

Los desarrolladores que construyen flujos de trabajo de agentes se enfrentan a un dilema recurrente: ¿deberían priorizar el razonamiento profundo y la integridad arquitectónica, o la ejecución rápida y fiable de tareas bajo estrictos límites de tokens y costes? GLM 4.7 y MiniMax M2.1 representan estas dos estrategias de optimización opuestas. Este artículo analiza su comportamiento como agentes en términos de arquitectura, benchmarks, dinámicas de inferencia y divergencia en tareas reales, ayudando a los desarrolladores a decidir qué modelo se adapta mejor a sus restricciones de producción y objetivos de flujo de trabajo.
Comportamiento como agente de GLM 4.7 y MiniMax M2.1
El autor describió la ejecución de ambos modelos en una tarea completa de principio a fin para construir un ejecutor de tareas CLI con múltiples funcionalidades, incluyendo fases de planificación de arquitectura e implementación, donde ambos modelos completaron todos los requisitos sin intervención humana. Basándose en estas evaluaciones cualitativas, la siguiente tabla resume cómo se desempeña cada modelo en dimensiones clave del trabajo de agente:
| Dimensión | MiniMax M2.1 | GLM 4.7 | Justificación |
|---|---|---|---|
| Adherencia a instrucciones y alineación | 9 | 7 | M2.1 se describe como firmemente alineado y resistente a la desviación del alcance. GLM tiende a expandir el alcance. |
| Razonamiento de planificación y arquitectura | 6 | 9 | GLM destaca en diseño de sistemas y estructura a largo plazo. M2.1 es más táctico. |
| Eficiencia de ejecución | 9 | 6 | M2.1 es más rápido y significativamente más barato. GLM es más lento y de mayor coste. |
| Resistencia en flujos de trabajo | 8 | 6 | M2.1 se desempeña bien en flujos de trabajo de agente largos e ininterrumpidos. GLM se ralentiza en estos entornos. |
| Calidad y mantenibilidad del código | 7 | 9 | GLM produce abstracciones y estructuras más limpias. M2.1 favorece la simplicidad pero puede ser tosco. |
| Documentación y comunicación | 3 | 9 | M2.1 genera poca documentación. GLM produce READMEs detallados y documentación interna. |
| Profundidad de razonamiento y consistencia de reglas | 6 | 9 | GLM es más fuerte en lógica compleja y dominios con muchas reglas. |
| Proactividad y gestión del alcance | 9 | 5 | M2.1 se mantiene limitado a la tarea. GLM a menudo sobreingenieriza y se desvía. |
La comparación anterior muestra que GLM 4.7 y MiniMax M2.1 están construidos con objetivos muy diferentes. Uno se centra en un pensamiento más profundo, una estructura más clara y una planificación a largo plazo. El otro se centra en la velocidad, el coste y la ejecución fiable de tareas en flujos de trabajo de agentes. Estos objetivos moldean el comportamiento de cada modelo y explican por qué la misma tarea puede llevar a resultados tan diferentes.
En las siguientes secciones, este artículo explicará de dónde provienen estas diferencias y qué significan en la práctica, cubriendo arquitectura, benchmarks, eficiencia, despliegue y casos de uso reales de desarrolladores.
Arquitectura de GLM 4.7 y MiniMax M2.1
| Especificación | GLM 4.7 | MiniMax M2.1 |
|---|---|---|
| Tipo de arquitectura | MoE con enrutamiento de inferencia activa, 32B activos | MoE con activación selectiva, 10B activos |
| Ventana de contexto | 200 000 tokens | 204 800 tokens |
| Salida máxima | 128 000 tokens | 131 072 tokens |
GLM 4.7 usa un conjunto de parámetros activos más grande para enfatizar el razonamiento profundo, la planificación y las salidas estructuradas. MiniMax M2.1 se centra en la activación dispersa para reducir el cómputo y el coste, manteniendo un fuerte seguimiento de instrucciones y flujos de trabajo agénticos.
