

Desenvolvedores que criam fluxos de trabalho de agentes enfrentam um dilema recorrente: devem priorizar raciocínio profundo e completude arquitetônica, ou execução de tarefas rápida e confiável sob limites rigorosos de tokens e custos? O GLM 4.7 e o MiniMax M2.1 personificam essas duas estratégias de otimização opostas. Este artigo analisa o comportamento de seus agentes em arquitetura, benchmarks, dinâmicas de inferência e divergência de tarefas do mundo real, ajudando os desenvolvedores a decidir qual modelo se adapta melhor às suas restrições de produção e objetivos de fluxo de trabalho.
Comportamento do Agente do GLM 4.7 e do MiniMax M2.1
O autor descreveu a execução de ambos os modelos em uma tarefa completa de ponta a ponta para construir um executor de tarefas CLI com vários recursos, incluindo fases de planejamento arquitetônico e implementação, com ambos os modelos concluindo todos os requisitos sem intervenção humana. Com base nessas avaliações qualitativas, a tabela a seguir resume o desempenho de cada modelo nas principais dimensões do trabalho de agente:
| Dimensão | MiniMax M2.1 | GLM 4.7 | Justificativa |
|---|---|---|---|
| Aderência e alinhamento a instruções | 9 | 7 | O M2.1 é descrito como fortemente alinhado e resistente a desvios de escopo. O GLM tende a expandir o escopo. |
| Planejamento e raciocínio arquitetônico | 6 | 9 | O GLM se destaca em design de sistemas e estrutura de longo prazo. O M2.1 é mais tático. |
| Eficiência de execução | 9 | 6 | O M2.1 é mais rápido e significativamente mais barato. O GLM é mais lento e tem custo mais elevado. |
| Resistência do fluxo de trabalho | 8 | 6 | O M2.1 tem bom desempenho em fluxos de trabalho de agente longos e ininterruptos. O GLM desacelera nesses cenários. |
| Qualidade e manutenibilidade do código | 7 | 9 | O GLM produz abstrações e estrutura mais limpas. O M2.1 prioriza a simplicidade, mas pode ser mais rudimentar. |
| Documentação e comunicação | 3 | 9 | O M2.1 gera pouca documentação. O GLM produz READMEs e documentos internos detalhados. |
| Profundidade de raciocínio e consistência de regras | 6 | 9 | O GLM é mais forte em lógica complexa e domínios com muitas regras. |
| Proatividade e gerenciamento de escopo | 9 | 5 | O M2.1 se mantém dentro dos limites da tarefa. O GLM frequentemente superdimensiona e se desvia. |
A comparação acima mostra que o GLM 4.7 e o MiniMax M2.1 foram construídos com objetivos muito diferentes. Um foca em pensamento mais profundo, estrutura mais clara e planejamento de longo prazo. O outro foca em velocidade, custo e execução confiável de tarefas em fluxos de trabalho de agentes. Esses objetivos moldam o comportamento de cada modelo e explicam por que a mesma tarefa pode levar a resultados tão diferentes.
Nas seções a seguir, este artigo explicará de onde vêm essas diferenças e o que elas significam na prática, abordando arquitetura, benchmarks, eficiência, implantação e casos de uso reais de desenvolvedores.
Arquitetura do GLM 4.7 e do MiniMax M2.1
| Especificação | GLM 4.7 | MiniMax M2.1 |
|---|---|---|
| Tipo de Arquitetura | MoE com roteamento de inferência ativa, 32B ativos | MoE com ativação seletiva, 10B ativos |
| Janela de Contexto | 200.000 tokens | 204.800 tokens |
| Saída Máxima | 128.000 tokens | 131.072 tokens |
O GLM 4.7 usa um conjunto de parâmetros ativos maior para enfatizar raciocínio profundo, planejamento e saídas estruturadas. O MiniMax M2.1 foca na ativação esparsa para reduzir o poder de computação e o custo, preservando o forte cumprimento de instruções e fluxos de trabalho agenticos.
