

- GLM 4.5V VS Gemma 3 27B: Architecture Comparsion
- GLM 4.5V VS Gemma 3 27B: Benchmark Comparsion
- GLM 4.5V VS Gemma 3 27B: Hardware Comparsion
- GLM 4.5V VS Gemma 3 27B: Pros and Cons
- GLM 4.5V VS Gemma 3 27B: Which Model is Better Suited for QA?
- Novita AI: More Cost-Effectvely and Stable GLM 4.5V API Provider
- Build a Simple Image Recognition Tool using MCP and GLM.
When choosing a large language model for question answering, multimodal tasks, or AI-driven applications, both GLM 4.5V (by Zhipu AI) and Gemma 3 27B (by Google DeepMind) stand out as leading open-source contenders. They differ significantly in architecture, hardware requirements, performance, and deployment flexibility. Understanding these differences helps you pick the right model for your needs—whether it’s cutting-edge accuracy, cost-effective deployment, or multilingual support. You can check the conclusion in the bottom of the article!
GLM 4.5V VS Gemma 3 27B: Architecture Comparsion
| Feature | GLM 4.5V (Zhipu GLM-4.5 Vision) | Gemma 3 (27B) |
|---|---|---|
| Developer | Zhipu AI | Google DeepMind |
| Architecture | Mixture-of-Experts (MoE) transformer 106B total parameters, only ~12B activated per input | Dense Transformer 27B parameters, all activated for every input |
| Multimodal Capability | Vision-Language Model (VLM): accepts images + text as input, outputs text | Multimodal: accepts images + text as input, outputs text |
| Parameter Count | 106 billion (sparse, ~12B per query) | 27 billion (dense, all active) |
| Context Window | 128K tokens | 128K tokens (on 4B/12B/27B models) |
| Expert Mechanism | MoE: specialist subnetworks (“experts”) for different tasks, routed by a gating network | No expert mechanism: standard dense transformer |
| Reasoning/Response Modes | “Agent-native” architecture: hybrid thinking (complex reasoning) and immediate response modes | Standard transformer reasoning |
| Function Calling/Tools | Built-in function calling: can autonomously use code/web tools | No explicit function calling built-in |
| Multilingual Support | Multilingual (number not specified) | Native support for 140+ languages |
| Training Data | Not fully disclosed (emphasizes large-scale multimodal data) | 14 trillion tokens (text, code, math, millions of images) |
| Optimization Focus | Sparsity, efficiency, massive knowledge, multimodal reasoning, tool use | Portability, versatility, long context, multilingual, single-accelerator deployment |
| Open Source | Yes | Yes |
| Typical Applications | Complex reasoning, multimodal understanding, autonomous tool use (code, search), long document analysis | Multilingual/multimodal chat, text and image understanding, long-context handling, lightweight deployment |
GLM 4.5V focuses on sparsity (MoE), expert specialization, efficient compute, and tool use, making it suitable for complex multimodal reasoning and long-context tasks. Gemma 3 27B features a dense, portable, and multilingual architecture with strong long-context and multimodal capabilities, designed to be efficient and versatile for a wide range of deployments.
