

يواجه المطورون الذين يبنون سير عمل الوكلاء معضلة متكررة: هل يجب أن يعطوا الأولوية للاستدلال العميق والاكتمال المعماري، أم للتنفيذ السريع والموثوق للمهام ضمن حدود صارمة للرموز والتكاليف؟ يجسد كل من GLM 4.7 و MiniMax M2.1 استراتيجيتي تحسين متعارضتين. يحلل هذا المقال سلوك الوكلاء الخاص بهما عبر الهندسة المعمارية، والمعايير المرجعية، وديناميكيات الاستدلال، وتباين المهام في العالم الحقيقي، لمساعدة المطورين على تحديد أي النموذج يناسب قيود الإنتاج وأهداف سير العمل الخاصة بهم بشكل أفضل.
سلوك الوكلاء في GLM 4.7 و MiniMax M2.1
وصف المؤلف تشغيل كلا النموذجين من خلال مهمة كاملة من البداية إلى النهاية لبناء مشغل مهام CLI مع ميزات متعددة، بما في ذلك مراحل تخطيط الهندسة المعمارية والتنفيذ، حيث أكمل كلا النموذجين جميع المتطلبات دون تدخل بشري. بناءً على هذه التقييمات النوعية، يلخص الجدول التالي أداء كل نموذج عبر الأبعاد الرئيسية لعمل الوكلاء:
| البعد | MiniMax M2.1 | GLM 4.7 | المنطق |
|---|---|---|---|
| التزام بالتعليمات والمحاذاة | 9 | 7 | يُوصف M2.1 بأنه محاذى بإحادة ومقاوم لانزياح النطاق. تميل GLM إلى توسيع النطاق. |
| التخطيط والاستدلال المعماري | 6 | 9 | تتفوق GLM في تصميم الأنظمة والهيكلة طويلة الأمد. M2.1 أكثر تكتيكية. |
| كفاءة التنفيذ | 9 | 6 | M2.1 أسرع وأرخص بشكل كبير. GLM أبطأ وتكلفتها أعلى. |
| متحملية سير العمل | 8 | 6 | يؤدي M2.1 أداءً جيداً في سير عمل الوكلاء الطويلة غير المنقطعة. تتباطأ GLM في مثل هذه الإعدادات. |
| جودة الكود وقابلية الصيانة | 7 | 9 | تنتج GLM تجريدات وهيكلة أنظف. يفضل M2.1 البساطة ولكنه قد يكون خاماً. |
| التوثيق والتواصل | 3 | 9 | ينتج M2.1 وثائق قليلة. تنتج GLM ملفات README غنية ووثائق داخلية. |
| عمق الاستدلال واتساق القواعد | 6 | 9 | GLM أقوى في المنطق المعقد والمجالات الغنية بالقواعد. |
| المبادرة وإدارة النطاق | 9 | 5 | يبقى M2.1 محصوراً في المهمة. غالباً ما تقوم GLM بالهندسة الزائدة وتنحرف. |
يوضح المقارنة أعلاه أن GLM 4.7 و MiniMax M2.1 مبنيان بأهداف مختلفة تماماً. يركز أحدهما على التفكير الأعمق، والهيكلة الأوضح، والتخطيط طويل الأمد. بينما يركز الآخر على السرعة، والتكلفة، والتنفيذ الموثوق للمهام في سير عمل الوكلاء. تشكل هذه الأهداف سلوك كل نموذج، وهي تفسر سبب تسبب نفس المهمة في نتائج مختلفة للغاية.
في الأقسام التالية، يشرح هذا المقال مصدر هذه الاختلافات وما تعنيه في التطبيق العملي، مع تغطية الهندسة المعمارية، والمعايير المرجعية، والكفاءة، والنشر، وحالات استخدام المطورين الواقعية.
هندسة GLM 4.7 و MiniMax M2.1
| المواصفات | GLM 4.7 | MiniMax M2.1 |
|---|---|---|
| نوع الهندسة المعمارية | MoE مع توجيه استدلال نشط 32B نشط | MoE مع تنشيط انتقائي 10B نشط |
| نافذة السياق | 200,000 رمز | 204,800 رمز |
| الحد الأقصى للإخراج | 128,000 رمز | 131,072 رمز |
يستخدم GLM 4.7 مجموعة معلمات نشطة أكبر لتأكيد الاستدلال العميق، والتخطيط، والمخرجات المنظمة. يركز MiniMax M2.1 على التنشيط المتناثر لتقليل الحساب والتكلفة مع الحفاظ على اتباع قوي للتعليمات وسير عمل الوكلاء.
