

エージェントワークフローを構築する開発者は、常にジレンマに直面します。深い推論とアーキテクチャの完全性を優先すべきか、それとも厳格なトークンとコスト制限の下で、高速で信頼性の高いタスク実行を優先すべきか。GLM 4.7とMiniMax M2.1は、これら2つの対照的な最適化戦略を体現しています。本記事では、アーキテクチャ、ベンチマーク、推論ダイナミクス、実際のタスクの分岐にわたってエージェントの振る舞いを分析し、開発者が自らの運用制約とワークフロー目標にどのモデルがより適しているかを判断する手助けをします。
GLM 4.7とMiniMax M2.1のエージェント振る舞い
著者は、両モデルにCLIタスクランナーを構築する完全なエンドツーエンドのタスク(アーキテクチャ計画と実装フェーズを含む複数の機能を備えたもの)を実行させたところ、人間の介入なしに両モデルがすべての要件を完了したと述べています。これらの定性的な評価に基づき、以下の表に各モデルがエージェント作業の主要な次元でどのように機能するかをまとめます。
| 次元 | MiniMax M2.1 | GLM 4.7 | 根拠 |
|---|---|---|---|
| 指示への従順性とアラインメント | 9 | 7 | M2.1は厳密にアラインされており、スコープ逸脱に強い。GLMはスコープを拡大する傾向がある。 |
| 計画とアーキテクチャ推論 | 6 | 9 | GLMはシステム設計と長期的な構造に優れている。M2.1はより戦術的。 |
| 実行効率 | 9 | 6 | M2.1はより高速で、大幅にコストが低い。GLMは低速で高コスト。 |
| ワークフローの持続力 | 8 | 6 | M2.1は長く中断のないエージェントワークフローで良好に機能する。GLMはそのような環境で遅くなる。 |
| コード品質と保守性 | 7 | 9 | GLMはよりクリーンな抽象化と構造を生み出す。M2.1はシンプルさを重視するが、粗い場合がある。 |
