

Desenvolvedores que exploram o Kimi K2.5 encontram rapidamente um problema central: seu design MoE de 1T de parâmetros e janela de contexto de 256K elevam os requisitos de VRAM muito além das GPUs de consumo – especialmente quando você precisa de contexto longo + concorrência.
Este artigo explica o que realmente consome VRAM (pesos vs. cache KV), compara necessidades de memória entre FP16 / INT8 / INT4 e fornece caminhos de implantação práticos e de baixo custo – incluindo quantização, compressão de cache KV, estratégias de offloading, GPUs de nuvem e uso de API.
Experimente o Kimi K2.5 Agora!
Requisitos de VRAM do Kimi K2.5
O Kimi K2.5 é lançado em múltiplas variantes de quantização GGUF, cada uma com uma pegada de memória muito diferente. Na prática, os requisitos de VRAM são determinados principalmente pela quantização escolhida, enquanto contexto longo e concorrência aumentam ainda mais a pressão de memória via cache KV.
A tabela abaixo resume níveis de quantização GGUF comumente usados e suas configurações de GPU recomendadas, com base nos requisitos de memória relatados pela Unsloth e nas configurações de instância sugeridas pela Novita AI.
| Quantização | Requisitos de Memória | Configuração Recomendada |
| Q8_0 | 1093 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q6_K | 845 GB | 8× NVIDIA H200 (1128 GB VRAM) |
| Q4_K_M | 623 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q4_0 | 583 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q3_K_M | 492 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
| Q2_K | 376 GB | 8× NVIDIA A100 80GB (640 GB VRAM) |
Configurações de GPU Recomendadas por Quantização
Essas configurações fornecem espaço mínimo, mas prático acima da pegada bruta do modelo, permitindo sobrecarga de tempo de execução e uso limitado de cache KV. Quantizações de bits mais altos (como Q8_0 e Q6_K) geralmente requerem GPUs da classe H200, enquanto as variantes Q4–Q2 podem ser implantadas de forma econômica em clusters A100 80GB.
Em implantações reais, aumentar o comprimento do contexto ou a concorrência pode fazer com que a memória do cache KV se torne o principal consumidor de VRAM, mesmo ao usar quantização GGUF de baixo bit.
Por que o Kimi K2.5 Requer VRAM Massiva?
Visão Geral do Modelo:
| Especificação | Valor |
| Arquitetura | Mixture of Experts (MoE) |
| Total de parâmetros | 1T |
| Especialistas | 384 no total, 8 ativos por token |
| Comprimento do contexto | 256K |
| Mecanismo de atenção | MLA (conforme especificações do modelo) |
A pressão de memória do Kimi K2.5 vem de dois multiplicadores separados: (1) armazenamento/divisão de pesos para um MoE de 1T, e (2) crescimento do cache KV em contexto de 256K, que pode dominar o VRAM total assim que você aumenta a concorrência.
Mixture of Experts (MoE)
- Com MoE, você não “usa todos os parâmetros a cada token”, mas ainda precisa armazenar e rotear os pesos dos especialistas de forma eficiente, e na prática você precisa divisão entre múltiplas GPUs (paralelismo de tensor/especialista).
256K Contexto = O cache KV escala rapidamente
- O cache KV cresce com o comprimento da sequência e a concorrência.
- Se você executar várias solicitações longas simultaneamente, o KV se torna rapidamente o fator limitante, mesmo quando os pesos são INT4.
Cache KV quantizado ajuda (mas precisa do backend correto)
Tanto o SGLang quanto o vLLM suportam cache KV quantizado (por exemplo, FP8) para reduzir a pegada de memória do KV – geralmente com economia de cerca de 2× para o KV.
Como Executar o Kimi K2.5 Localmente com o Menor Custo?
O Kimi K2.5 só pode ser executado localmente com quantização extrema + offloading pesado. A abordagem mais barata é reduzir o modelo e enviar a maior parte dos pesos para a RAM ou disco em vez da VRAM.
- A Unsloth fornece um GGUF dinâmico de ~1,8 bits (1–2 bits) para o Kimi K2.5, reduzindo a pegada de armazenamento do modelo de ~600GB para ~240GB.
- Regra prática da Unsloth: disco + RAM + VRAM ≥ 240GB (mais offloading = mais lento).