Benchmark do GLM 4.7 e do MiniMax M2.1
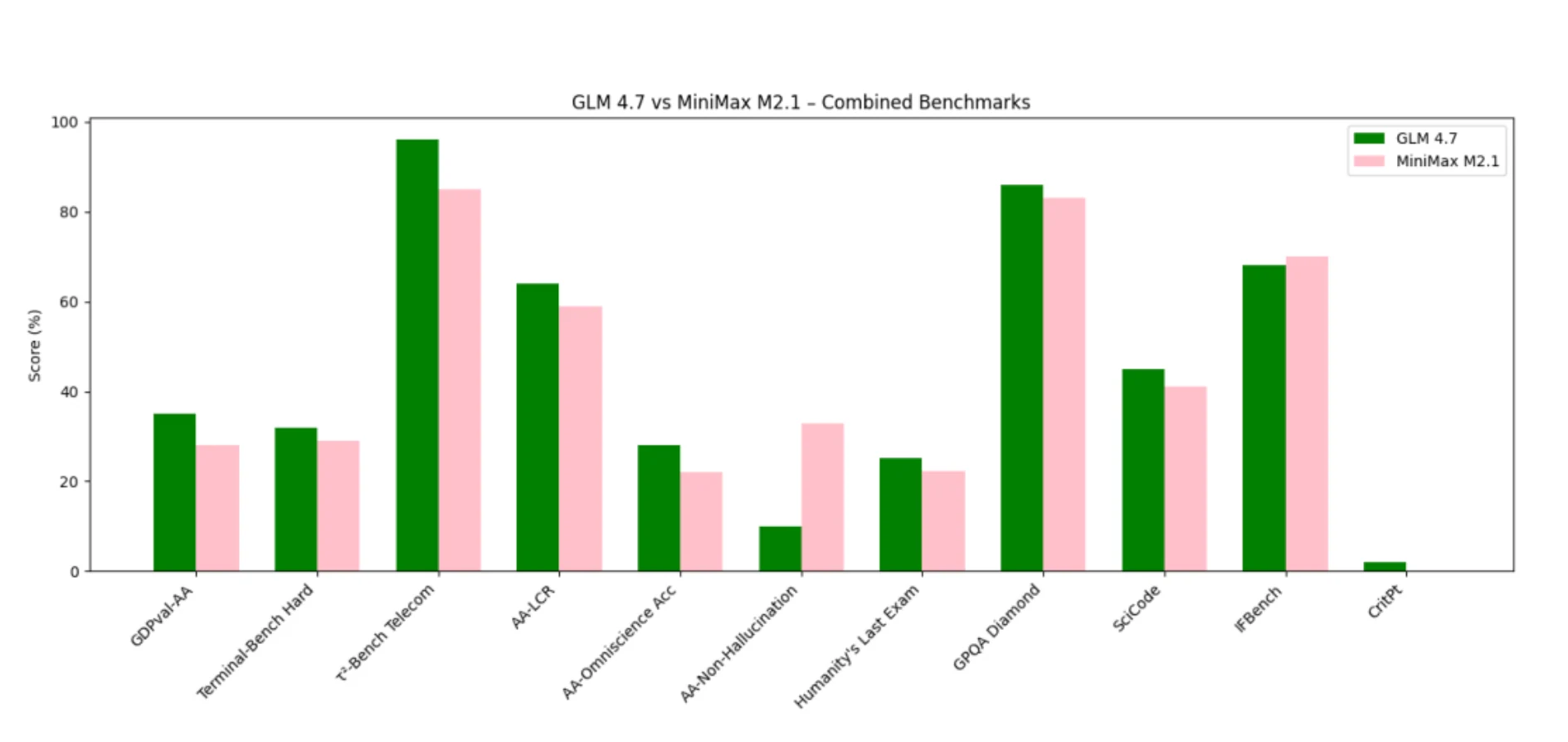
O GLM 4.7 domina nos benchmarks que recompensam raciocínio profundo, coerência de longo contexto e pensamento estruturado de ferramentas.
