

Los desarrolladores que exploran Kimi K2.5 se topan rápidamente con un problema central: su diseño MoE de 1 billón de parámetros y su ventana de contexto de 256K elevan los requisitos de VRAM mucho más allá de las GPU de consumo, especialmente cuando se necesita contexto largo + concurrencia.
Este artículo explica qué consume realmente la VRAM (pesos vs. caché KV), compara las necesidades de memoria entre FP16 / INT8 / INT4 y proporciona rutas de implementación prácticas y de bajo coste, incluyendo cuantización, compresión de caché KV, estrategias de descarga, GPU en la nube y uso de API.
Requisitos de VRAM de Kimi K2.5
Kimi K2.5 se publica en múltiples variantes de cuantización GGUF, cada una con una huella de memoria muy diferente. En la práctica, los requisitos de VRAM están determinados principalmente por la cuantización elegida, mientras que el contexto largo y la concurrencia aumentan aún más la presión sobre la memoria mediante la caché KV.
La siguiente tabla resume los niveles de cuantización GGUF de uso común y sus configuraciones de GPU recomendadas, basadas en los requisitos de memoria reportados por Unsloth y las configuraciones de instancias sugeridas por Novita AI.
| Cuantización | Requisitos de memoria | Configuración recomendada |
| Q8_0 | 1093 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q6_K | 845 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q4_K_M | 623 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q4_0 | 583 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q3_K_M | 492 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q2_K | 376 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
Configuraciones de GPU recomendadas por cuantización
Estas configuraciones proporcionan un margen mínimo pero práctico por encima de la huella bruta del modelo, permitiendo gastos generales de ejecución y un uso limitado de la caché KV. Las cuantizaciones de bits más altos (como Q8_0 y Q6_K) generalmente requieren GPU de clase H200, mientras que las variantes Q4–Q2 pueden implementarse de forma rentable en clústeres A100 80GB.
En implementaciones reales, aumentar la longitud del contexto o la concurrencia puede hacer que la memoria de la caché KV se convierta en el consumidor dominante de VRAM, incluso cuando se utiliza cuantización GGUF de bits bajos.
¿Por qué Kimi K2.5 requiere una VRAM masiva?
Resumen del modelo:
| Especificación | Valor |
| Arquitectura | Mixture of Experts (MoE) |
| Parámetros totales | 1T |
| Expertos | 384 totales, 8 activos por token |
| Longitud de contexto | 256K |
| Mecanismo de atención | MLA (según las especificaciones del modelo) |
La presión de memoria de Kimi K2.5 proviene de dos multiplicadores separados: (1) el almacenamiento/fragmentación de pesos para un MoE de 1T, y (2) el crecimiento de la caché KV con contexto de 256K, que puede dominar la VRAM total una vez que se escala la concurrencia.
Mixture of Experts (MoE)
- Con MoE, no se “usan todos los parámetros en cada token”, pero aún es necesario almacenar y enrutar los pesos de los expertos de manera eficiente, y en la práctica se necesita fragmentación multi-GPU (paralelismo de tensor/experto).
Contexto de 256K = la caché KV escala rápido
- La caché KV crece con la longitud de secuencia y la concurrencia.
- Si se ejecutan múltiples solicitudes largas simultáneamente, la caché KV se convierte rápidamente en el factor limitante incluso cuando los pesos están en INT4.
La caché KV cuantizada ayuda (pero necesita el backend adecuado)
Tanto SGLang como vLLM admiten caché KV cuantizada (por ejemplo, FP8) para reducir la huella de memoria de la caché KV, a menudo cerca de un ahorro de ~2× para la caché KV.
¿Cómo ejecutar Kimi K2.5 localmente al menor coste?
Kimi K2.5 solo puede ejecutarse localmente con cuantización extrema + descarga pesada. El enfoque más barato es reducir el modelo y mover la mayoría de los pesos a RAM o disco en lugar de a VRAM.
- Unsloth proporciona un GGUF dinámico de ~1.8 bits (1-2 bits) para Kimi K2.5, reduciendo la huella de almacenamiento del modelo de ~600 GB a ~240 GB.
- La regla práctica de Unsloth: disco + RAM + VRAM ≥ 240GB (más descarga = más lento).