O Kimi K2.5 só pode ser executado localmente com quantização agressiva e offloading extensivo. A implantação de baixo custo depende de reduzir a pegada do modelo e enviar a maior parte dos pesos para a RAM do sistema ou disco, em vez de mantê-los inteiramente na VRAM da GPU. Para desenvolvedores que preferem não gerenciar hardware local grande, a Novita AI oferece GPUs de nuvem de baixo custo, instâncias spot e múltiplos níveis de preço, oferecendo uma alternativa mais econômica à compra e manutenção de grandes sistemas multi-GPU.
Guia de Implantação do Kimi K2.5 na Novita AI
- Passo 1: Crie uma conta: Acesse
[https://novita.ai/](https://novita.ai/user/register)para criar/ fazer login na sua conta Novita AI. Navegue até a seção GPUs para ver as ofertas de GPU disponíveis e iniciar sua implantação.
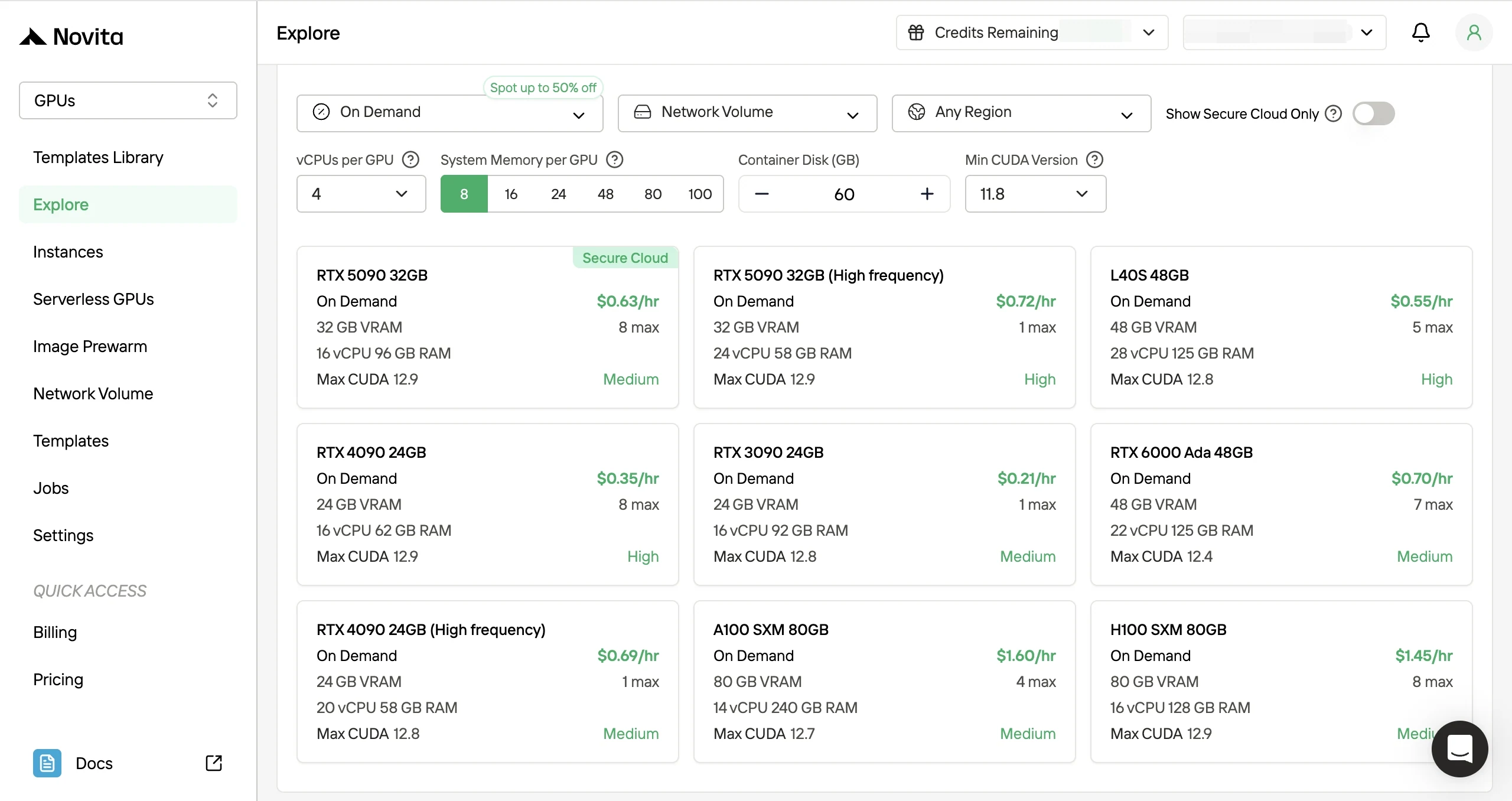
- Passo 2: Escolha servidores e modelos de GPU: Selecione um modelo (PyTorch / CUDA), depois escolha sua configuração de GPU.
