

探索 Kimi K2.5 的开发者很快会遇到一个核心问题:其 1T 参数的 MoE 架构 和 256K 上下文窗口 将 VRAM 需求推至远超消费级 GPU 的水平——尤其当您需要 长上下文 + 并发 时。
本文解释 实际消耗 VRAM 的因素(权重 vs KV 缓存),比较 FP16 / INT8 / INT4 下的内存需求,并提供 实用、低成本的部署路径——包括量化、KV 缓存压缩、卸载策略、云端 GPU 以及 API 使用。
Kimi K2.5 VRAM 需求
Kimi K2.5 发布了多种 GGUF 量化变体,每种的内存占用差异很大。实践中,VRAM 需求主要由所选量化决定,而长上下文和并发需求会通过 KV 缓存进一步增加内存压力。
下表总结了 常用 GGUF 量化级别 及其 推荐的 GPU 配置,基于 Unsloth 报告的内存需求和 Novita AI 建议的实例设置。
| 量化级别 | 内存需求 | 推荐配置 |
| Q8_0 | 1093 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q6_K | 845 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q4_K_M | 623 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q4_0 | 583 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q3_K_M | 492 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q2_K | 376 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
按量化推荐的 GPU 配置
这些配置在模型原始占用之外提供了 最小但实用的余量,以应对运行时开销和有限的 KV 缓存使用。比特率较高的量化(如 Q8_0 和 Q6_K)通常需要 H200 级 GPU,而 Q4–Q2 变体 可在 A100 80GB 集群 上经济高效地部署。
在实际部署中,增加上下文长度或并发量可能使 KV 缓存内存成为主导的 VRAM 消耗,即使在使用低比特 GGUF 量化时也是如此。
为什么 Kimi K2.5 需要巨大 VRAM?
模型概览:
| 规格 | 数值 |
| 架构 | 混合专家 (MoE) |
| 总参数量 | 1T |
| 专家数量 | 384 个专家,每个 token 激活 8 个 |
| 上下文长度 | 256K |
| 注意力机制 | MLA(根据模型规格) |
Kimi K2.5 的内存压力来自 两个独立的倍增因素:(1) 1T MoE 的权重存储/分片,以及 (2) 256K 上下文下的 KV 缓存增长,这会在您扩展并发时主导总 VRAM 占用。
混合专家 (MoE)
- 对于 MoE,并非“每个 token 使用所有参数”,但您仍然需要 高效地存储和路由专家权重,并且实践中需要 多 GPU 分片(张量/专家并行)。
256K 上下文 = KV 缓存快速增长
- KV 缓存随 序列长度 和 并发数 增长。
- 如果同时运行多个长请求,即使权重是 INT4,KV 也会迅速成为限制因素。
量化 KV 缓存也有帮助(但需要正确的后端)
SGLang 和 vLLM 都支持 量化 KV 缓存(例如 FP8),以减少 KV 内存占用——KV 通常可节省约 2 倍。
如何在本地以最低成本运行 Kimi K2.5?