Kimi K2.5 solo puede ejecutarse localmente con cuantización agresiva y descarga extensiva. La implementación de bajo coste se basa en reducir la huella del modelo y mover la mayoría de los pesos a RAM del sistema o disco, en lugar de mantenerlos completamente en la VRAM de la GPU. Para los desarrolladores que prefieren no gestionar hardware local grande, Novita AI proporciona GPU en la nube de bajo coste, instancias puntuales y múltiples niveles de precios, ofreciendo una alternativa más económica que comprar y mantener grandes sistemas multi-GPU.
Guía de implementación de Kimi K2.5 en Novita AI
- Paso 1: Cree una cuenta: Visite
[https://novita.ai/](https://novita.ai/user/register)para crear/iniciar sesión en su cuenta de Novita AI. Navegue a la sección GPU para ver las ofertas de GPU disponibles y comenzar su implementación.
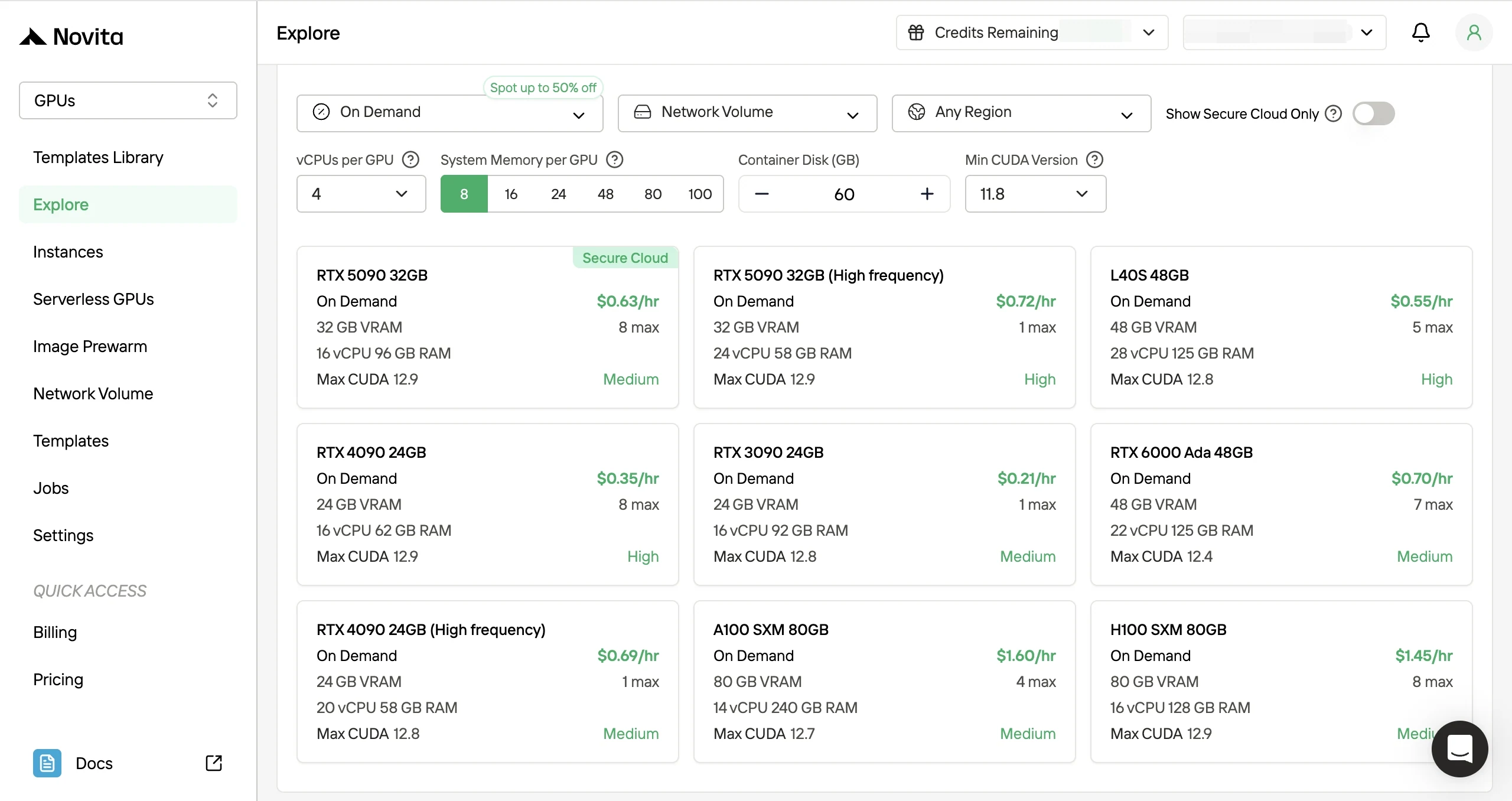
- Paso 2: Elija servidores GPU y plantillas: Seleccione una plantilla (PyTorch / CUDA), luego elija su configuración de GPU.