معايير أداء GLM 4.7 و MiniMax M2.1
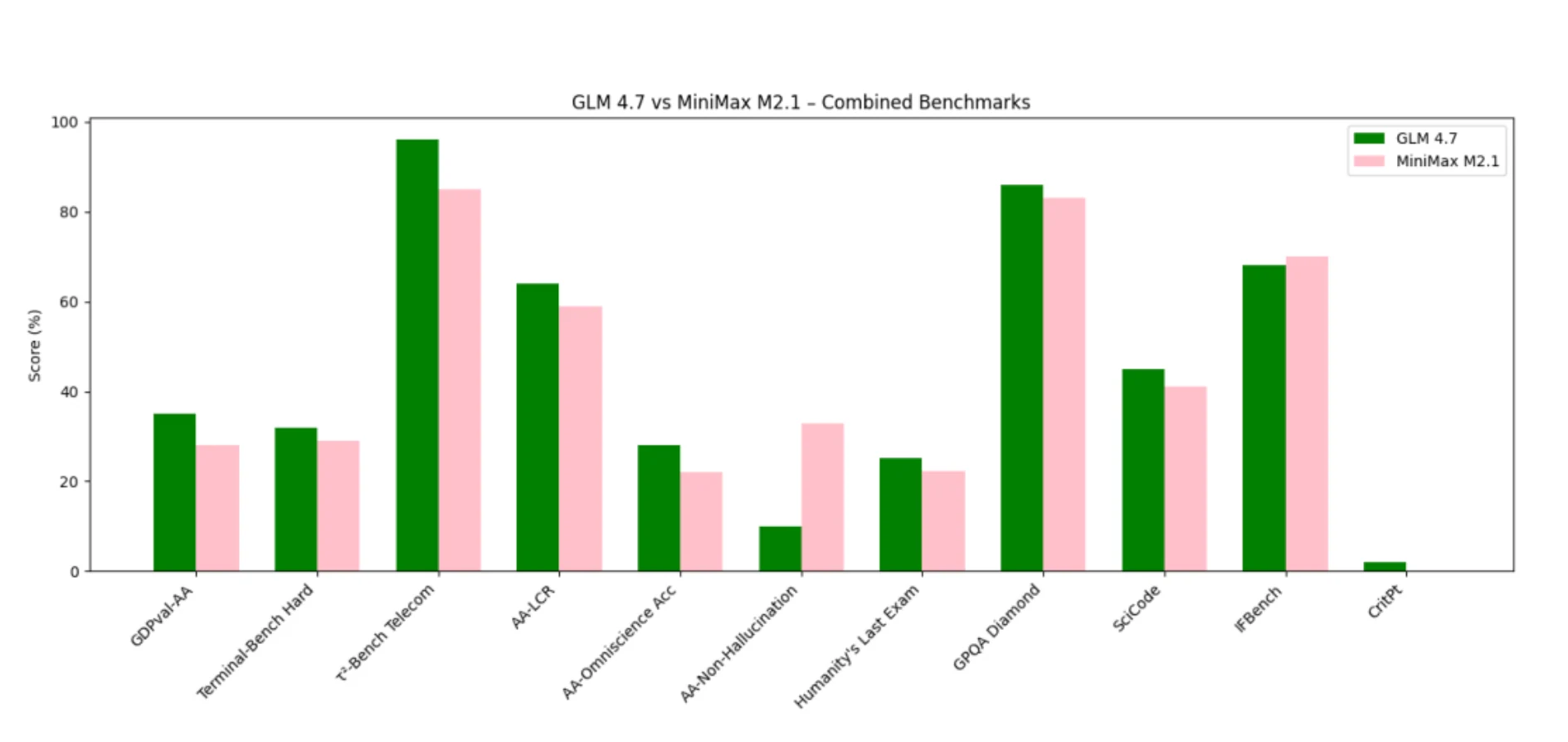
يهيمن GLM 4.7 على المعايير التي تكافئ الاستدلال العميق، تماسك السياق الطويل، والتفكير المنظم للأدوات.
يتفوق MiniMax M2.1 في المعايير المرتبطة بدقة التعليمات، تنفيذ الوكلاء، وسلوك انخفاض الهلوسة.
