게 확장됨
- KV 캐시는 시퀀스 길이와 동시성에 따라 증가합니다.
- 여러 개의 긴 요청을 동시에 실행하면 가중치가 INT4인 경우에도 KV가 빠르게 제한 요소가 됩니다.
양자화된 KV 캐시가 도움이 되지만 (올바른 백엔드가 필요함)
SGLang과 vLLM 모두 양자화된 KV 캐시(예: FP8)를 지원하여 KV 메모리 사용량을 줄입니다. 일반적으로 KV에 대해 약 2배 절감 효과가 있습니다.
Kimi K2.5를 최저 비용으로 로컬에서 실행하는 방법은?
Kimi K2.5는 극단적인 양자화 + 대규모 오프로딩이 있어야만 로컬에서 실행할 수 있습니다. 가장 저렴한 방법은 모델을 축소하고 대부분의 가중치를 VRAM 대신 RAM이나 디스크로 밀어내는 것입니다.
- Unsloth는 Kimi K2.5용 Dynamic ~1.8비트(1–2비트) GGUF를 제공하여 모델의 저장 공간을 ~600GB에서 ~240GB로 줄입니다.
- Unsloth의 실용적인 규칙: 디스크 + RAM + VRAM ≥ 240GB (오프로딩이 많을수록 속도가 느려짐).
Kimi K2.5는 공격적인 양자화와 광범위한 오프로딩이 있어야만 로컬에서 실행할 수 있습니다. 저비용 배포는 모델 풋프린트를 축소하고 대부분의 가중치를 GPU VRAM이 아닌 시스템 RAM이나 디스크로 밀어내는 데 의존합니다. 대규모 로컬 하드웨어를 관리하고 싶지 않은 개발자를 위해 Novita AI는 저비용 클라우드 GPU, 스팟 인스턴스 및 다양한 가격 등급을 제공하여 대규모 멀티 GPU 시스템을 구매하고 유지 관리하는 것보다 더 경제적인 대안을 제공합니다.
Novita AI에서 Kimi K2.5 배포 가이드