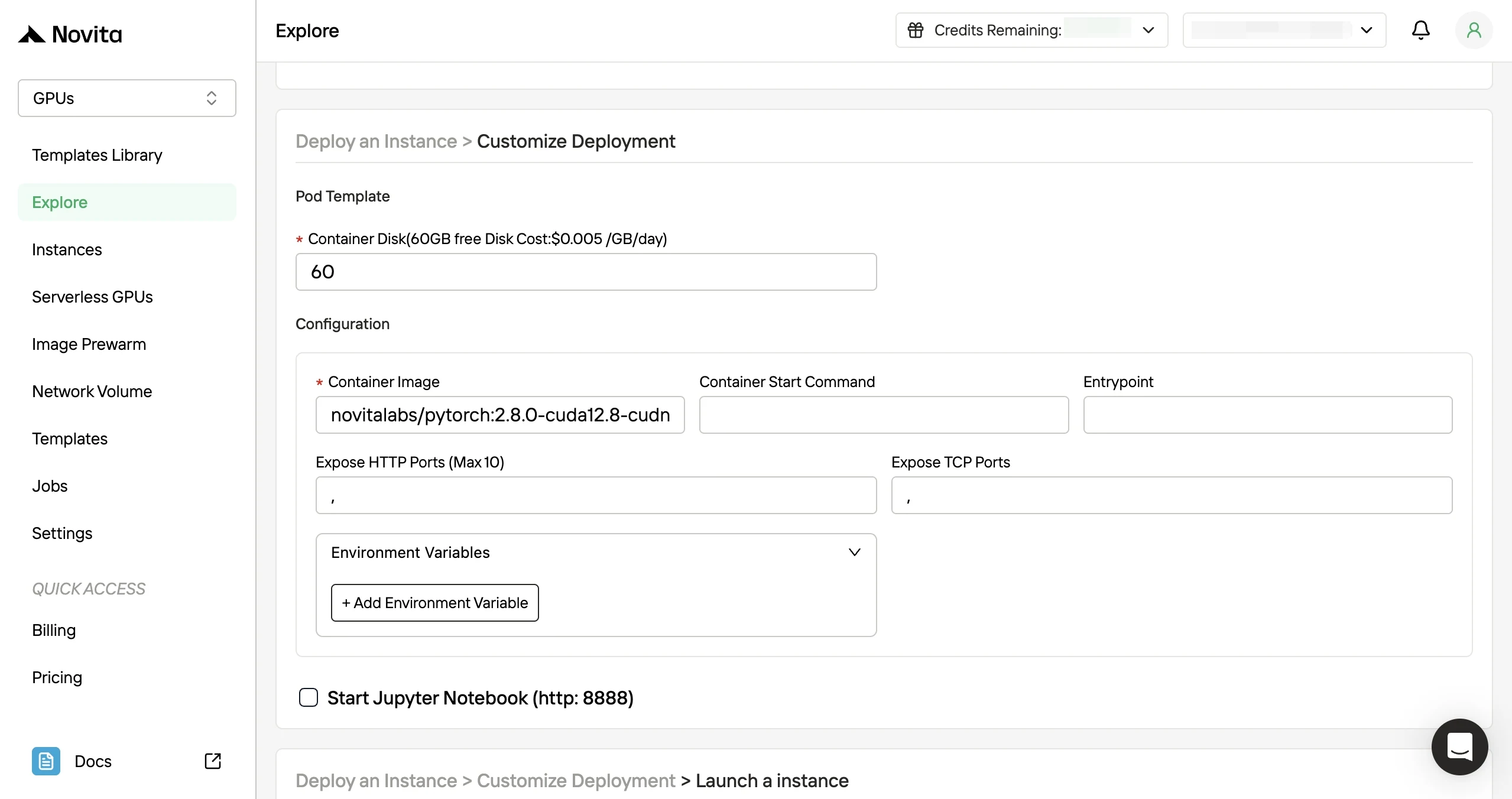
- Paso 3: Personalice su implementación: Personalice su entorno seleccionando su sistema operativo preferido y opciones de configuración para garantizar un rendimiento óptimo para sus cargas de trabajo de IA específicas y necesidades de desarrollo.