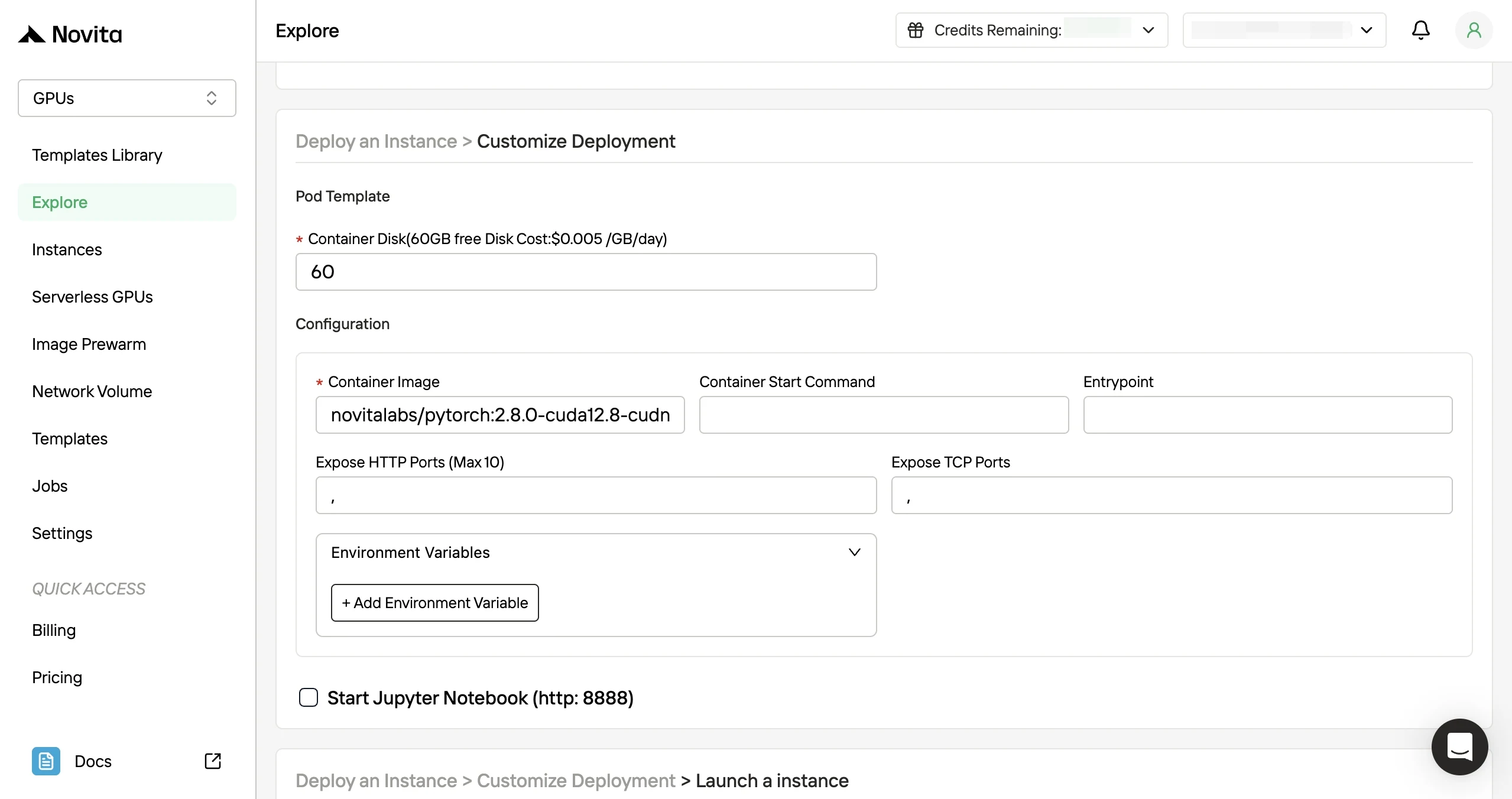
- Passo 3: Personalize Sua Implantação: Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho de IA específicas e necessidades de desenvolvimento.