Kimi K2.5 只能在本地通过 极度量化 + 大量卸载 运行。最便宜的方法是将模型缩小,并将大部分权重推至 RAM 或磁盘 而非 VRAM。
- Unsloth 为 Kimi K2.5 提供动态约 1.8 比特(1–2 比特)的 GGUF,将模型存储占用从 约 600GB 缩小至 约 240GB。
- Unsloth 的实用规则:磁盘 + RAM + VRAM ≥ 240GB(卸载越多 = 越慢)。
Kimi K2.5 只能在本地通过 激进量化和大量卸载 运行。低成本部署依赖于缩小模型足迹并将大部分权重移至 系统 RAM 或磁盘,而非全部保留在 GPU VRAM 中。对于不想管理大型本地硬件的开发者,Novita AI 提供低成本的云端 GPU、竞价实例和多种定价层级,是购买和维护大型多 GPU 系统更经济的替代方案。
在 Novita AI 上部署 Kimi K2.5 指南
- 第一步:注册账号:访问
[https://novita.ai/](https://novita.ai/user/register)创建/登录您的 Novita AI 账户。导航至 GPUs 部分查看可用的 GPU 产品并开始部署。
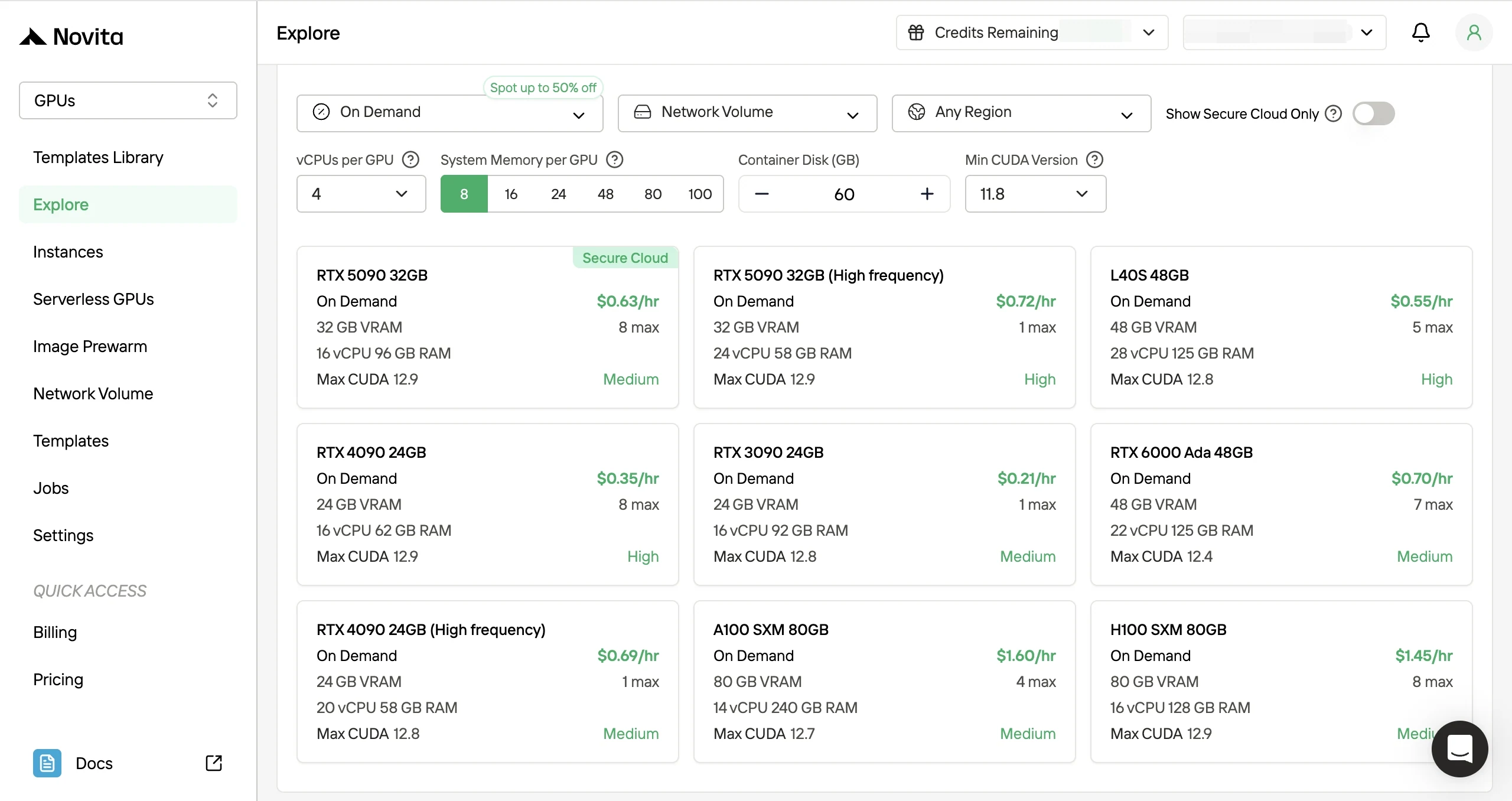