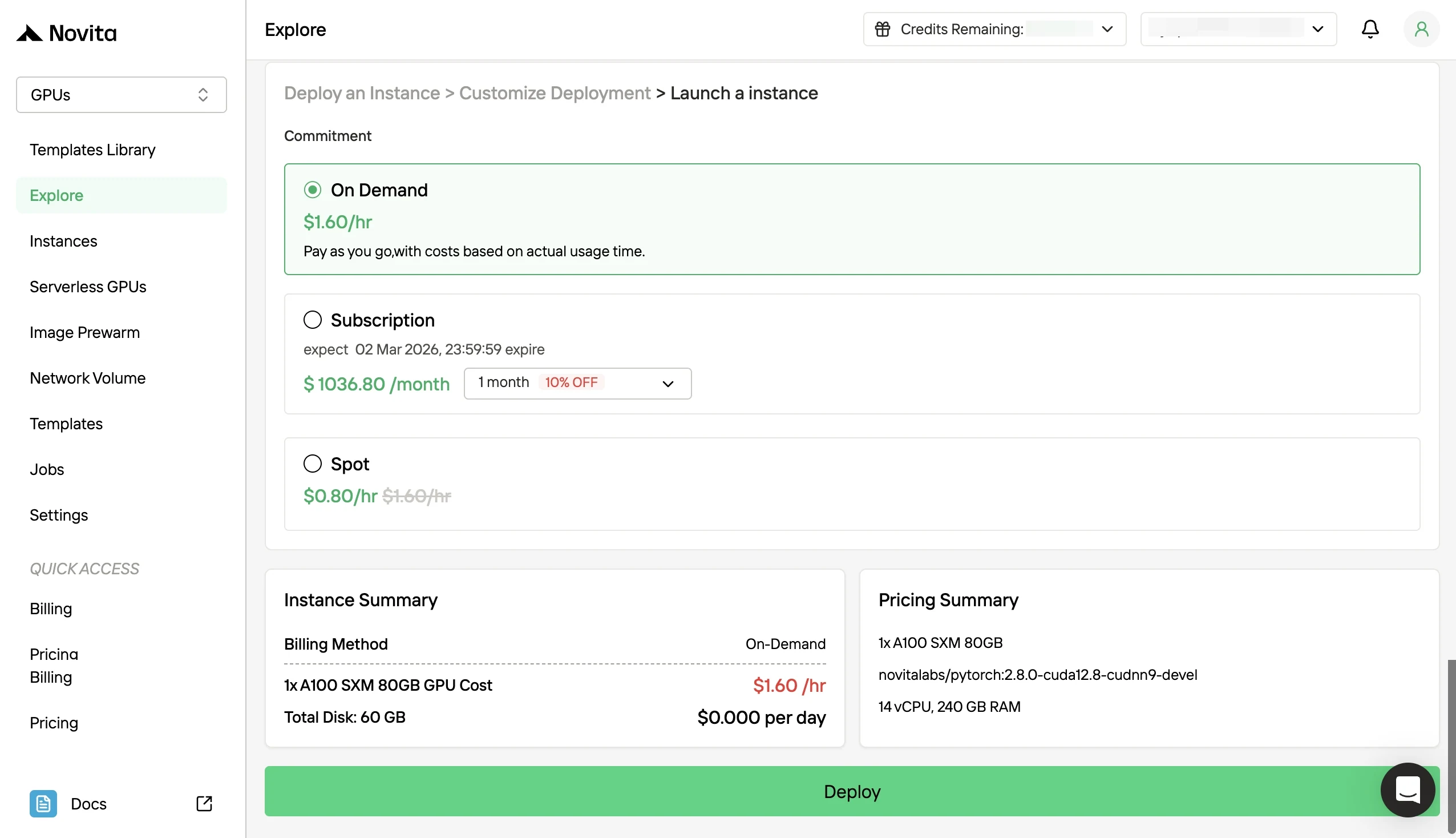
- Paso 4: Lance una instancia: Inicie la instancia e implemente su pila de servicio. Su entorno GPU de alto rendimiento estará listo en cuestión de minutos, permitiéndole comenzar inmediatamente sus proyectos de aprendizaje automático, renderizado o computacionales.
¿Cómo ahorrar memoria de Kimi K2.5 en la implementación?