O MiniMax M2.1 se destaca em benchmarks ligados à fidelidade de instruções, execução de agentes e comportamento com baixa alucinação.
Velocidade de Inferência do GLM 4.7 e do MiniMax M2.1
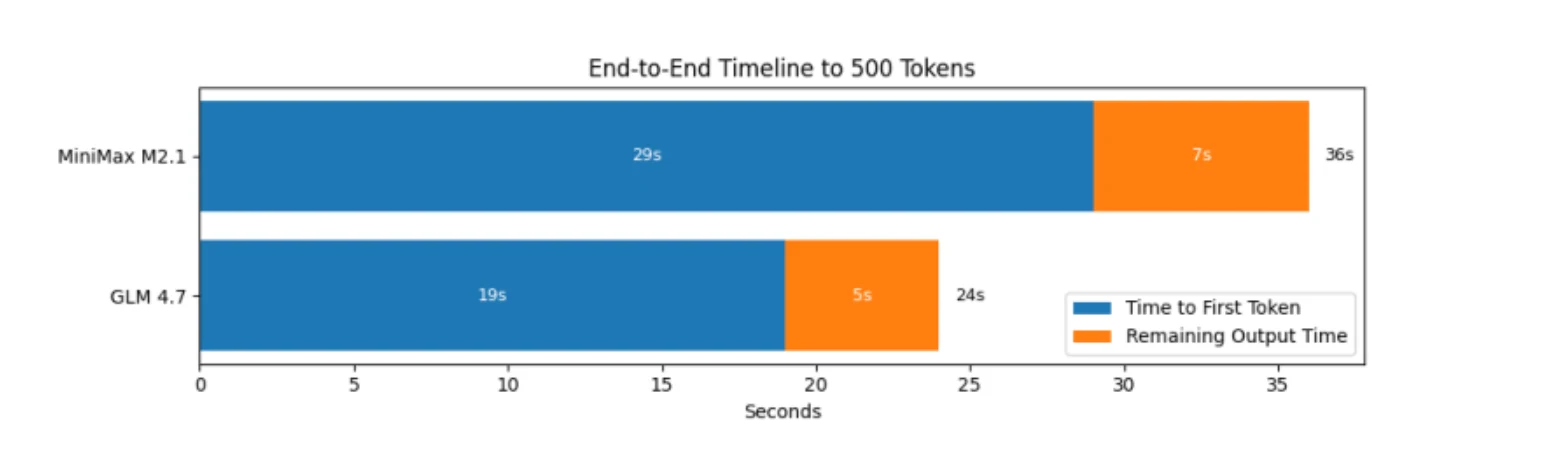
Portanto, em termos de benchmark, o GLM 4.7 é mais eficiente na mecânica de inferência pura: começa mais cedo, gera saídas mais rápido e termina mais cedo.
Experimente o GLM 4.7 e o MiniMax M2.1 Agora!
Onde o MiniMax ganha sua reputação de “eficiente” é no nível do fluxo de trabalho. Em loops de agente reais:
- O MiniMax tende a gastar menos tempo em fases longas de raciocínio interno.
- Mantém as etapas curtas e diretas.
- Mantém um ritmo estável em muitas turnos.
Isso o torna mais rápido no desenvolvimento iterativo, mesmo quando o throughput bruto e o tempo de ponta a ponta favorecem o GLM.
Como a Mesma Tarefa Diverg entre o GLM 4.7 e o MiniMax M2.1
Prompt:I want a single-file H5 demo, delivered as one runnable
index.html, that simulates a complete coffee ordering flow for preview and interaction. The page should contain three view states: a menu showing three coffees (Americano ¥18, Latte ¥22, Cappuccino ¥24) with “Order” buttons; a product detail view where users can customize size, temperature, and extras with real-time price updates and an “Add to Cart” action that plays a short sound and shows a confirmation; and a cart view listing selected items, total price, and a “Place Order” button that generates a random Order ID and 4-digit pickup code in a confirmation panel. All CSS must be inside a<style>block, all logic inside a<script>, with no frameworks, so the file can be opened directly in a browser. The design should be minimal and coffee-themed, prioritizing a clear, interactive preview over production complexity.