GLM 4.5V VS Gemma 3 27B: Benchmark Comparsion
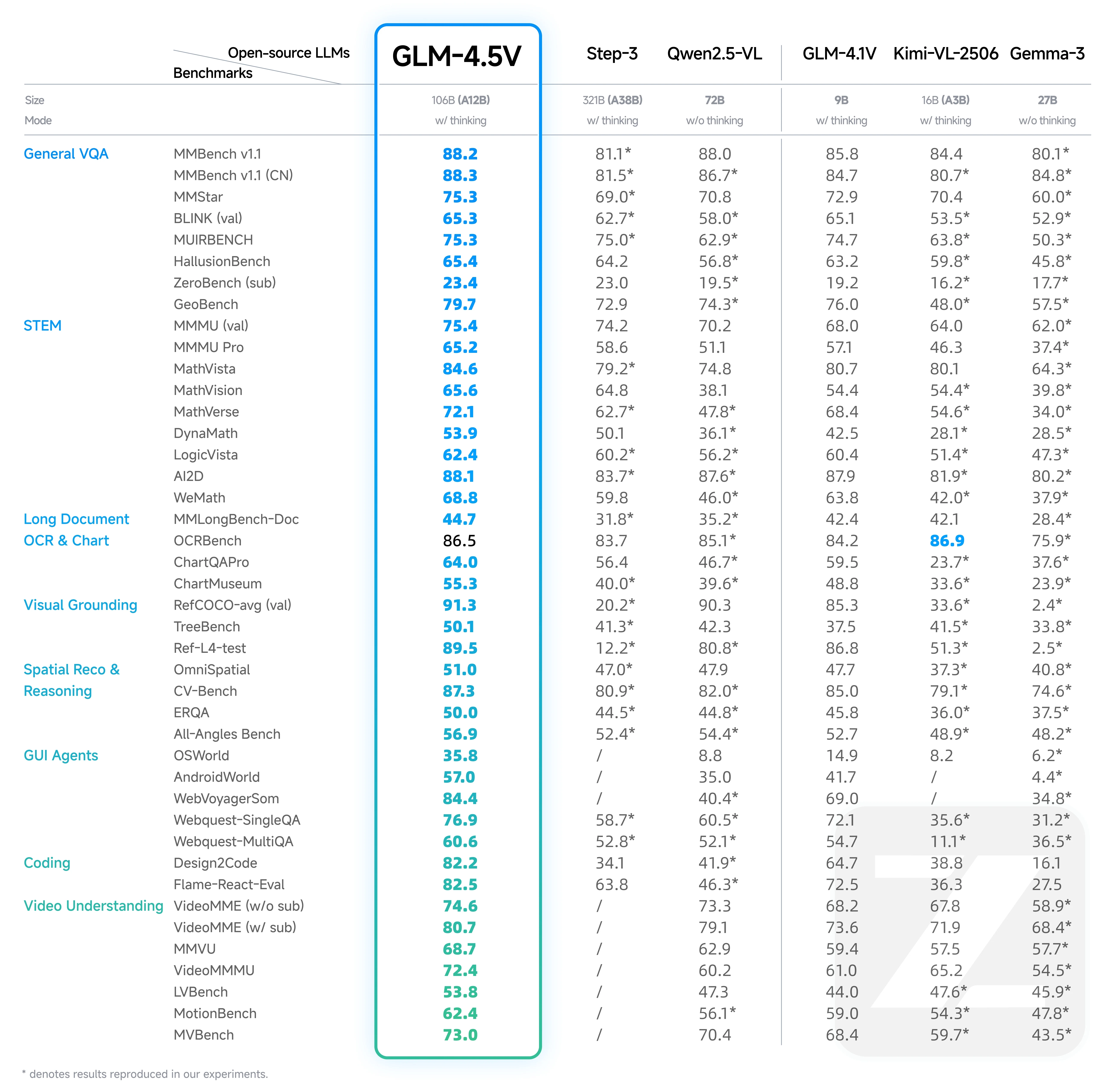
From Hugging Face
Gemma-3 27B lags behind all top-tier models (especially GLM-4.5V and Qwen2.5-VL) across almost every major task, including VQA, STEM reasoning, OCR, code, and video understanding.
Even when compared to smaller models like GLM-4.1V and Kimi-VL-2506, Gemma-3 rarely leads and often falls behind, especially in advanced multimodal tasks.
The main reason is Gemma-3’s dense transformer architecture without expert specialization, making it less competitive on challenging multimodal and reasoning benchmarks.
GLM 4.5V VS Gemma 3 27B: Hardware Comparsion
GLM-4.5V Model:
-
Model Parameters: 106 billion (Mixture of Experts, approximately 12 billion active during inference).
-
Inference Hardware Requirements:
- Recommended: 8× NVIDIA H100 GPUs (FP16 precision).
- Alternative configurations:
- 4× H100 GPUs (Air/quantized version, FP16).
- 2× H100 GPUs (FP8 quantization).
-
Inference VRAM Requirements (FP16):
- Full model: Approximately 16× H100 GPUs, each with 80GB VRAM.
- Air version:
- 4× H100 GPUs (FP16).
- 2× H100 GPUs (8-bit/FP8).
