

- Agentenverhalten von GLM 4.7 und MiniMax M2.1
- Architektur von GLM 4.7 und MiniMax M2.1
- Benchmark von GLM 4.7 und MiniMax M2.1
- Inferenzgeschwindigkeit von GLM 4.7 und MiniMax M2.1
- Wie die gleiche Aufgabe bei GLM 4.7 und MiniMax M2.1 unterschiedlich verläuft
- Wie nutzt du GLM 4.7 und MiniMax M2.1 zu einem guten Preis?
Entwickler, die Agenten-Workflows erstellen, stehen immer wieder vor der gleichen Frage: Sollen sie tiefgehende Schlussfolgerung und architektonische Vollständigkeit priorisieren, oder schnelle, zuverlässige Aufgabenausführung unter strengen Token- und Kostengrenzen? GLM 4.7 und MiniMax M2.1 verkörpern diese beiden gegensätzlichen Optimierungsstrategien. Dieser Artikel analysiert ihr Agentenverhalten über Architektur, Benchmarks, Inferenzdynamik und Abweichungen bei realen Aufgaben hinweg, um Entwicklern zu helfen, zu entscheiden, welches Modell besser zu ihren Produktionsbeschränkungen und Workflow-Zielen passt.
Agentenverhalten von GLM 4.7 und MiniMax M2.1
Der Autor beschrieb, dass er beide Modelle durch eine vollständige End-to-End-Aufgabe zum Erstellen eines CLI-Task-Runners mit mehreren Funktionen laufen ließ, einschließlich Architekturplanung und Implementierungsphasen, wobei beide Modelle alle Anforderungen ohne menschliches Eingreifen erfüllten. Basierend auf diesen qualitativen Bewertungen fasst die folgende Tabelle zusammen, wie jedes Modell in den wichtigsten Dimensionen der Agentenarbeit abschneidet:
| Dimension | MiniMax M2.1 | GLM 4.7 | Begründung |
|---|---|---|---|
| Befolgung von Anweisungen und Ausrichtung | 9 | 7 | M2.1 wird als streng ausgerichtet und resistent gegen Scope-Drift beschrieben. GLM neigt dazu, den Scope zu erweitern. |
| Planung und architektonische Schlussfolgerung | 6 | 9 | GLM glänzt bei Systemdesign und langfristiger Struktur. M2.1 ist eher taktisch orientiert. |
| Ausführungseffizienz | 9 | 6 | M2.1 ist schneller und deutlich günstiger. GLM ist langsamer und kostspieliger. |
| Workflow-Ausdauer | 8 | 6 | M2.1 performt gut in langen, ununterbrochenen Agenten-Workflows. GLM verlangsamt sich in solchen Einstellungen. |
| Codequalität und Wartbarkeit | 7 | 9 | GLM erstellt sauberere Abstraktionen und Strukturen. M2.1 bevorzugt Einfachheit, kann aber unausgereift sein. |
| Dokumentation und Kommunikation | 3 | 9 | M2.1 generiert wenig Dokumentation. GLM erstellt umfangreiche README- und interne Dokumente. |
| Schlussfolgerungstiefe und Regelkonsistenz | 6 | 9 | GLM ist stärker in komplexen Logik- und regelbasierten Domänen. |
| Proaktivität und Scope-Management | 9 | 5 | M2.1 bleibt an die Aufgabe gebunden. GLM überkonstruiert oft und driftet ab. |
Der obige Vergleich zeigt, dass GLM 4.7 und MiniMax M2.1 mit sehr unterschiedlichen Zielen entwickelt wurden. Eines konzentriert sich auf tiefergehendes Denken, klarere Struktur und langfristige Planung. Das andere konzentriert sich auf Geschwindigkeit, Kosten und zuverlässige Aufgabenausführung in Agenten-Workflows. Diese Ziele prägen das Verhalten jedes Modells und erklären, warum die gleiche Aufgabe zu so unterschiedlichen Ergebnissen führen kann.
In den folgenden Abschnitten erklärt dieser Artikel, wo diese Unterschiede herkommen und was sie in der Praxis bedeuten, und behandelt dabei Architektur, Benchmarks, Effizienz, Bereitstellung und reale Anwendungsfälle für Entwickler.