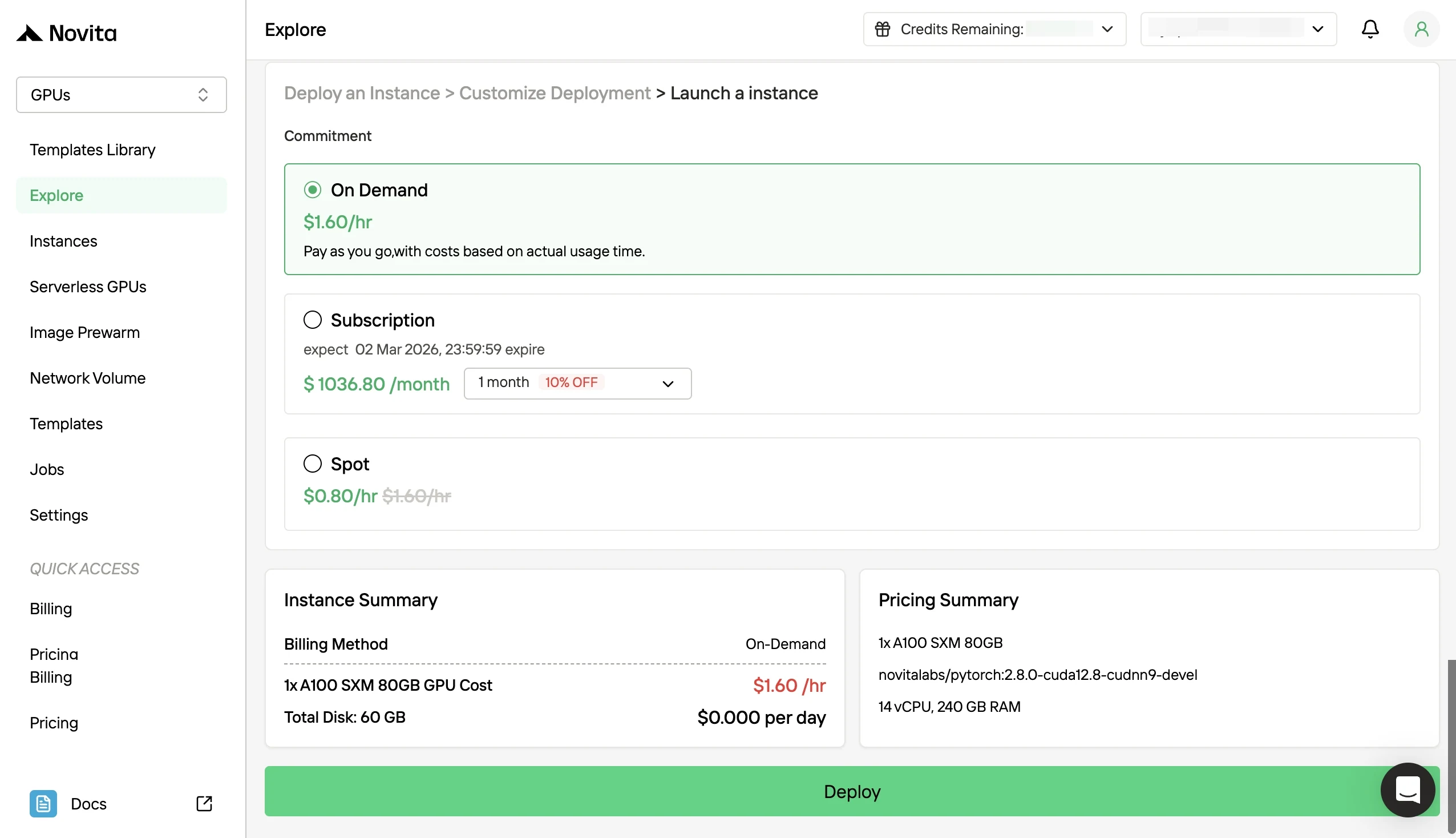
- Passo 4: Inicie uma instância Inicie a instância e implante sua pilha de serviço. Seu ambiente de GPU de alta performance estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computacionais.
Como Economizar Memória do Kimi K2.5 na Implantação?