سرعة الاستدلال لـ GLM 4.7 و MiniMax M2.1
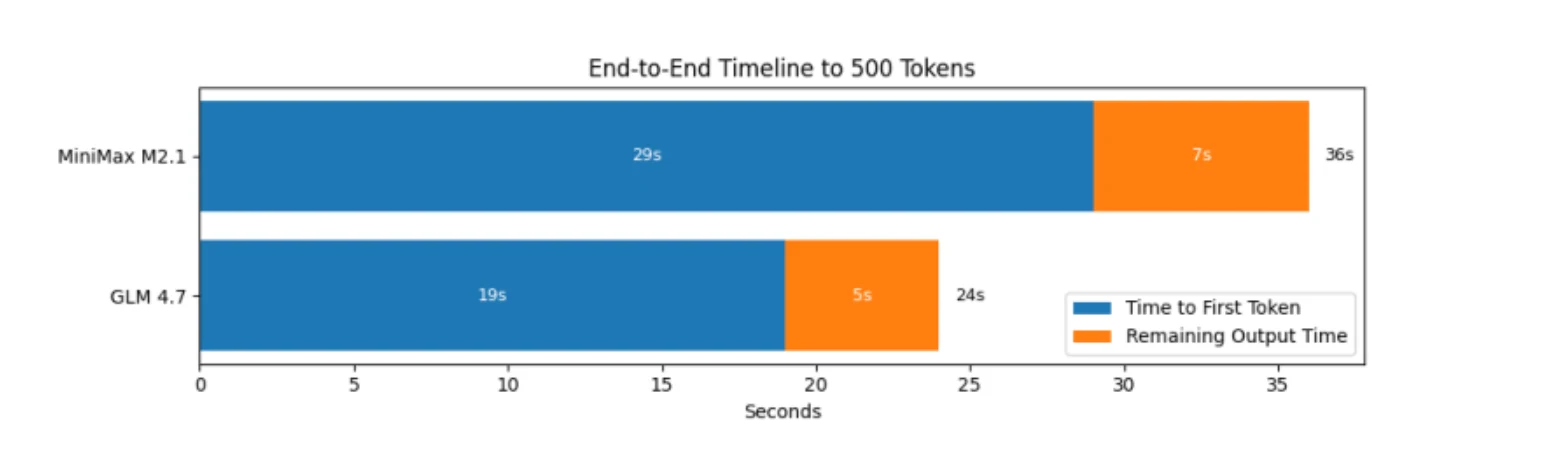
لذا من حيث المعايير، يكون GLM 4.7 أكثر كفاءة في ميكانيكا الاستدلال الخالص: يبدأ في وقت أبكر، ينتج مخرجات أسرع، وينتهي في وقت مبكر.
جرب GLM 4.7 و MiniMax M2.1 الآن!
حيث يكسب MiniMax سمعته “الكفاءة” هو على مستوى سير العمل. في حلقات الوكلاء الحقيقية:
- يميل MiniMax إلى قضاء وقت أقل في مراحل الاستدلال الداخلي الطويلة.
- يحافظ على الخطوات قصيرة ومباشرة.
- يحافظ على وتيرة مستقرة عبر العديد من الأدوار.
كيف تتباعد نفس المهمة بين GLM 4.7 و MiniMax M2.1
الموجه: أريد عرض تجريبي لملف H5 واحد، يتم تسليمه كملف
index.htmlقابل للتشغيل، يحاكي تدفق طلب قهوة كامل للمعاينة والتفاعل. يجب أن تحتوي الصفحة على ثلاث حالات عرض: قائمة تعرض ثلاثة أنواع من القهوة (أمريكانو 18 يوان، لاتيه 22 يوان، كابتشينو 24 يوان) مع أزرار “طلب”؛ عرض تفاصيل المنتج حيث يمكن للمستخدمين تخصيص الحجم، درجة الحرارة، والإضافات مع تحديثات الأسعار في الوقت الفعلي وإجراء “إضافة إلى سلة التسوق” الذي يشغل صوتاً قصيراً ويعرض تأكيداً؛ وعرض سلة التسوق الذي يسرد العناصر المحددة، السعر الإجمالي، وزر “تأكيد الطلب” الذي يولد معرف طلب عشوائي ورمز استلام مكون من 4 أرقام في لوحة تأكيد. يجب أن تكون جميع CSS داخل كتلة<style>، وجميع المنطق داخل كتلة<script>، بدون أطر عمل، حتى يمكن فتح الملف مباشرة في المتصفح. يجب أن يكون التصميم بسيطاً وذو طابع قهوة، مع إعطاء الأولوية لمعاينة واضحة وتفاعلية على التعقيد الإنتاجي.