Benchmarks de GLM 4.7 y MiniMax M2.1
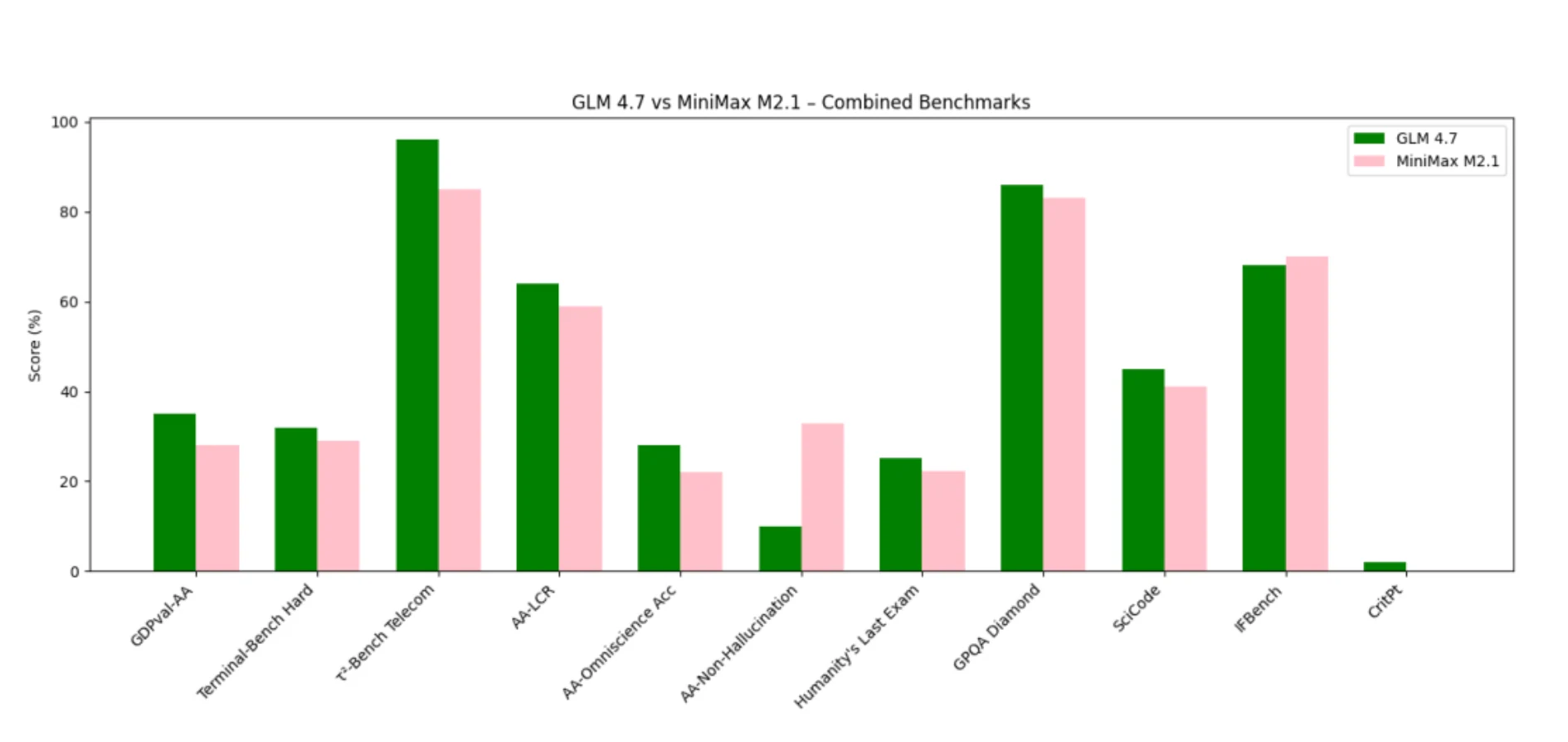
GLM 4.7 domina en benchmarks que recompensan el razonamiento profundo, la coherencia en largos contextos y el pensamiento estructurado con herramientas.
MiniMax M2.1 destaca en benchmarks relacionados con la fidelidad a las instrucciones, la ejecución de agentes y el bajo comportamiento alucinatorio.