| ドキュメントとコミュニケーション | 3 | 9 | M2.1はほとんどドキュメントを生成しない。GLMは充実したREADMEと内部ドキュメントを生成する。 |
| 推論の深さとルール一貫性 | 6 | 9 | GLMは複雑なロジックとルールが支配的なドメインでより強力。 |
| 積極性とスコープ管理 | 9 | 5 | M2.1はタスクに制限されたまま。GLMは過剰にエンジニアリングし、逸脱することが多い。 |
上記の比較から、GLM 4.7とMiniMax M2.1は非常に異なる目標で構築されていることがわかります。一方はより深い思考、明確な構造、長期的な計画に重点を置き、もう一方は速度、コスト、エージェントワークフローでの信頼性の高いタスク実行に重点を置いています。これらの目標が各モデルの振る舞いを形成し、同じタスクがなぜこれほど異なる結果をもたらすのかを説明しています。
以降のセクションでは、これらの違いがどこから来て、実際に何を意味するのかを、アーキテクチャ、ベンチマーク、効率性、デプロイ、実際の開発者のユースケースにわたって説明します。
GLM 4.7とMiniMax M2.1のアーキテクチャ
| 仕様 | GLM 4.7 | MiniMax M2.1 |
|---|---|---|
| アーキテクチャタイプ | MoE (アクティブ推論ルーティング 32Bアクティブ) | MoE (選択的活性化 10Bアクティブ) |
| コンテキストウィンドウ | 200,000トークン | 204,800トークン |
| 最大出力 | 128,000トークン | 131,072トークン |
GLM 4.7は、より大きなアクティブパラメータセットを使用して、深い推論、計画、構造化出力を重視しています。MiniMax M2.1は、スパース活性化に焦点を当て、計算とコストを削減しながら、強力な指示追従とエージェントワークフローを維持しています。