يظهر GLM 4.7 عبء تخطيط مرتفع. يخصص جزءاً كبيراً من ميزانية الرموز الخاصة به للتخطيط العام، والسمات، والدعم الهيكلي. في البيئات غير المقيدة، يمكن أن ينتج هذا قطعة أثرية من “درجة إنتاجية” أعلى. ولكن تحت حدود صارمة لطول السياق أو الحد الأقصى للرموز، يزيد هذا السلوك من خطر فشل الانبعاث الجزئي: ينفق النموذج بكثرة على الهندسة المعمارية المسبقة ولا يصل أبداً إلى حالة طرفية قابلة للتشغيل. ما تراه على اليسار هو effectively توليد مقطوع، وهي واجهة مستخدم غير وظيفية.
يُحسن MiniMax M2.1 من أجل التقارب المبكر. يقلل من الهيكلة التخمينية، ويبعث عناصر واجهة المستخدم الأساسية العاملة بسرعة، ويحافظ على حلقة ضيقة بين التعليم والمخرج. النتيجة على اليمين ليست طموحة بصرياً، ولكنها تلبي العقد الأساسي: عرض حتمي، تخطيط محدد، وتفاعلية فورية. بمصطلحات الوكلاء، يصل إلى حالة نهاية صالحة مع تباين أقل.
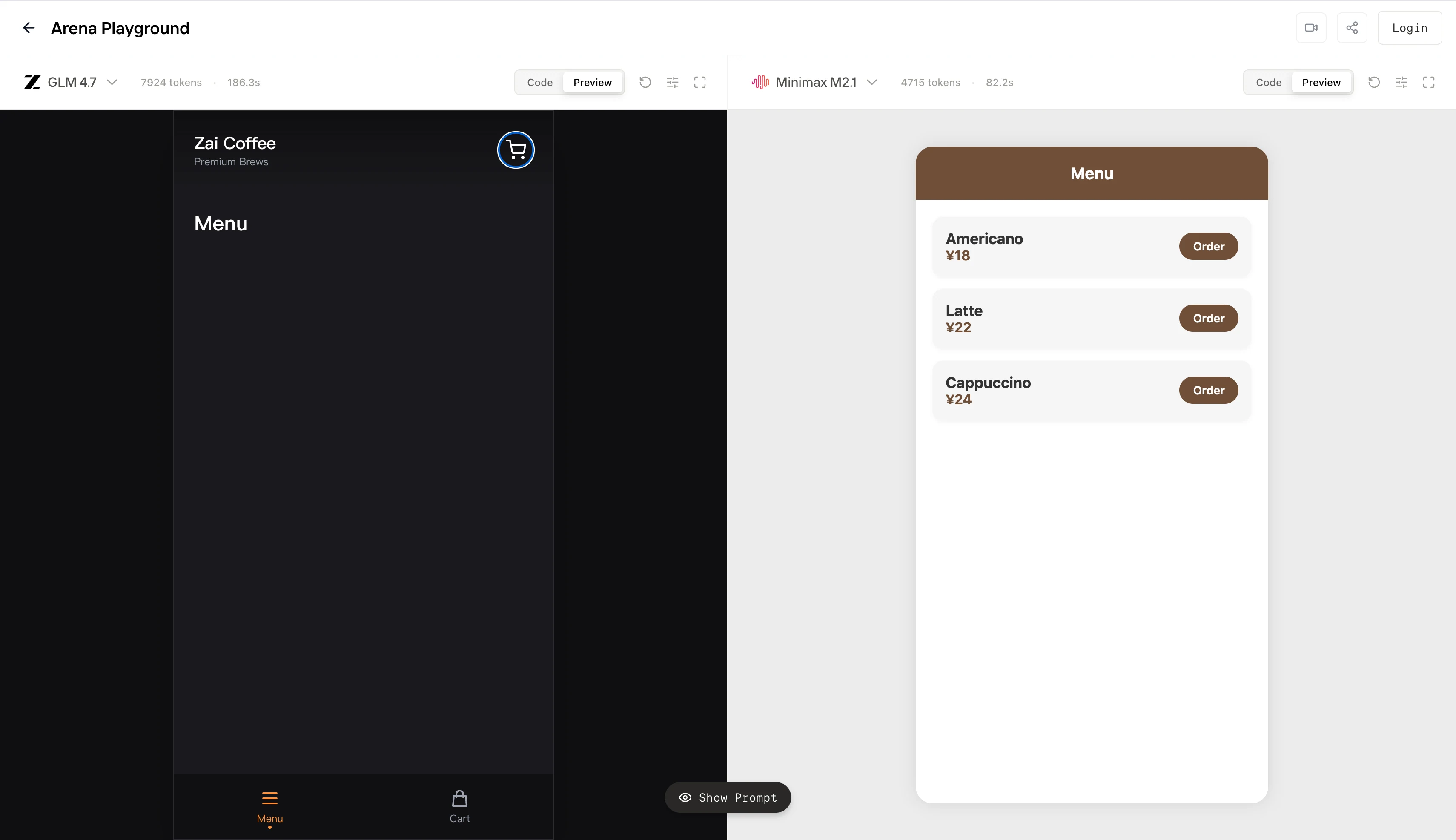
باختصار، يتصرف GLM 4.7 كنموذج مُحسّن من أجل اكتمال التصميم و الاستدلال على مستوى النظام. يتصرف MiniMax M2.1 كنموذج مُحسّن من أجل التنفيذ المحدد و حتمية سير العمل.