Velocidad de inferencia de GLM 4.7 y MiniMax M2.1
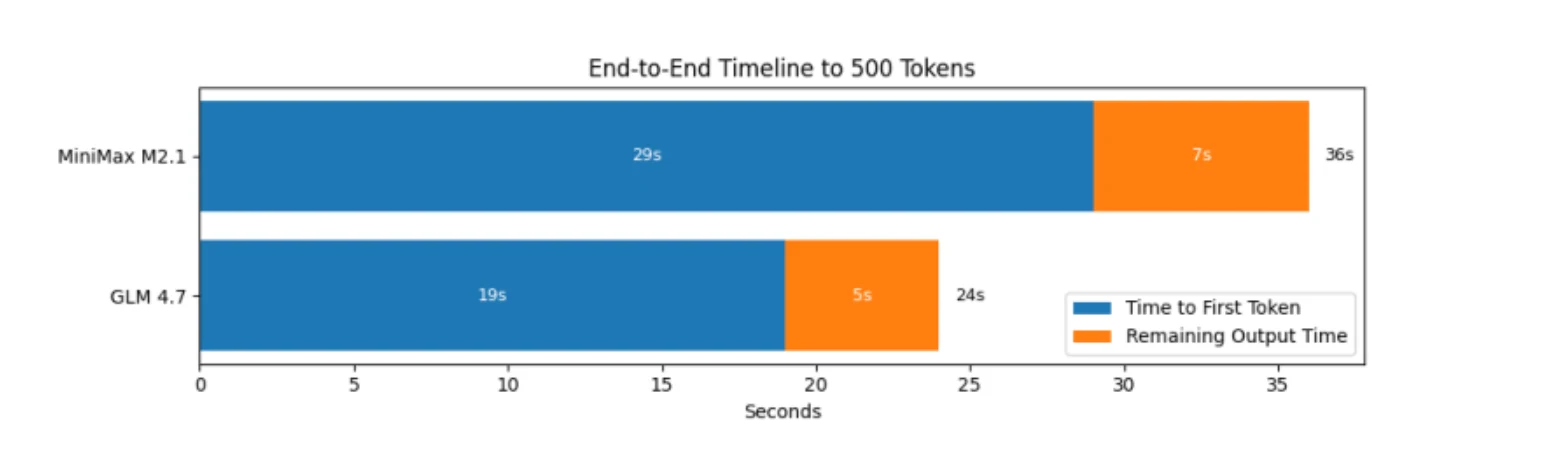
En términos de benchmarks, GLM 4.7 es más eficiente en la mecánica de inferencia pura: comienza antes, genera más rápido y termina antes.
¡Prueba GLM 4.7 y MiniMax M2.1 ahora!
Donde MiniMax gana su reputación de «eficiente» es a nivel de flujo de trabajo. En bucles de agente reales:
- MiniMax tiende a dedicar menos tiempo a fases internas de razonamiento largo.
- Mantiene los pasos cortos y directos.
- Mantiene un ritmo estable a lo largo de muchas iteraciones.
Esto lo hace más rápido en desarrollo iterativo, incluso cuando el rendimiento bruto y el tiempo total favorecen a GLM.
Cómo diverge la misma tarea entre GLM 4.7 y MiniMax M2.1
Prompt: quiero un demo H5 en un solo archivo, entregado como un
index.htmlejecutable, que simule un flujo completo de pedido de café para previsualización e interacción. La página debe contener tres estados de vista: un menú mostrando tres cafés (Americano ¥18, Latte ¥22, Cappuccino ¥24) con botones «Order»; una vista de detalle del producto donde los usuarios puedan personalizar tamaño, temperatura y extras con actualizaciones de precio en tiempo real y una acción «Add to Cart» que reproduzca un sonido corto y muestre una confirmación; y una vista del carrito que liste los artículos seleccionados, el precio total y un botón «Place Order» que genere un ID de pedido aleatorio y un código de recogida de 4 dígitos en un panel de confirmación. Todo el CSS debe estar dentro de una etiqueta<style>, toda la lógica dentro de<script>, sin frameworks, para que el archivo se pueda abrir directamente en un navegador. El diseño debe ser minimalista y temático de café, priorizando una previsualización clara e interactiva sobre la complejidad de producción.