Architektur von GLM 4.7 und MiniMax M2.1
| Spezifikation | GLM 4.7 | MiniMax M2.1 |
|---|---|---|
| Architekturtyp | MoE mit aktiver Inferenz-Routing, 32B aktiv | MoE mit selektiver Aktivierung, 10B aktiv |
| Kontextfenster | 200.000 Token | 204.800 Token |
| Maximale Ausgabe | 128.000 Token | 131.072 Token |
GLM 4.7 verwendet einen größeren aktiven Parametersatz, um tiefgehende Schlussfolgerung, Planung und strukturierte Ausgaben zu betonen. MiniMax M2.1 konzentriert sich auf sparse Aktivierung, um Rechenleistung und Kosten zu senken, während es gleichzeitig eine starke Befolgung von Anweisungen und agentische Workflows beibehält.
Benchmark von GLM 4.7 und MiniMax M2.1
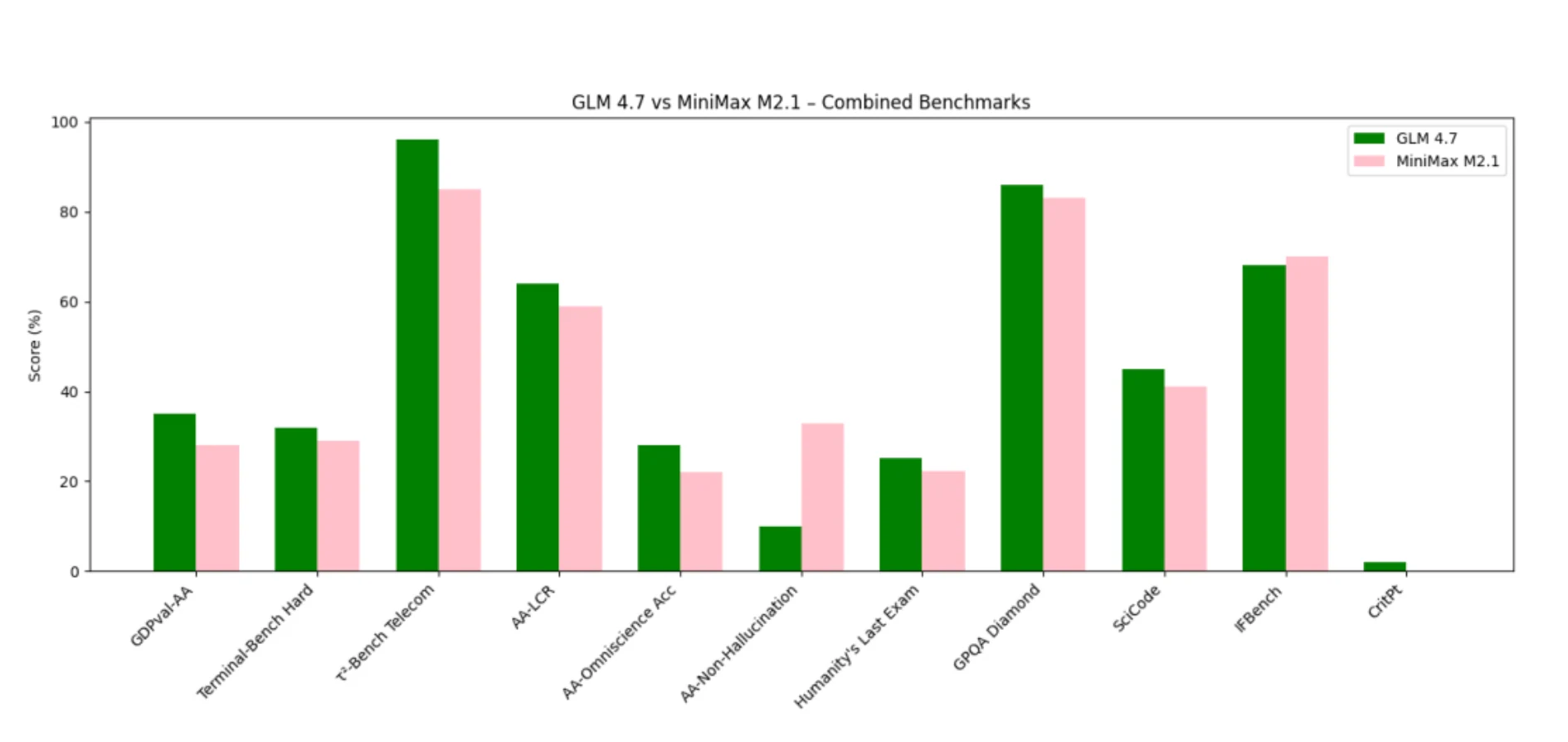
GLM 4.7 dominiert in Benchmarks, die tiefgehende Schlussfolgerung, Kohärenz über lange Kontexte und strukturiertes Tool-Denken belohnen.
MiniMax M2.1 glänzt in Benchmarks, die an Anweisungstreue, Agentenausführung und niedrige Halluzinationsraten gebunden sind.