كيفية استخدام GLM 4.7 و MiniMax M2.1 بسعر جيد؟
الخيار 1: تكامل API المباشر (مثال بلغة بايثون)
الميزات الرئيسية:
- نقطة نهاية موحدة: يدعم
/v3/openaiتنسيق واجهة برمجة تطبيقات إكمال الدردشة من OpenAI. - تحكمات مرنة: اضبط درجة الحرارة، top-p، العقوبات، والمزيد للحصول على نتائج مخصصة.
- بث وتجميع: اختر وضع الاستجابة المفضل لديك.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

جرب GLM 4.7 و MiniMax M2.1 الآن!
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
الخيار 2: سير عمل الوكلاء المتعددة باستخدام حزمة SDK لوكلاء OpenAI
ابنِ أنظمة وكلاء متقدمة من خلال دمج Novita AI مع حزمة SDK لوكلاء OpenAI:
- التوصيل والتشغيل: استخدم نماذج اللغات الكبيرة من Novita AI في أي سير عمل لوكلاء OpenAI.
- يدعم التسليم، التوجيه، واستخدام الأدوات: صمم وكلاء يمكنهم تفويض المهام، فرزها، أو تشغيل الوظائف، كلها مدعومة بنماذج Novita AI.
- تكامل بايثون: ببساطة وجه حزمة SDK إلى نقطة نهاية Novita (
https://api.novita.ai/v3/openai) واستخدم مفتاح API الخاص بك.
الخيار 3:ربط واجهة برمجة تطبيقات GLM 4.7 Flash على منصات طرف ثالث
- Hugging Face: استخدم GLM 4.7 و MiniMax M2.1 في المساحات، خطوط الأنابيب، أو مع مكتبة Transformers عبر نقاط نهاية Novita AI.
- أطر عمل الوكلاء والتنسيق: اربط Novita AI بسهولة بالمنصات الشريكة مثل Continue، AnythingLLM،LangChain، Dify و Langflow عبر موصلات رسمية وأدلة تكامل خطوة بخطوة.
- واجهة برمجة تطبيقات متوافقة مع OpenAI: استمتع بالهجرة والتكامل بدون متاعب مع أدوات مثل Cline، OpenCode و Cursor، المصممة لمعيار واجهة برمجة تطبيقات OpenAI.
يُحسّن GLM 4.7 من أجل اكتمال التصميم، التخطيط طويل الأمد، والاستدلال المنظم، بينما يُحسّن MiniMax M2.1 من أجل التنفيذ المحدد، السرعة، وحلقات الوكلاء الحتمية. الاختيار بين GLM 4.7 و MiniMax M2.1 لا يتعلق بالذكاء الخام، بل بما إذا كان نظامك يقدر العمق المعماري أو إغلاق المهام الموثوق تحت القيود.
أي النماذج أفضل لسير عمل الوكلاء طويلة الأمد، GLM 4.7 أم MiniMax M2.1؟
MiniMax M2.1 أفضل لسير عمل الوكلاء طويلة الأمد لأنه يحافظ على وتيرة مستقرة وتنفيذ محدد، بينما تميل GLM 4.7 إلى توسيع النطاق والتباطؤ بمرور الوقت.
لماذا يفشل GLM 4.7 أحياناً في إنتاج نتيجة قابلة للتشغيل ضمن حدود الرموز؟
يخصص GLM 4.7 رموزاً أكثر للتخطيط المسبق والهيكلة، مما يزيد من خطر فشل الانبعاث الجزئي عندما يتم تحديد ميزانيات السياق أو المخرجات.
ما الذي يجعل MiniMax M2.1 أكثر موثوقية في البيئات المقيدة؟
يتقارب MiniMax M2.1 مبكراً، ويبعث عناصر أساسية عاملة بسرعة، ويحافظ على القابلية للتنفيذ، مما يجعل MiniMax M2.1 أكثر مرونة تحت حدود صارمة للرموز والكمون.
Novita AI هي منصة سحابة للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.