GLM 4.7 presenta una alta sobrecarga de planificación. Dedica una gran parte de su presupuesto de tokens al diseño global, la temática y el andamiaje estructural. En entornos sin restricciones, esto puede generar un artefacto más cercano a «calidad de producto». Sin embargo, bajo límites estrictos de longitud de contexto o tokens máximos, este comportamiento aumenta el riesgo de fallo de emisión parcial: el modelo gasta mucho en arquitectura inicial y nunca alcanza un estado terminal ejecutable. Lo que se ve a la izquierda es efectivamente una generación truncada: una interfaz de usuario no funcional.
MiniMax M2.1 optimiza para la convergencia temprana. Minimiza la especulación estructural, emite rápidamente primitivas de UI funcionales y mantiene un bucle ajustado entre instrucción y salida. El resultado de la derecha no es visualmente ambicioso, pero satisface el contrato principal: renderizado determinista, diseño acotado e interactividad inmediata. En términos de agente, alcanza un estado final válido con menor varianza.
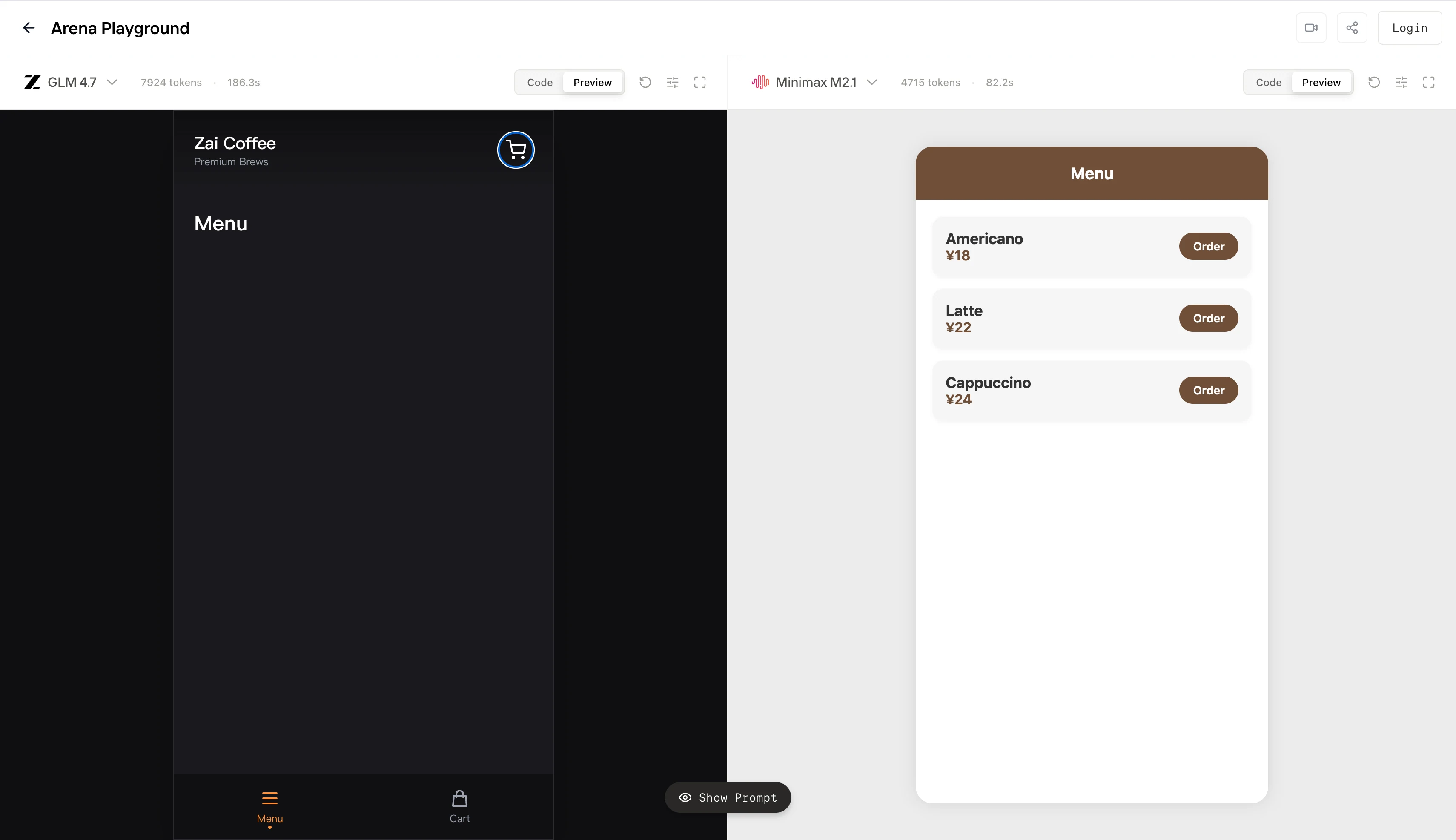
En resumen, GLM 4.7 se comporta como un modelo optimizado para la integridad del diseño y el razonamiento a nivel de sistema. MiniMax M2.1 se comporta como un modelo optimizado para la ejecución acotada y el determinismo del flujo de trabajo.