O GLM 4.7 apresenta um alto sobrecusto de planejamento. Ele aloca uma grande parte de seu orçamento de tokens para layout global, tematização e estruturação básica. Em ambientes sem restrições, isso pode gerar um artefato de “nível de produto”. No entanto, sob limites rigorosos de comprimento de contexto ou tokens máximos, esse comportamento aumenta o risco de falha de emissão parcial: o modelo gasta muito com a arquitetura inicial e nunca chega a um estado final executável. O que você vê à esquerda é efetivamente uma geração truncada, uma interface de usuário não funcional.
O MiniMax M2.1 é otimizado para convergência precoce. Ele minimiza a estrutura especulativa, emite primitivos de interface de usuário funcionais rapidamente e preserva um loop estreito entre instrução e saída. O resultado à direita não é visualmente ambicioso, mas satisfaz o contrato principal: renderização determinística, layout delimitado e interatividade imediata. Em termos de agente, ele atinge um estado final válido com menor variância.
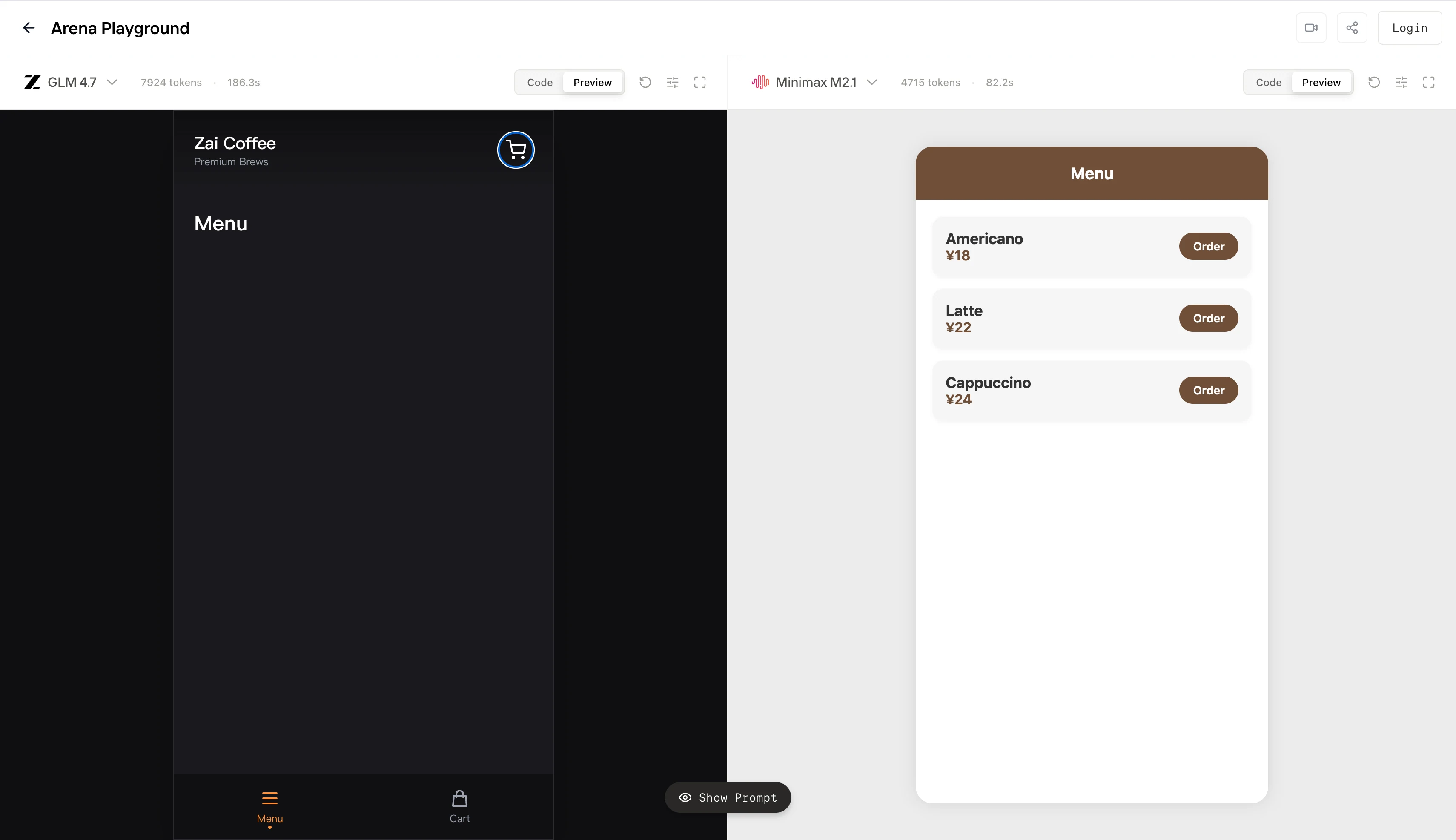
Em resumo, o GLM 4.7 se comporta como um modelo otimizado para completude de design e raciocínio em nível de sistema. O MiniMax M2.1 se comporta como um modelo otimizado para execução delimitada e determinismo de fluxo de trabalho.