GLM 4.7とMiniMax M2.1のベンチマーク
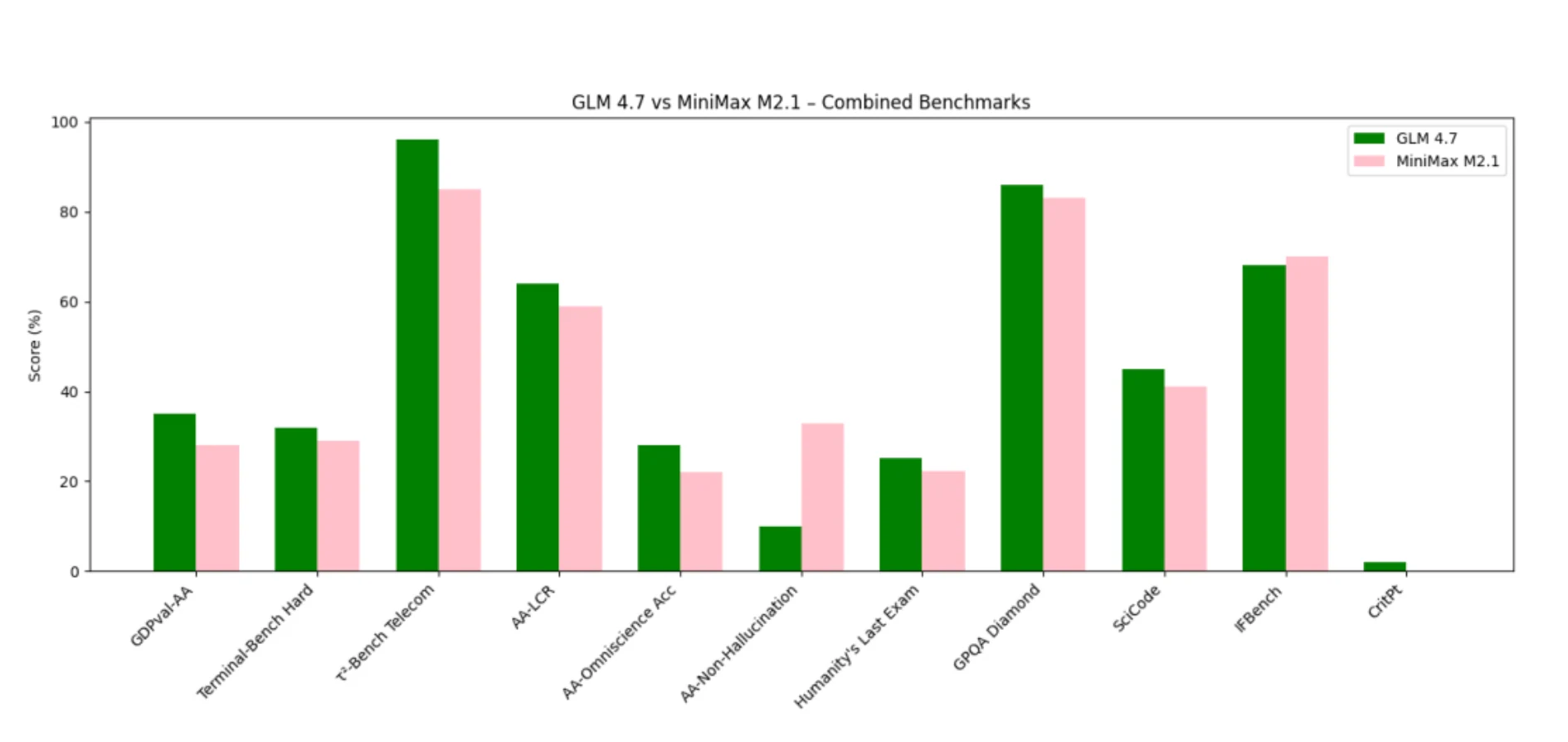
GLM 4.7は、深い推論、長いコンテキストの一貫性、構造化されたツール思考を評価するベンチマークで優位に立っています。
MiniMax M2.1は、指示の忠実性、エージェント実行、低ハルシネーション動作に関連するベンチマークで優れています。
GLM 4.7とMiniMax M2.1の推論速度
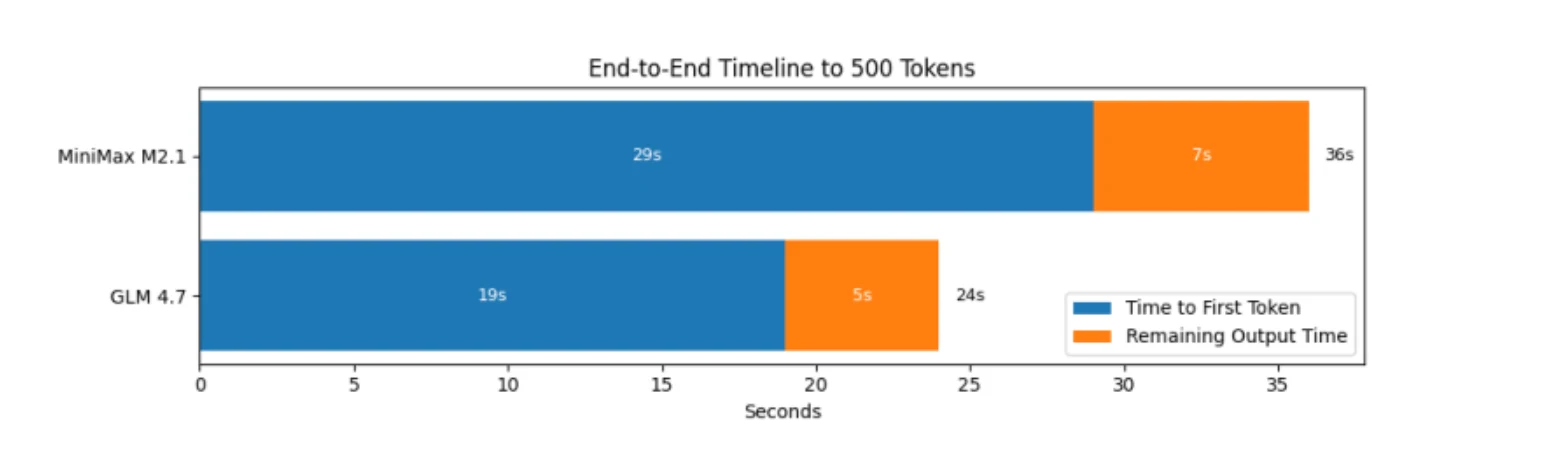
したがって、ベンチマークの観点では、GLM 4.7は純粋な推論メカニズムにおいてより効率的です。より早く開始し、より速く出力し、より早く終了します。
MiniMaxが「効率的」という評判を得ているのはワークフローレベルです。実際のエージェントループでは次のようになります:
- MiniMaxは長い内部推論フェーズに費やす時間が少ない傾向があります。
- ステップを短く直接的に保ちます。
- 多くのターンにわたって安定したペーシングを維持します。
これにより、生のスループットやエンドツーエンドのタイミングでGLMが有利な場合でも、反復的な開発において高速になります。
GLM 4.7とMiniMax M2.1で同一タスクが分岐する方法
プロンプト:プレビューとインタラクションのために、完全なコーヒー注文フローをシミュレートする、単一ファイルのH5デモ(実行可能な1つの
index.html)が欲しいです。ページには3つのビューステートが含まれている必要があります:3種類のコーヒー(アメリカーノ¥18、ラテ¥22、カプチーノ¥24)を「注文」ボタンとともに表示するメニュービュー、ユーザーがサイズ、温度、追加オプションをカスタマイズでき、リアルタイムで価格が更新され、「カートに追加」アクションで短いサウンドと確認が表示される商品詳細ビュー、選択したアイテムと合計価格を表示し、「注文する」ボタンで注文確認パネル(ランダムな注文IDと4桁の受け取りコードを生成)を表示するカートビュー。