- 第二步:选择 GPU 服务器和模板:选择一个模板(PyTorch / CUDA),然后选择您的 GPU 配置。
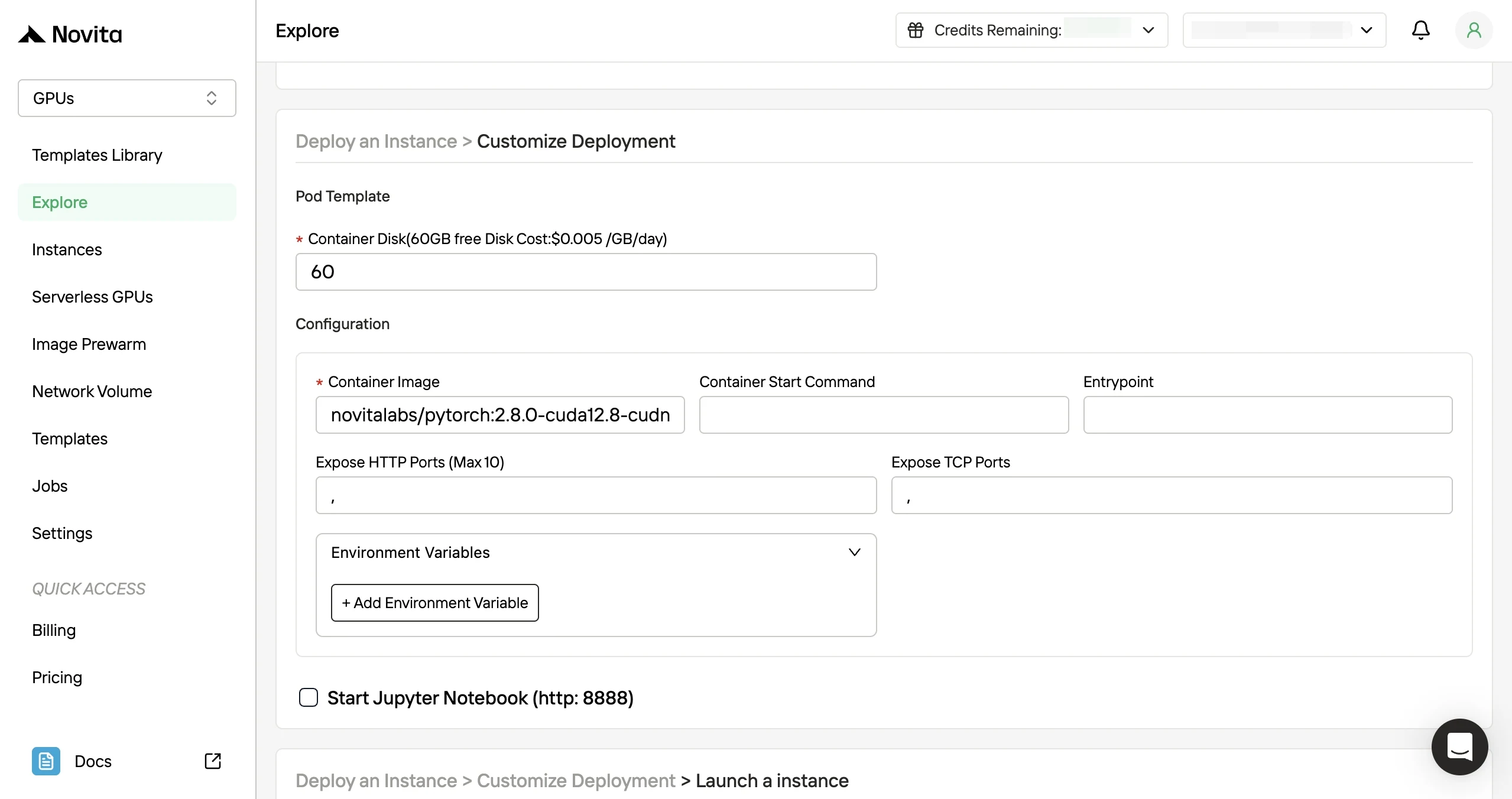
- 第三步:自定义部署:通过选择首选的操作系统和配置选项自定义环境,以确保针对您的特定 AI 工作负载和开发需求获得最佳性能。
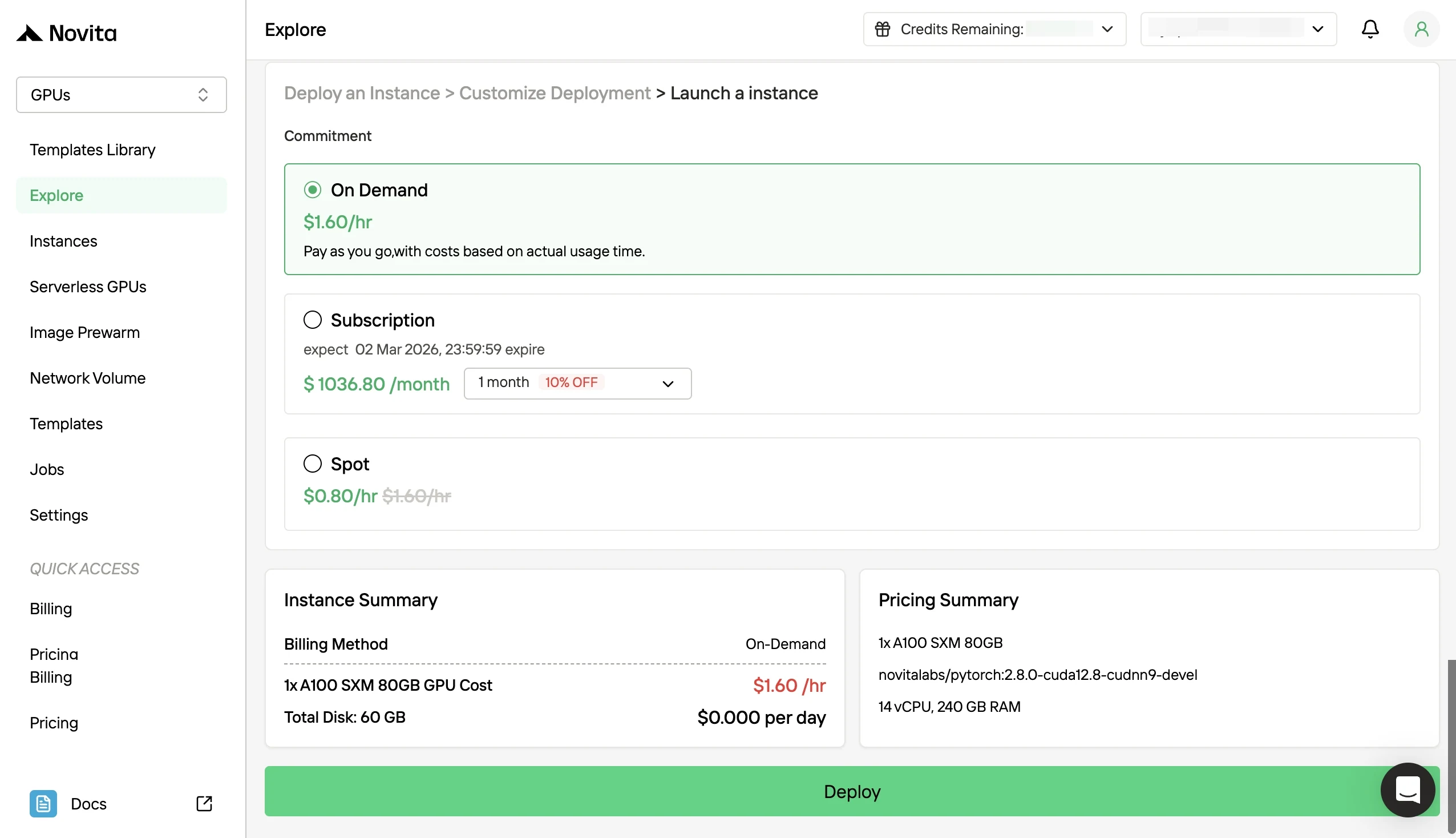
- 第四步:启动实例:启动实例并部署您的服务栈。您的高性能 GPU 环境将在几分钟内准备就绪,使您可以立即开始机器学习、渲染或计算项目。
如何在部署中节约 Kimi K2.5 的内存?