- Use primero cuantización de pesos de bits bajos
Para implementaciones autogestionadas, la cuantización de bits bajos es obligatoria. Los formatos GGUF (como Q4_K_M o Q2_K) y la cuantización solo de pesos INT4 reducen significativamente la huella de memoria del modelo, haciendo viable la implementación multi-GPU en clústeres de clase A100 o H200. Esta es la base de cualquier configuración rentable.
- Habilite la caché KV cuantizada para contexto largo
Motores de inferencia como vLLM y SGLang documentan explícitamente que la caché KV se convierte en el consumidor dominante de memoria de GPU en contextos largos. Habilitar la caché KV FP8 o FP4 puede reducir sustancialmente el uso de memoria, permitiendo más tokens o mayor concurrencia bajo el mismo presupuesto de VRAM. Esta optimización es especialmente importante al superar los contextos de 64K–128K.
- Limite la concurrencia para solicitudes de contexto largo
La memoria de la caché KV crece tanto con la longitud del contexto como con el número de secuencias concurrentes. Una práctica común en producción es separar las cargas de trabajo de contexto corto y contexto largo, limitando la concurrencia para las solicitudes de contexto largo para evitar que la caché KV agote la memoria de la GPU.
- Use la descarga cuando la VRAM sea el cuello de botella
Para entornos muy limitados, la descarga a CPU o disco puede reducir aún más el uso de VRAM de la GPU al mover parte de los pesos del modelo fuera de la memoria de la GPU. Este enfoque intercambia rendimiento y latencia por menores requisitos de hardware y es más adecuado para experimentación o cargas de trabajo que no son críticas en latencia.
- Trate la longitud del contexto como un control de costes
Aunque Kimi K2.5 admite hasta 256K de contexto, establecer un contexto predeterminado más bajo (por ejemplo, 8K–32K) reduce drásticamente la presión sobre la memoria. El contexto largo debe habilitarse solo para cargas de trabajo que realmente lo requieran.
Otra forma efectiva de usar Kimi K2.5: Usando la API
Si no desea gestionar clústeres multi-GPU, cuantización y ajuste de caché KV, la forma más sencilla de usar Kimi K2.5 es a través de la API sin servidor de Novita AI. Paga por token y puede comenzar de inmediato.
🎉Precios de la API de Novita Kimi K2.5:
- Entrada: $0.6 / 1M tokens
- Salida: $3 / 1M tokens
| Parámetro | Valor |
| ID del modelo | moonshotai/kimi-k2.5 |
| Longitud de contexto | 262,144 tokens |
| Salida máxima | 262,144 tokens |
| Modalidades de entrada | texto, imagen, video |
| Modalidad de salida | texto |
| Características clave | Razonamiento, Salida estructurada, Llamada a funciones |
Conclusión
El coste de implementación de Kimi K2.5 está determinado principalmente por la elección de cuantización y la presión de la caché KV en contexto largo (hasta 256K). Si desea control total y rendimiento predecible, la GPU de Novita AI le permite ejecutar Kimi K2.5 en la configuración multi-GPU adecuada. Si desea la ruta más rápida hacia producción sin gastos generales de infraestructura, la API sin servidor de Novita AI proporciona contexto de 262K con precios simples de pago por uso.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona GPU en la nube asequibles y fiables para construir y escalar.
Lectura recomendada
- Kimi K2.5 Ahora en Novita AI: IA multimodal para visión, código y agente
- Kimi K2.5 vs GLM-4.7: ¿Qué LLM agentico es mejor?
- Conecte Kimi K2.5 a OpenCode con Novita AI: Una guía de codificación agentica
Preguntas frecuentes
¿Qué es Kimi K2.5?
Kimi K2.5 es el modelo insignia multimodal y agentico de Moonshot AI basado en Mixture-of-Experts (MoE) con contexto de 256K, diseñado para razonamiento de contexto largo, codificación y comprensión visual.
¿Es Kimi K2.5 de código abierto?
Sí. Kimi K2.5 se lanzó como código abierto oficialmente el 27 de enero de 2026 bajo una Licencia MIT Modificada, con tanto los pesos del modelo como el código disponibles para uso comercial, modificación y redistribución (con una cláusula adicional para uso comercial a hiperescala).
¿Se puede implementar Kimi K2.5 localmente?
Kimi K2.5 solo puede ejecutarse localmente con cuantización pesada y descarga agresiva. Debido a su tamaño, la mayoría de las implementaciones prácticas dependen de GPU en la nube o acceso a API.