すべてのCSSは<style>ブロック内に、すべてのロジックは<script>内になければならず、フレームワークは使わず、ファイルをブラウザで直接開けるように。デザインはミニマルでコーヒーをテーマにし、プロダクションの複雑さよりも明確でインタラクティブなプレビューを優先すること。
GLM 4.7は高い計画オーバーヘッドを示します。トークン予算のかなりの部分をグローバルなレイアウト、テーマ設定、構造的な足場に割り当てます。制約のない環境では、これはより「プロダクショングレード」の成果物を生み出す可能性があります。しかし、コンテキスト長や最大トークンに厳しい上限がある場合、この振る舞いは部分的な出力失敗のリスクを高めます。モデルが先行するアーキテクチャに多くのトークンを費やし、実行可能な終了状態に到達できないのです。左側に見られるものは、事実上途中で切れた生成であり、機能しないUIシェルです。
MiniMax M2.1は早期収束に最適化されています。推測的な構造を最小限に抑え、動作するUIプリミティブを迅速に出力し、命令と出力の間の密なループを維持します。右側の結果は視覚的に野心的ではありませんが、中核となる契約を満たしています。決定論的なレンダリング、境界のあるレイアウト、即時のインタラクティビティです。エージェントの観点では、より低い分散で有効な終了状態に到達します。
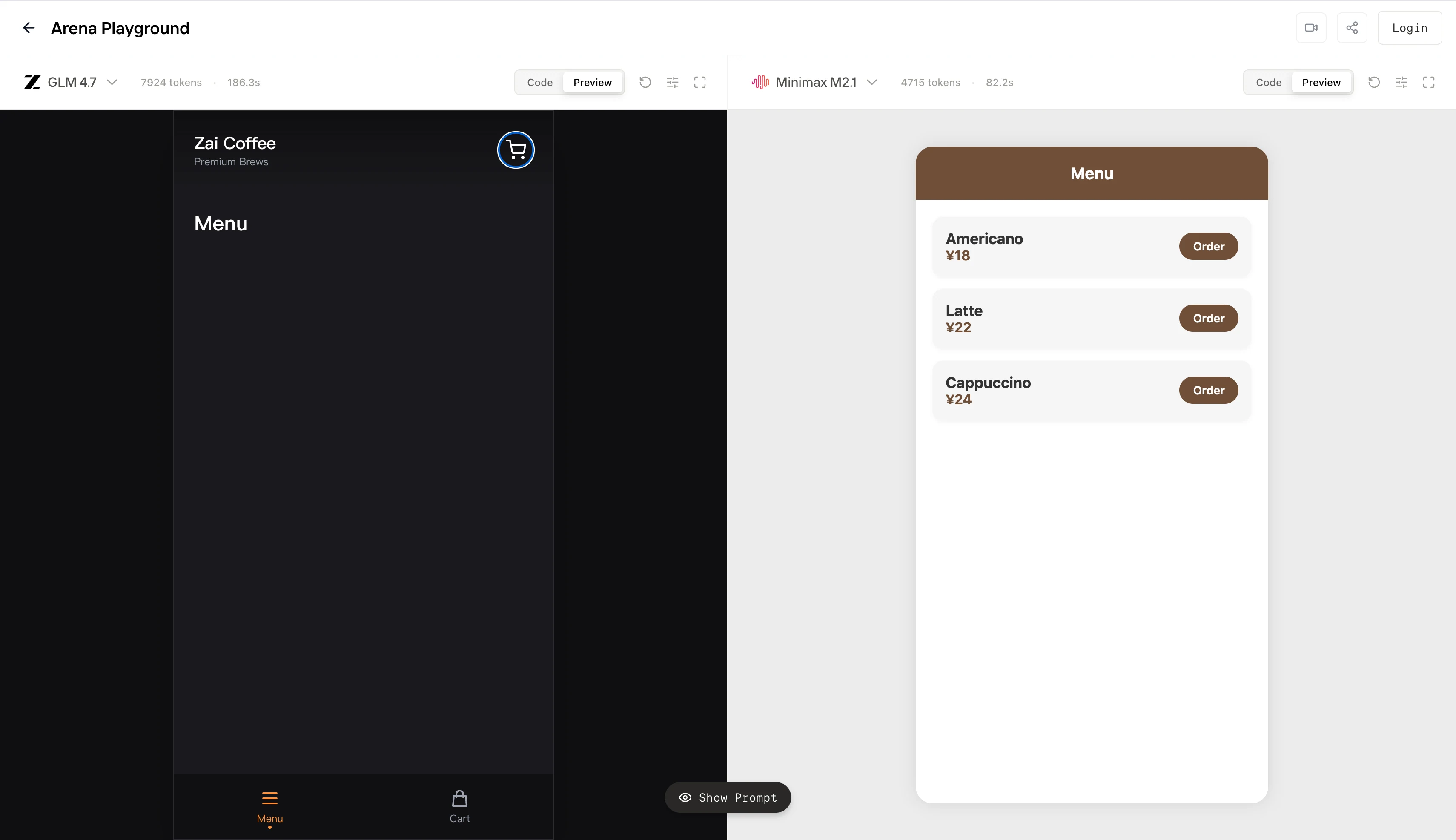
要約すると、GLM 4.7は設計の完全性とシステムレベルの推論に最適化されたモデルとして動作します。MiniMax M2.1は境界のある実行とワークフローの決定論性に最適化されたモデルとして動作します。
お手頃価格でGLM 4.7とMiniMax M2.1を使うには?