- 1단계: 계정 등록: **
[https://novita.ai/](https://novita.ai/user/register)**를 방문하여 Novita AI 계정을 생성/로그인합니다. GPUs 섹션으로 이동하여 사용 가능한 GPU 상품을 확인하고 배포를 시작합니다.
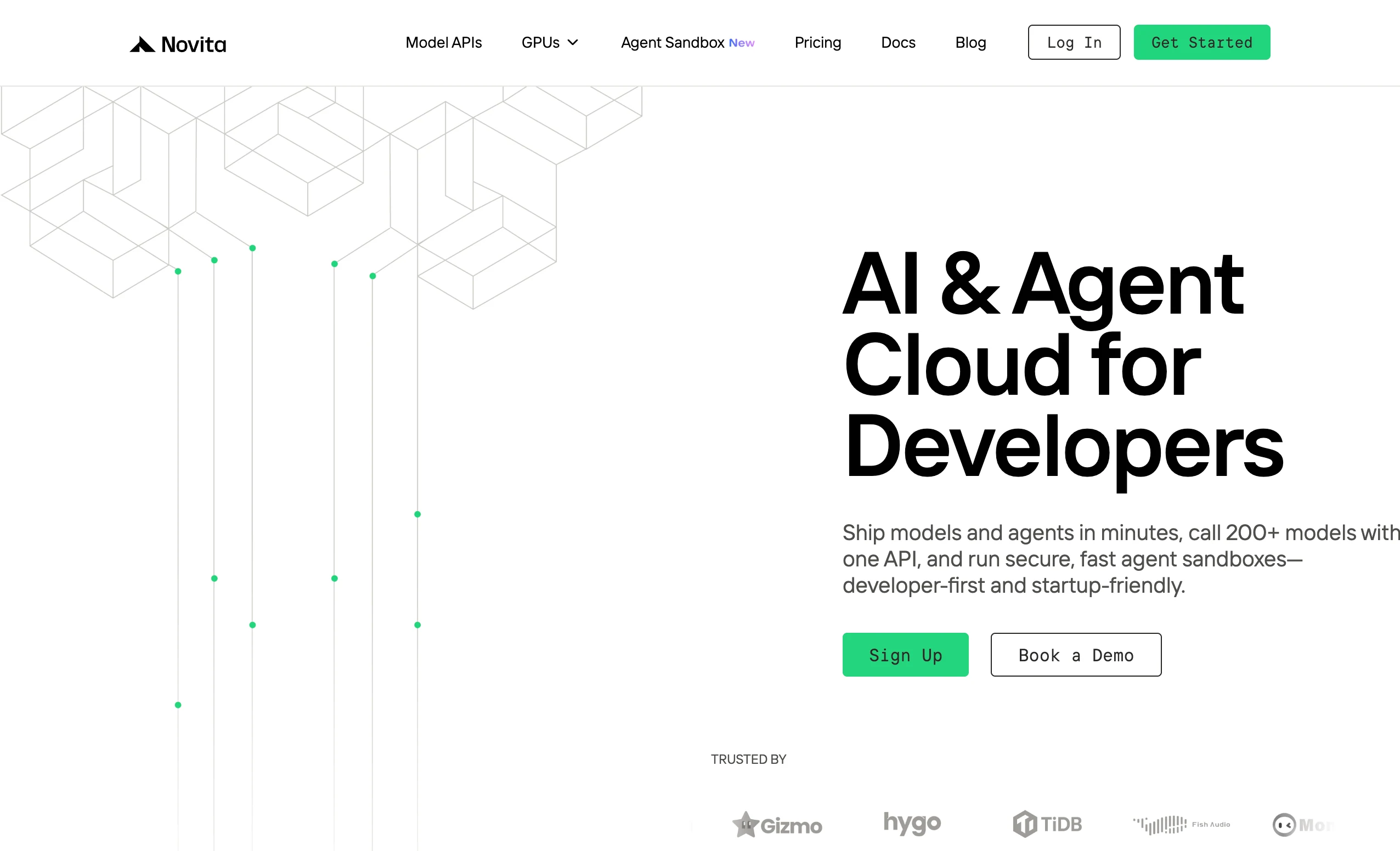
- 2단계: GPU 서버 및 템플릿 선택: 템플릿(PyTorch / CUDA)을 선택한 후 GPU 구성을 선택합니다.
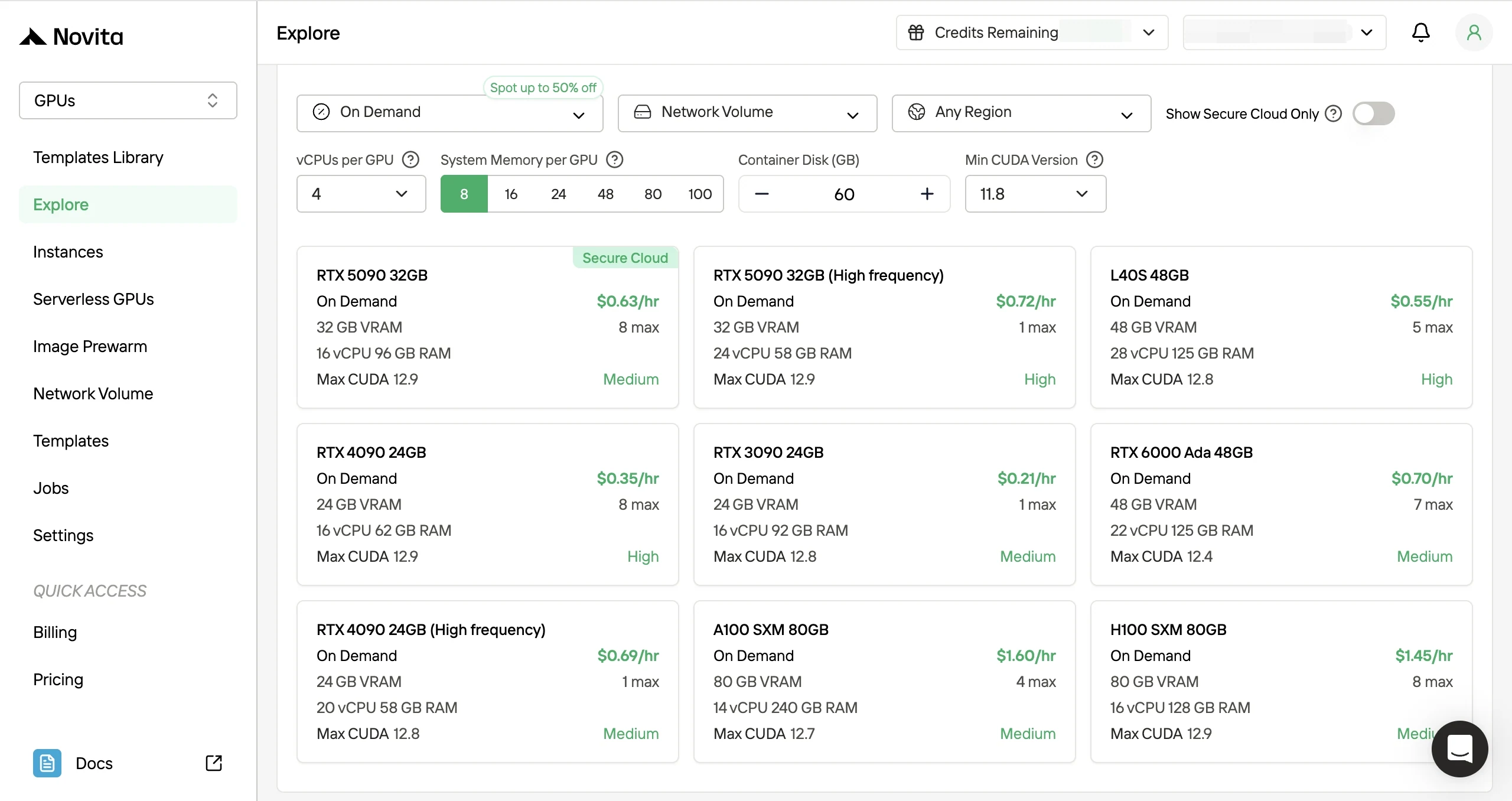
- 3단계: 배포 사용자 지정: 선호하는 운영 체제와 구성 옵션을 선택하여 환경을 사용자 지정하면 특정 AI 워크로드 및 개발 요구 사항에 최적의 성능을 보장할 수 있습니다.