Inferenzgeschwindigkeit von GLM 4.7 und MiniMax M2.1
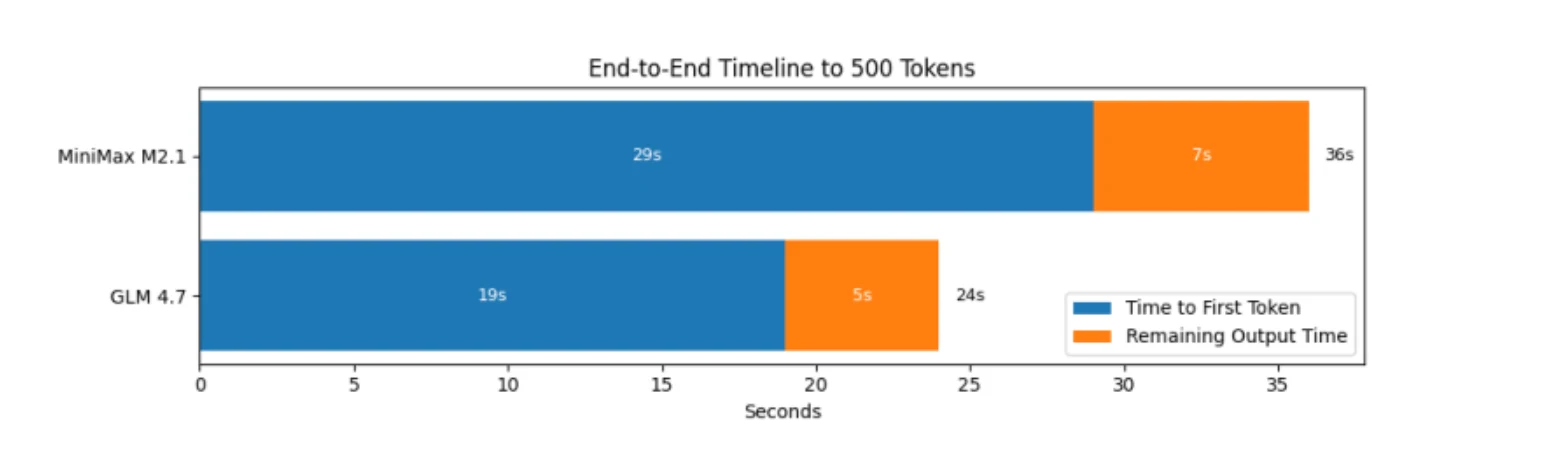
In Bezug auf Benchmarks ist GLM 4.7 also effizienter in reinen Inferenzmechaniken: Es startet früher, gibt Ausgaben schneller aus und beendet die Verarbeitung früher.
Probiere GLM 4.7 und MiniMax M2.1 jetzt aus!
Wo MiniMax seinen Ruf als „effizient“ erlangt, ist auf Workflow-Ebene. In echten Agenten-Schleifen:
- MiniMax neigt dazu, weniger Zeit in langen internen Schlussfolgerungsphasen zu verbringen.
- Es hält Schritte kurz und direkt.
- Es behält ein stabiles Tempo über viele Turns hinweg bei.
Das macht es in iterativer Entwicklung schneller, selbst wenn roher Durchsatz und End-to-End-Zeitmessung GLM bevorzugen.
Wie die gleiche Aufgabe bei GLM 4.7 und MiniMax M2.1 unterschiedlich verläuft
Prompt:Ich möchte eine einzelne H5-Demo-Datei, die als eine ausführbare
index.htmlgeliefert wird und einen vollständigen Kaffeebestellungsablauf zur Vorschau und Interaktion simuliert. Die Seite soll drei Ansichtsstatus enthalten: Ein Menü, das drei Kaffees (Americano ¥18, Latte ¥22, Cappuccino ¥24) mit „Bestellen“-Schaltflächen anzeigt; eine Produktdetailansicht, in der Benutzer Größe, Temperatur und Extras anpassen können, mit Echtzeit-Preisaktualisierungen und einer „In den Warenkorb“-Aktion, die einen kurzen Ton abspielt und eine Bestätigung anzeigt; und eine Warenkorbansicht, die ausgewählte Artikel, den Gesamtpreis und eine „Bestellung aufgeben“-Schaltfläche auflistet, die eine zufällige Bestell-ID und einen 4-stelligen Abholcode in einem Bestätigungsbereich generiert. Das gesamte CSS muss in einem<style>-Block, die gesamte Logik in einem<script>-Block enthalten sein, ohne Frameworks, sodass die Datei direkt im Browser geöffnet werden kann. Das Design sollte minimalistisch und kaffeeorientiert sein, wobei eine klare, interaktive Vorschau gegenüber Produktionskomplexität priorisiert wird.