Cómo usar GLM 4.7 y MiniMax M2.1 a buen precio
Opción 1: Integración directa mediante API (ejemplo en Python)
Características clave:
- Endpoint unificado:
/v3/openaisoporta el formato de la API de Chat Completions de OpenAI. - Controles flexibles: Ajusta temperatura, top-p, penalizaciones y más para obtener resultados personalizados.
- Streaming y procesamiento por lotes: Elige tu modo de respuesta preferido.
Paso 1: Iniciar sesión y acceder a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elegir tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

¡Prueba GLM 4.7 y MiniMax M2.1 ahora!
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página «Settings» y copia la clave de API como se indica en la imagen.

from openai import OpenAI
client = OpenAI(
api_key="<Tu clave de API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Opción 2: Flujos de trabajo multi-agente con el SDK de OpenAI Agents
Construye sistemas multi-agente avanzados integrando Novita AI con el OpenAI Agents SDK:
- Conecta y usa: Utiliza los LLM de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Soporta traspasos, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, triage o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración en Python: Simplemente apunta el SDK al endpoint de Novita (
https://api.novita.ai/v3/openai) y usa tu clave de API.
Opción 3: Conecta la API Flash de GLM 4.7 en plataformas de terceros
- Hugging Face: Usa GLM 4.7 y MiniMax M2.1 en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
- Frameworks de Agentes y Orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
- API compatible con OpenAI: Disfruta de una migración e integración sin problemas con herramientas como Cline, OpenCode y Cursor, diseñadas para el estándar de API de OpenAI.
GLM 4.7 está optimizado para la integridad del diseño, la planificación a largo plazo y el razonamiento estructurado, mientras que MiniMax M2.1 está optimizado para la ejecución acotada, la velocidad y los bucles de agente deterministas. La elección entre GLM 4.7 y MiniMax M2.1 no se trata de inteligencia bruta, sino de si tu sistema valora la profundidad arquitectónica o el cierre fiable de tareas bajo restricciones.
¿Qué modelo es mejor para flujos de trabajo de agente de larga duración, GLM 4.7 o MiniMax M2.1?
MiniMax M2.1 es mejor para flujos de trabajo de agente de larga duración porque mantiene un ritmo estable y una ejecución acotada, mientras que GLM 4.7 tiende a expandir el alcance y ralentizarse con el tiempo.
¿Por qué GLM 4.7 a veces falla en producir un resultado ejecutable bajo límites de tokens?
GLM 4.7 asigna más tokens a la planificación y estructura inicial, lo que aumenta el riesgo de fallo de emisión parcial cuando el presupuesto de contexto o de salida está limitado.
¿Qué hace que MiniMax M2.1 sea más fiable en entornos restringidos?
MiniMax M2.1 converge temprano, emite primitivas funcionales rápidamente y preserva la ejecutabilidad, lo que lo hace más resiliente bajo límites estrictos de tokens y latencia.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona GPU en la nube asequible y confiable para construir y escalar.