オプション1: 直接API統合 (Python例)
主な特徴:
- 統一エンドポイント:
/v3/openaiはOpenAIのChat Completions API形式をサポート。 - 柔軟な制御: temperature、top-p、ペナルティなどを調整して結果をカスタマイズ。
- ストリーミングとバッチ: 好みのレスポンスモードを選択可能。
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ3: 無料トライアルを開始
選択したモデルの機能を試すために無料トライアルを開始します。
ステップ4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像に示されているようにAPIキーをコピーします。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "あなたは役立つアシスタントです。"},
{"role": "user", "content": "こんにちは、元気ですか?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
オプション2: OpenAI Agents SDKによるマルチエージェントワークフロー
Novita AIをOpenAI Agents SDKと統合して、高度なマルチエージェントシステムを構築:
- プラグアンドプレイ: Novita AIのLLMをOpenAI Agentsワークフローで使用可能。
- ハンドオフ、ルーティング、ツール使用をサポート: エージェントが委任、トリアージ、または関数実行を行えるように設計。すべてNovita AIのモデルが動作。
- Python統合: SDKをNovitaのエンドポイント(
https://api.novita.ai/v3/openai)に設定し、APIキーを使用するだけ。
オプション3: サードパーティプラットフォームでGLM 4.7 Flash APIに接続
- Hugging Face: Novita AIエンドポイントを介して、Spaces、パイプライン、またはTransformersライブラリでGLM 4.7とMiniMax M2.1を使用。
- エージェント&オーケストレーションフレームワーク: Continue、AnythingLLM、LangChain、Dify、Langflowなどのパートナープラットフォームと、公式コネクタおよびステップバイステップの統合ガイドを通じて簡単に接続。
- OpenAI互換API: Cline、OpenCode、Cursorなどのツールとシームレスに統合。OpenAI API標準に準拠。
GLM 4.7は設計の完全性、長期計画、構造化推論に最適化されており、MiniMax M2.1は境界のある実行、速度、決定論的なエージェントループに最適化されています。GLM 4.7とMiniMax M2.1の選択は、生の知能の問題ではなく、システムがアーキテクチャの深さと制約下での信頼性の高いタスク完了のどちらを重視するかという問題です。
長時間実行されるエージェントワークフローには、GLM 4.7とMiniMax M2.1のどちらのモデルが優れていますか?
MiniMax M2.1は安定したペーシングと境界のある実行を維持するため、長時間実行されるエージェントワークフローに適しています。一方、GLM 4.7はスコープを拡大し、時間とともに遅くなる傾向があります。
なぜGLM 4.7はトークン制限下で実行可能な結果を生成できないことがあるのですか?
GLM 4.7は先行する計画と構造により多くのトークンを割り当てるため、コンテキストや出力の予算が制限されている場合に部分的な出力失敗のリスクが高まります。
制約のある環境でMiniMax M2.1がより信頼性が高い理由は何ですか?
MiniMax M2.1は早期に収束し、動作するプリミティブを迅速に出力し、実行可能性を維持するため、厳しいトークンやレイテンシーの制限下でもより回復力があります。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃な価格で信頼性の高いGPUクラウドも提供し、構築とスケーリングを支援します。