- While the VRAM requirement is lower than that of dense models exceeding 100 billion parameters, it remains substantial.
Gemma 3 27B Model:
-
Model Parameters: 27 billion (Dense).
-
Inference Hardware Requirements:
- Single GPU with 48GB VRAM (FP16 precision).
- Consumer-grade GPUs (with 4-bit quantization).
-
Inference VRAM Requirements (FP16):
- Single 48GB GPU (FP16).
- Through quantization techniques, the Gemma 3 27B model’s VRAM requirement can be reduced from 54GB (BF16) to 14.1GB (int4), enabling it to run on consumer GPUs like the NVIDIA RTX 3090.
GLM 4.5V VS Gemma 3 27B: Pros and Cons
| Dimension | GLM 4.5V Pros | GLM 4.5V Cons | Gemma 3 27B Pros | Gemma 3 27B Cons |
|---|---|---|---|---|
| Performance | State-of-the-art, near GPT-4 on benchmarks - Excels in reasoning, coding, comprehension | Very high hardware requirements | Excellent performance for its size, cost-effective | Cannot match very large models (e.g., GLM-4.5/GPT-4) on hardest tasks |
| Architecture | Mixture-of-Experts: specialization, faster per-token inference | Complex design, harder to fine-tune/debug | Dense model, easy to use/deploy | No MoE/experts, less efficient for highly diverse domains |
| Context Length | 128K long context for lengthy docs/conversations | 128K context window, great for long docs/convos | ||
| Multimodal Capability | Native vision+language, strong on multimodal tasks | Natively supports image/text, multimodal out-of-the-box | ||
| Tool Use / Reasoning | Built-in tool use, “thinking mode,” great for agents and complex QA | Potential expertise mismatch if gating fails | Supports function calling, OpenAI API compatible | Fewer agentic features, needs external orchestration for tool use |
GLM 4.5V VS Gemma 3 27B: Which Model is Better Suited for QA?

Novita AI: More Cost-Effectvely and Stable GLM 4.5V API Provider
Novita AI’s GLM-4.5V API offers 65.5K context, with input priced at $0.60/1K tokens, output at $1.80/1K tokens, and function calling and structured outputs supported.
Novita AI’s Gemma 3 27B API offers 32K context, with input priced at $0.119/1K tokens, output at $0.2/1K tokens, and structured outputs supported.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Try GLM4.5V and Gemma 3 27B Now!
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.

Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Build a Simple Image Recognition Tool using MCP and GLM.
If you want to leverage the capabilities of GLM—such as building a simple image recognition tool to demonstrate its integration of visual recognition and reasoning—you can use the MCP functionality supported by Novita AI. Below is the sample code:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")GLM 4.5V is ideal if you need state-of-the-art performance on complex reasoning, large-scale multimodal understanding, long-document QA, or agent-style tool use—and have access to high-end multi-GPU servers. Its Mixture-of-Experts (MoE) architecture gives it an edge on the very hardest tasks.
Gemma 3 27B excels in real-world practicality: it’s easy to deploy on a single GPU or even consumer hardware, supports 140+ languages, offers great performance for its size, and is cost-effective for most everyday applications.
For most enterprise, R&D, or production QA/chatbot systems, Gemma 3 27B is “good enough” and much easier to manage. If you only occasionally need absolute best-in-class accuracy on the toughest queries (and can justify the hardware expense), consider GLM 4.5V; otherwise, Gemma remains a top choice for efficiency and versatility.
Should I upgrade from Gemma 3 27B to GLM 4.5V?
Only if you truly need maximum performance for highly complex, multi-hop QA, or advanced multimodal tasks—and are willing to invest in significantly more compute resources. For most users and most applications, Gemma 3 27B is already excellent.
What’s the main difference in architecture?
GLM 4.5V uses a Mixture-of-Experts (MoE) architecture, activating specialized subnetworks for different tasks, enabling greater accuracy on the hardest problems. Gemma 3 27B is a traditional dense transformer—simpler, more portable, but less specialized.
Where is GLM 4.5V a better fit?
When you need the best possible accuracy for expert-level QA, complex reasoning, or large-scale vision-language applications—and have the hardware to support it.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