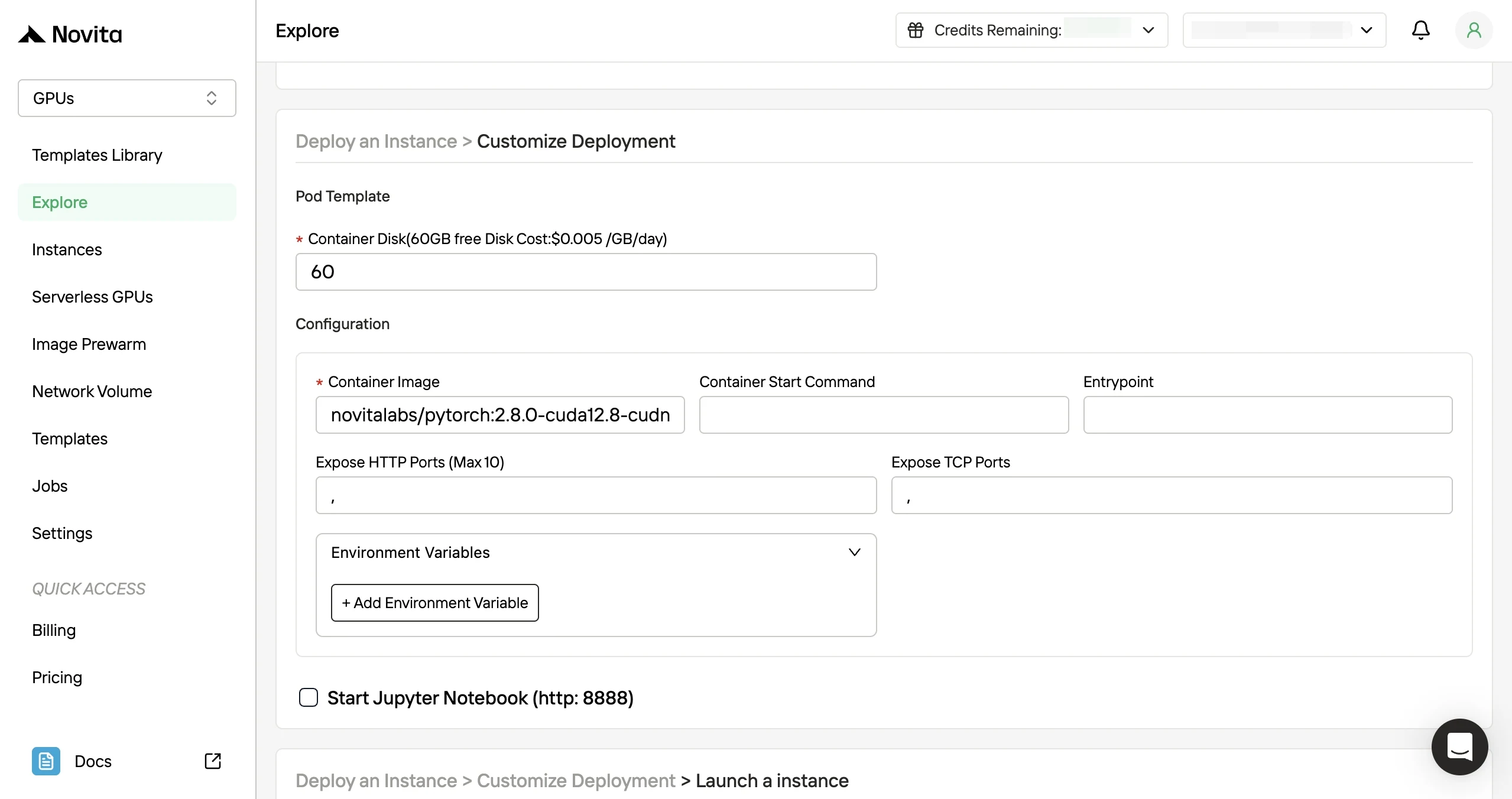
- 4단계: 인스턴스 시작: 인스턴스를 시작하고 서빙 스택을 배포합니다. 고성능 GPU 환경이 몇 분 안에 준비되므로 머신 러닝, 렌더링 또는 계산 프로젝트를 즉시 시작할 수 있습니다.
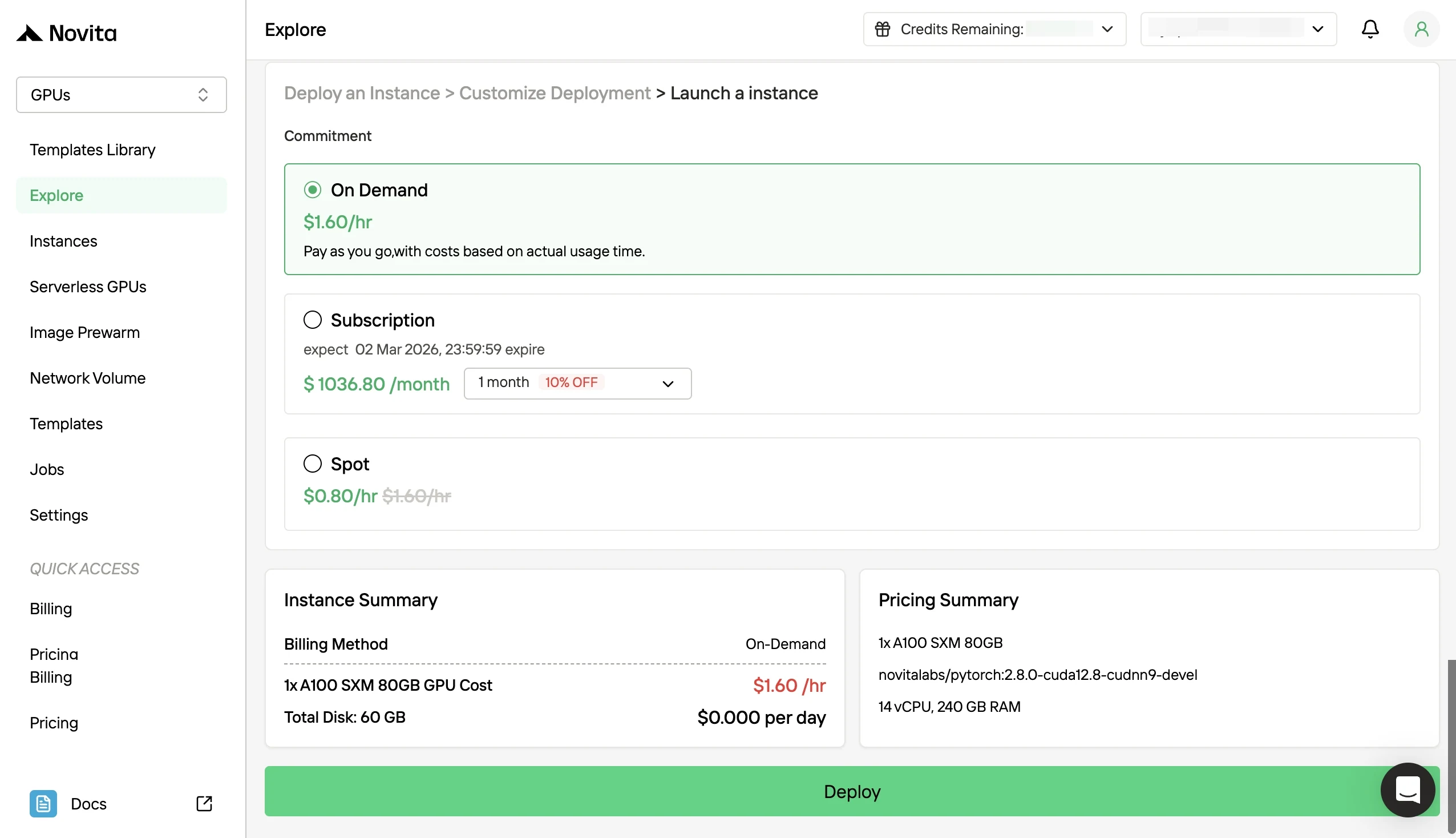
배포 시 Kimi K2.5의 메모리를 절약하는 방법은?
- 먼저 저비트 가중치 양자화 사용
자가 호스팅 배포의 경우 저비트 양자화는 필수입니다. GGUF 형식(예: Q4_K_M 또는 Q2_K)과 INT4 가중치 전용 양자화는 모델의 메모리 사용량을 크게 줄여 A100 또는 H200급 클러스터에서 멀티 GPU 배포를 가능하게 합니다. 이것은 모든 비용 효율적인 설정의 기초입니다.
- 긴 컨텍스트에 대해 양자화된 KV 캐시 활성화
vLLM 및 SGLang과 같은 추론 엔진은 긴 컨텍스트에서 KV 캐시가 GPU 메모리의 주요 소비자가 된다는 것을 명시적으로 문서화하고 있습니다. FP8 또는 FP4 KV 캐시를 활성화하면 메모리 사용량을 크게 줄여 동일한 VRAM 예산에서 더 많은 토큰이나 더 높은 동시성을 허용할 수 있습니다. 이 최적화는 64K–128K 컨텍스트를 넘어설 때 특히 중요합니다.
- 긴 컨텍스트 요청의 동시성 제한
KV 캐시 메모리는 컨텍스트 길이와 동시 시퀀스 수 모두에 따라 증가합니다. 일반적인 프로덕션 관행은 짧은 컨텍스트와 긴 컨텍스트 워크로드를 분리하고, 긴 컨텍스트 요청의 동시성을 제한하여 KV 캐시가 GPU 메모리를 소진하는 것을 방지하는 것입니다.