- Use Primeiro Quantização de Pesos de Baixo Bit
Para implantações auto-hospedadas, a quantização de baixo bit é obrigatória. Formatos GGUF (como Q4_K_M ou Q2_K) e quantização de pesos apenas INT4 reduzem significativamente a pegada de memória do modelo, tornando a implantação multi-GPU viável em clusters da classe A100 ou H200. Essa é a base de qualquer configuração econômica.
- Habilite o Cache KV Quantizado para Contexto Longo
Motores de inferência como vLLM e SGLang documentam explicitamente que o cache KV se torna o principal consumidor de memória da GPU em contexto longo. Habilitar cache KV FP8 ou FP4 pode reduzir substancialmente o uso de memória, permitindo mais tokens ou maior concorrência com o mesmo orçamento de VRAM. Essa otimização é especialmente importante ao ultrapassar o contexto de 64K–128K.
- Limite a Concorrência para Solicitações de Contexto Longo
A memória do cache KV cresce com o comprimento do contexto e o número de sequências concorrentes. Uma prática comum de produção é separar cargas de trabalho de contexto curto e contexto longo, limitando a concorrência para solicitações de contexto longo para evitar que o cache KV esgote a memória da GPU.
- Use Offloading Quando a VRAM for o Gargalo
Para ambientes altamente restritos, o offloading para CPU ou disco pode reduzir ainda mais o uso de VRAM da GPU, movendo parte dos pesos do modelo para fora da memória da GPU. Essa abordagem troca throughput e latência por requisitos de hardware mais baixos e é mais adequada para experimentação ou cargas de trabalho não críticas de latência.
- Trate o Comprimento do Contexto como um Controle de Custo
Embora o Kimi K2.5 suporte até 256K de contexto, definir um contexto padrão mais baixo (por exemplo, 8K–32K) reduz drasticamente a pressão de memória. O contexto longo deve ser habilitado apenas para cargas de trabalho que realmente exigem isso.
Outra Maneira Eficaz de Usar o Kimi K2.5: Usando a API
Se você não quiser gerenciar clusters multi-GPU, quantização e ajuste de cache KV, a maneira mais simples de usar o Kimi K2.5 é por meio da API Serverless da Novita AI . Você paga por token e pode começar imediatamente.
🎉Preços da API Novita Kimi K2.5:
- Entrada**: $0,6 / 1M** tokens
- Saída: $3 / 1M tokens
| Parâmetro | Valor |
| ID do Modelo | moonshotai/kimi-k2.5 |
| Comprimento do contexto | 262.144 tokens |
| Saída máxima | 262.144 tokens |
| Modalidades de entrada | texto, imagem, vídeo |
| Modalidade de saída | texto |
| Recursos principais | Raciocínio, Saída estruturada, Chamada de funções |
Conclusão
O custo de implantação do Kimi K2.5 é determinado principalmente pela escolha de quantização e pela pressão do cache KV em contexto longo (até 256K). Se você quiser controle total e throughput previsível, a GPU da Novita AI permite executar o Kimi K2.5 na configuração multi-GPU correta. Se você quiser o caminho mais rápido para produção sem sobrecarga de infraestrutura, a API Serverless da Novita AI fornece contexto de 262K com preços simples de pagamento por uso.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construção e escalonamento.
Leituras Recomendadas
- Kimi K2.5 Agora na Novita AI: IA Multimodal para Visão, Código e Agente
- Kimi K2.5 vs GLM-4.7: Qual LLM Agêntico é Melhor?
- Conecte o Kimi K2.5 ao OpenCode com a Novita AI: Um Guia de Codificação Agêntica
Perguntas Frequentes
O que é o Kimi K2.5?
O Kimi K2.5 é o modelo principal da Moonshot AI, um modelo multimodal e agêntico Mixture-of-Experts (MoE) com contexto de 256K, projetado para raciocínio de contexto longo, codificação e compreensão visual.
O Kimi K2.5 é open source?
Sim. O Kimi K2.5 foi oficialmente lançado como open source em 27 de janeiro de 2026 sob a Licença MIT Modificada, com pesos do modelo e código disponíveis para uso comercial, modificação e redistribuição (com uma cláusula extra para uso comercial em hiperescala).
O Kimi K2.5 pode ser implantado localmente?
O Kimi K2.5 só pode ser executado localmente com quantização pesada e offloading agressivo. Devido ao seu tamanho, a maioria das implantações práticas depende de GPUs de nuvem ou acesso via API.