- 优先使用低比特权重量化
对于自托管部署,低比特量化是必须的。GGUF 格式(如 Q4_K_M 或 Q2_K)和仅权重量化 INT4 能显著减少模型的内存占用,使多 GPU 部署在 A100 或 H200 级集群上变得可行。这是任何成本效益型部署的基础。
- 对长上下文启用量化 KV 缓存
vLLM 和 SGLang 等推理引擎明确文档说明,在长上下文下,KV 缓存会成为 GPU 内存的主要消耗者。启用 FP8 或 FP4 KV 缓存 可大幅降低内存使用,允许在相同 VRAM 预算下处理更多 token 或更高并发。当上下文超过 64K–128K 时,此优化尤为重要。
- 限制长上下文请求的并发量
KV 缓存内存随 上下文长度 和 并发序列数 而增长。一个常见的生产实践是分离短上下文和长上下文工作负载,限制长上下文请求的并发量,以防 KV 缓存耗尽 GPU 内存。
- 当 VRAM 成为瓶颈时使用卸载
对于高度受限的环境,CPU 或磁盘卸载 可通过将部分模型权重移出 GPU 内存来进一步降低 GPU VRAM 使用。这种方法以吞吐量和延迟换取更低的硬件需求,最适合实验或非延迟敏感的工作负载。
- 将上下文长度作为成本控制旋钮
尽管 Kimi K2.5 支持 高达 256K 上下文,但设置较低的默认上下文(例如 8K–32K)可以显著降低内存压力。仅当工作负载确实需要时才启用长上下文。
另一种有效使用 Kimi K2.5 的方式:使用 API
如果您不想管理多 GPU 集群、量化和 KV 缓存调优,使用 Kimi K2.5 的最简单方式是通过 Novita AI 的无服务器 API。按 token 付费,可立即开始。
🎉Novita Kimi K2.5 API 定价:
- 输入:$0.6 / 1M token
- 输出:$3 / 1M token
| 参数 | 数值 |
| 模型 ID | moonshotai/kimi-k2.5 |
| 上下文长度 | 262,144 tokens |
| 最大输出 | 262,144 tokens |
| 输入模态 | text, image, video |
| 输出模态 | text |
| 关键特性 | 推理、结构化输出、函数调用 |
结论
Kimi K2.5 的部署成本主要由 量化选择 和 长上下文(高达 256K)下的 KV 缓存压力 决定。如果您希望完全控制并保证可预测的吞吐量,Novita AI GPU 让您在合适的多 GPU 设置上运行 Kimi K2.5。如果您希望以最快速的方式投入生产而无需处理基础设施开销,Novita AI 的无服务器 API 提供 262K 上下文和简单的按量付费定价。
Novita AI 是一个 AI 云平台,为开发者提供使用简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读
- Kimi K2.5 现已登陆 Novita AI:面向视觉、代码和 Agent 的多模态 AI
- Kimi K2.5 vs GLM-4.7:哪个 Agentic LLM 更胜一筹?
- 使用 Novita AI 将 Kimi K2.5 连接到 OpenCode:Agentic 编码指南
常见问题
什么是 Kimi K2.5?
Kimi K2.5 是 Moonshot AI 的旗舰混合专家 (MoE) 多模态、Agentic 模型,具有 256K 上下文,专为长上下文推理、编码和视觉理解而设计。
Kimi K2.5 是开源的吗?
是的。Kimi K2.5 已于 2026 年 1 月 27 日正式开源,采用 修改版 MIT 许可证,模型权重和代码 均可用于商业用途、修改和再分发(对超大规模商业使用有附加条款)。
Kimi K2.5 可以在本地部署吗?
Kimi K2.5 只能通过大量量化和激进卸载在本地运行。由于其规模,大多数实际部署依赖云端 GPU 或 API 访问。