- VRAM이 병목인 경우 오프로딩 사용
매우 제한된 환경의 경우 CPU 또는 디스크 오프로딩을 통해 모델 가중치의 일부를 GPU 메모리 밖으로 이동시켜 GPU VRAM 사용량을 더욱 줄일 수 있습니다. 이 접근 방식은 더 낮은 하드웨어 요구 사항을 위해 처리량과 지연 시간을 맞바꾸며, 실험이나 지연 시간에 덜 민감한 워크로드에 가장 적합합니다.
- 컨텍스트 길이를 비용 제어 손잡이로 취급
Kimi K2.5는 최대 256K 컨텍스트를 지원하지만, 더 낮은 기본 컨텍스트(예: 8K–32K)를 설정하면 메모리 압력이 크게 줄어듭니다. 긴 컨텍스트는 실제로 필요한 워크로드에 대해서만 활성화해야 합니다.
Kimi K2.5를 사용하는 또 다른 효과적인 방법: API 사용
멀티 GPU 클러스터, 양자화 및 KV-캐시 튜닝을 관리하고 싶지 않다면 Kimi K2.5를 사용하는 가장 간단한 방법은 Novita AI의 서버리스 API를 이용하는 것입니다. 토큰당 비용을 지불하고 즉시 시작할 수 있습니다.
🎉Novita Kimi K2.5 API 가격:
- 입력: 100만 토큰당 $0.6
- 출력: 100만 토큰당 $3
| 파라미터 | 값 |
| 모델 ID | moonshotai/kimi-k2.5 |
| 컨텍스트 길이 | 262,144 토큰 |
| 최대 출력 | 262,144 토큰 |
| 입력 모달 | 텍스트, 이미지, 비디오 |
| 출력 모달 | 텍스트 |
| 주요 기능 | 추론, 구조화된 출력, 함수 호출 |
결론
Kimi K2.5의 배포 비용은 주로 양자화 선택과 긴 컨텍스트(최대 256K)에서의 KV-캐시 압력에 의해 결정됩니다. 완전한 제어와 예측 가능한 처리량을 원한다면 Novita AI GPU를 통해 올바른 멀티 GPU 설정에서 Kimi K2.5를 실행할 수 있습니다. 인프라 오버헤드 없이 가장 빠른 프로덕션 경로를 원한다면 Novita AI의 서버리스 API가 262K 컨텍스트와 간단한 종량제 가격을 제공합니다.
***Novita AI*는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 하고, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.
추천 자료
- Kimi K2.5, 이제 Novita AI에서: 비전, 코드 및 에이전트를 위한 멀티모달 AI
- Kimi K2.5 vs GLM-4.7: 어떤 에이전틱 LLM이 더 나은가?
- Novita AI로 Kimi K2.5를 OpenCode에 연결: 에이전틱 코딩 가이드
자주 묻는 질문
Kimi K2.5란 무엇인가요?
Kimi K2.5는 Moonshot AI의 주력 Mixture-of-Experts (MoE) 멀티모달 에이전틱 모델로, 256K 컨텍스트를 가지며 장기 컨텍스트 추론, 코딩 및 시각적 이해를 위해 설계되었습니다.
Kimi K2.5는 오픈 소스인가요?
네. Kimi K2.5는 2026년 1월 27일에 공식적으로 오픈 소스화되었으며 수정된 MIT 라이선스 하에 모델 가중치와 코드 모두 상업적 사용, 수정 및 재배포가 가능합니다(초대규모 상업적 사용에 대한 추가 조항 포함).
Kimi K2.5를 로컬에 배포할 수 있나요?
Kimi K2.5는 대규모 양자화와 적극적인 오프로딩을 통해서만 로컬에서 실행할 수 있습니다. 크기 때문에 대부분의 실용적인 배포는 클라우드 GPU 또는 API 액세스에 의존합니다.