GLM 4.7 weist einen hohen Planungsaufwand auf. Es weist einen großen Teil seines Token-Budgets für globales Layout, Theming und strukturelles Gerüst zu. In uneingeschränkten Umgebungen kann dies ein „produktionsreifes“ Artefakt ergeben. Unter harten Grenzen für Kontextlänge oder maximale Token erhöht dieses Verhalten jedoch das Risiko eines teilweisen Generierungsfehlers: Das Modell gibt viel für die vorab erstellte Architektur aus und erreicht nie einen ausführbaren Endzustand. Was du links siehst, ist effektiv eine abgeschnittene Generierung, eine nicht funktionsfähige UI-Hülle.
MiniMax M2.1 optimiert auf frühe Konvergenz. Es minimiert spekulative Strukturen, gibt schnell funktionsfähige UI-Grundbausteine aus und erhält eine enge Schleife zwischen Anweisung und Ausgabe. Das Ergebnis auf der rechten Seite ist visuell nicht sehr ambitioniert, aber es erfüllt den Kernvertrag: Deterministisches Rendering, begrenztes Layout und sofortige Interaktivität. In Agentenbegriffen erreicht es einen gültigen Endzustand mit geringerer Varianz.
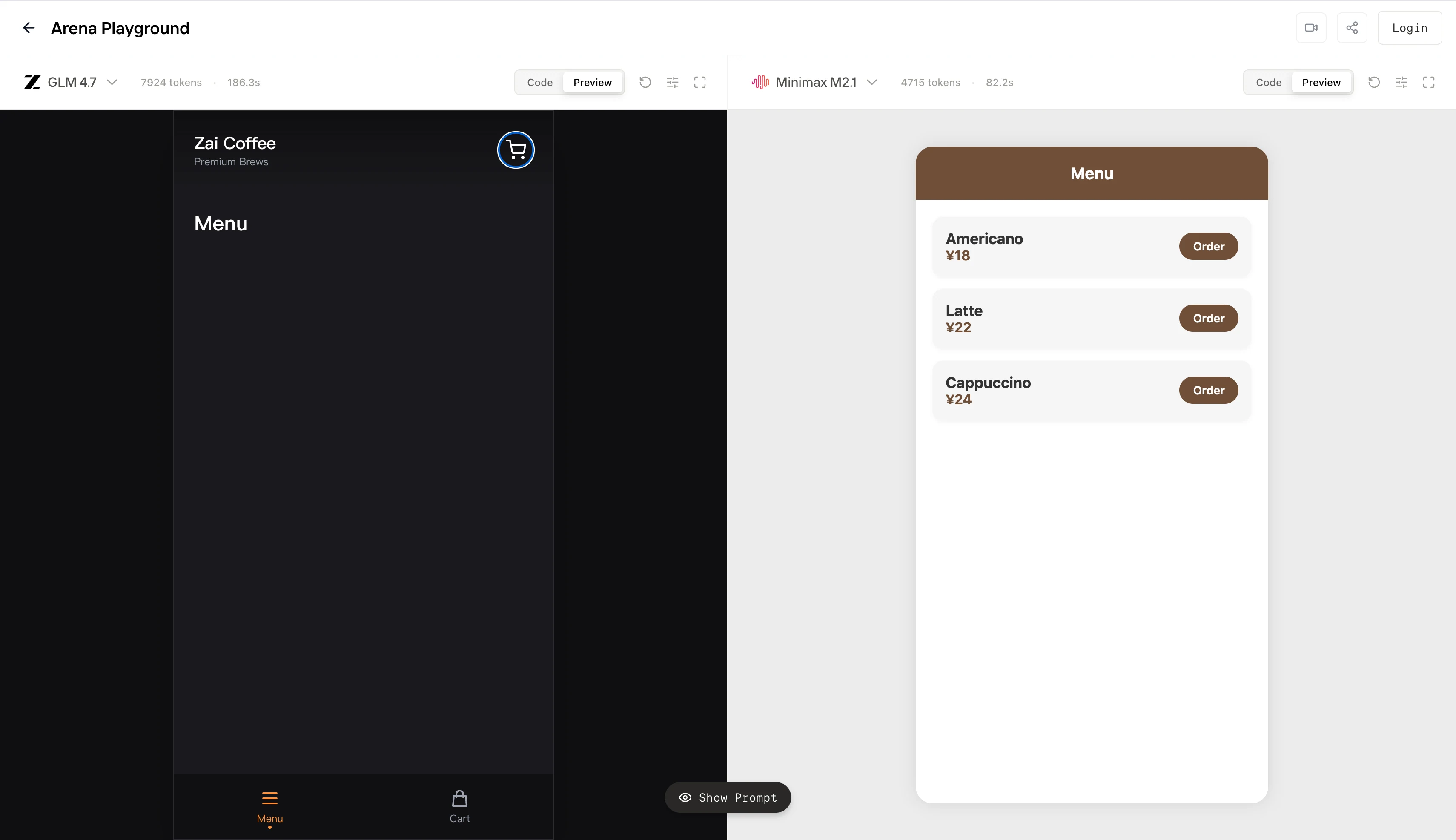
Kurz gesagt verhält sich GLM 4.7 wie ein Modell, das auf Designvollständigkeit und Schlussfolgerung auf Systemebene optimiert ist. MiniMax M2.1 verhält sich wie ein Modell, das auf begrenzte Ausführung und Workflow-Determinismus optimiert ist.