Como Usar o GLM 4.7 e o MiniMax M2.1 por um Bom Preço?
Opção 1: Integração Direta de API (Exemplo em Python)
Principais Recursos:
- Endpoint unificado:
/v3/openaisuporta o formato da API de Conclusões de Chat da OpenAI. - Controles flexíveis: Ajuste temperatura, top-p, penalidades e mais para resultados personalizados.
- Streaming e loteamento: Escolha o modo de resposta de sua preferência.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Experimente o GLM 4.7 e o MiniMax M2.1 Agora!
Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multiagente com o SDK OpenAI Agents
Construa sistemas multiagente avançados integrando a Novita AI com o OpenAI Agents SDK:
- Plug-and-play: Use os LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporta transferências, roteamento e uso de ferramentas: Projete agentes que podem delegar, triar ou executar funções, todos alimentados pelos modelos da Novita AI.
- Integração com Python: Aponte o SDK simplesmente para o endpoint da Novita (
https://api.novita.ai/v3/openai) e use sua chave de API.
Opção 3:Conecte a API do GLM 4.7 Flash em Plataformas de Terceiros
- Hugging Face: Use o GLM 4.7 e o MiniMax M2.1 em Spaces, pipelines ou com a biblioteca Transformers por meio dos endpoints da Novita AI.
- Frameworks de Agente e Orquestração: Conecte facilmente a Novita AI a plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
- API Compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline, OpenCode e Cursor, projetadas para o padrão de API da OpenAI.
O GLM 4.7 é otimizado para completude de design, planejamento de longo prazo e raciocínio estruturado, enquanto o MiniMax M2.1 é otimizado para execução delimitada, velocidade e loops de agente determinísticos. A escolha entre o GLM 4.7 e o MiniMax M2.1 não se trata de inteligência bruta, mas se o seu sistema valoriza profundidade arquitetônica ou fechamento confiável de tarefas sob restrições.
Qual modelo é melhor para fluxos de trabalho de agente de longa duração, GLM 4.7 ou MiniMax M2.1? O MiniMax M2.1 é melhor para fluxos de trabalho de agente de longa duração, pois mantém um ritmo estável e execução delimitada, enquanto o GLM 4.7 tende a expandir o escopo e desacelerar com o tempo.
Por que o GLM 4.7 às vezes falha em produzir um resultado executável sob limites de tokens? O GLM 4.7 aloca mais tokens para planejamento e estrutura iniciais, o que aumenta o risco de falha de emissão parcial quando os orçamentos de contexto ou saída são limitados.
O que torna o MiniMax M2.1 mais confiável em ambientes com restrições? O MiniMax M2.1 converge cedo, emite primitivos funcionais rapidamente e preserva a executabilidade, tornando-o mais resiliente sob limites rigorosos de tokens e latência.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construção e escalonamento.