Wie nutzt du GLM 4.7 und MiniMax M2.1 zu einem guten Preis?
Option 1: Direkte API-Integration (Python-Beispiel)
Hauptmerkmale:
- Einheitlicher Endpunkt:
/v3/openaiunterstützt das Format der Chat-Completions-API von OpenAI. - Flexible Steuerung: Passe Temperatur, Top-p, Strafen und mehr an, um maßgeschneiderte Ergebnisse zu erhalten.
- Streaming & Batch-Verarbeitung: Wähle deinen bevorzugten Antwortmodus.
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Logge dich in dein Konto ein und klicke auf die Schaltfläche Modellbibliothek.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell, das deinen Anforderungen entspricht.

Probiere GLM 4.7 und MiniMax M2.1 jetzt aus!
Schritt 3: Starte deine kostenlose Testversion
Starte deine kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Hole deinen API-Schlüssel
Zur Authentifizierung mit der API stellen wir dir einen neuen API-Schlüssel zur Verfügung. Wenn du die Seite „Einstellungen“ aufrufst, kannst du den API-Schlüssel wie in der Abbildung gezeigt kopieren.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agenten-Workflows mit dem OpenAI Agents SDK
Erstelle fortschrittliche Multi-Agenten-Systeme, indem du Novita AI mit dem OpenAI Agents SDK integrierst:
- Plug-and-Play: Verwende die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwirf Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Zeige den SDK einfach auf Novitas Endpunkt (
https://api.novita.ai/v3/openai) und verwende deinen API-Schlüssel.
Option 3:Verbinde die GLM 4.7 Flash API auf Drittanbieterplattformen
- Hugging Face: Verwende GLM 4.7 und MInimax M2.1 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- und Orchestrierungs-Frameworks: Verbinde Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Konnektoren und Schritt-für-Schritt-Integrationsanleitungen.
- OpenAI-kompatible API: Genieße problemlose Migration und Integration mit Tools wie Cline, OpenCode und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
GLM 4.7 ist auf Designvollständigkeit, langfristige Planung und strukturierte Schlussfolgerung optimiert, während MiniMax M2.1 auf begrenzte Ausführung, Geschwindigkeit und deterministische Agenten-Schleifen optimiert ist. Die Wahl zwischen GLM 4.7 und MiniMax M2.1 hängt nicht von roher Intelligenz ab, sondern davon, ob dein System architektonische Tiefe oder zuverlässigen Aufgabenabschluss unter Beschränkungen priorisiert.
Welches Modell ist besser für lang laufende Agenten-Workflows, GLM 4.7 oder MiniMax M2.1?
MiniMax M2.1 ist besser für lang laufende Agenten-Workflows geeignet, da es ein stabiles Tempo und begrenzte Ausführung beibehält, während GLM 4.7 dazu neigt, den Scope zu erweitern und im Laufe der Zeit langsamer zu werden.
Warum schafft es GLM 4.7 manchmal nicht, ein ausführbares Ergebnis unter Token-Grenzen zu erzeugen?
GLM 4.7 weist mehr Token für vorab durchgeführte Planung und Struktur zu, was das Risiko eines teilweisen Generierungsfehlers erhöht, wenn Kontext- oder Ausgabebudgets begrenzt sind.
Was macht MiniMax M2.1 in beschränkten Umgebungen zuverlässiger?
MiniMax M2.1 konvergiert früh, gibt schnell funktionsfähige Grundbausteine aus und erhält die Ausführbarkeit, was MiniMax M2.1 widerstandsfähiger gegenüber harten Token- und Latenzgrenzen macht.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



