

Points clés
Aperçu du modèle
Llama 3.3 70B est conçu pour des tâches multilingues variées, avec un accent sur le suivi d’instructions et le codage
Gemma 2 9B est un modèle plus petit et léger, optimisé pour les environnements aux ressources limitées
Différences principales
Architecture : Llama 3.3 70B et Gemma 2 9B utilisent tous deux une architecture Transformer avec GQA.
Paramètres : Llama 3.3 70B possède 70 milliards de paramètres, Gemma 2 9B en a 9 milliards
Fenêtre de contexte : Llama 3.3 70B supporte 128 000 tokens, Gemma 2 9B en supporte 8 000
Performances
Llama 3.3 70B montre des performances supérieures sur les benchmarks MMLU, HumanEval et MATH
Support linguistique
Llama 3.3 70B prend en charge 8 langues : anglais, allemand, français, italien, portugais, hindi, espagnol et thaï
Gemma 2 9B est principalement basé sur l’anglais
Configuration matérielle requise
Llama 3.3 70B fonctionne sur des GPU courants et des postes de développeurs
Gemma 2 9B convient aux environnements aux ressources limitées comme les ordinateurs portables et de bureau
Cas d’utilisation
Llama 3.3 70B : chatbots multilingues, assistance au codage, génération de données synthétiques
Gemma 2 9B : tâches de génération de texte, environnements aux ressources limitées
Si vous souhaitez évaluer Llama 3.3 70B et Gemma 2 9B sur vos propres cas d’usage — Après inscription, Novita AI vous offre un crédit de 0,5 $ pour commencer !
Llama 3.3 70B et Gemma 2 9B sont tous deux de puissants modèles de langage, mais ils diffèrent considérablement par leur architecture, leurs performances et leurs cas d’usage. Cet article propose une comparaison pratique et technique pour aider les développeurs à prendre des décisions éclairées selon leurs besoins spécifiques.
Introduction basique des modèles
Pour commencer notre comparaison, examinons d’abord les caractéristiques fondamentales de chaque modèle.
Llama 3.3 70b
- Date de sortie : 6 décembre 2024
- Échelle du modèle :
- Caractéristiques principales :
- Modèle textuel uniquement, optimisé pour les instructions
- Utilise l’attention groupée par requête (GQA) pour une meilleure efficacité
- Optimisé pour le dialogue multilingue et diverses tâches textuelles
- Prend en charge l’anglais, l’allemand, le français, l’italien, le portugais, l’hindi, l’espagnol et le thaï
Gemma 2 9B
- Date de sortie : 27 juin 2024
- Échelle du modèle :
- Caractéristiques principales :
- Entraîné à partir du modèle plus grand (27B)
- Modèle texte-texte uniquement (decoder-only)
- Conçu pour diverses tâches de génération de texte
- Utilise l’attention groupée par requête (GQA) pour une meilleure efficacité
- Principalement basé sur l’anglais
Comparaison des modèles
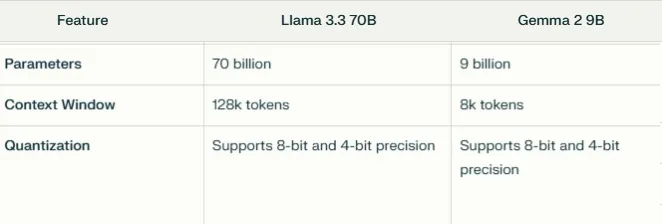
- Taille du modèle et paramètres : Llama 3.3 70B est nettement plus gros avec 70 milliards de paramètres, contre 9 milliards pour Gemma 2 9B.
- Taille de la fenêtre de contexte : Llama 3.3 70B peut traiter des contextes allant jusqu’à 128 000 tokens, tandis que Gemma 2 9B est limité à 8 000 tokens.
- Options de quantification : Les deux modèles supportent la précision 8 bits et 4 bits, mais Llama 3.3 70B offre des options supplémentaires (2,25 bpw, 4,65 bpw) pour une meilleure flexibilité matérielle et la gestion de contextes plus longs (28 000 tokens sur un GPU 24 Go).
- Cas d’utilisation : Gemma 2 9B est mieux adapté aux environnements aux ressources limitées comme les ordinateurs portables, tandis que Llama 3.3 70B, qui nécessite du matériel plus puissant, excelle dans les tâches complexes, les applications multilingues et le traitement de longs textes.
Comparaison de vitesse
Si vous souhaitez tester par vous-même, vous pouvez lancer un essai gratuit sur le site Novita AI.
Comparaison de vitesse
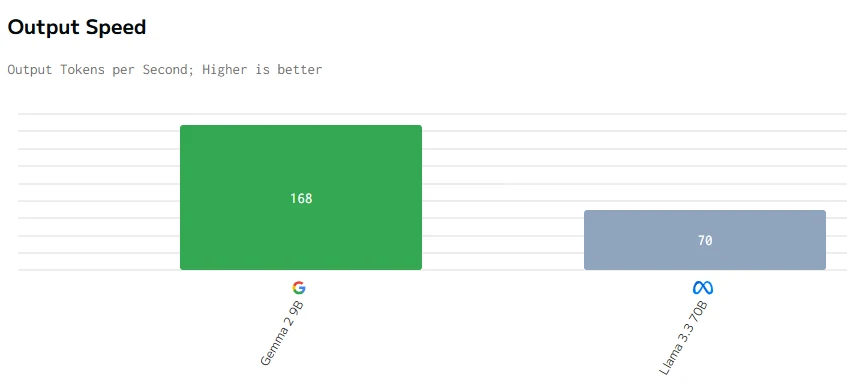
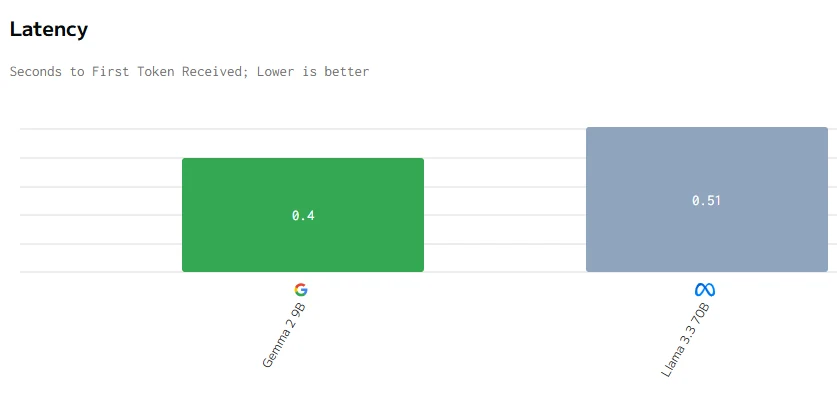
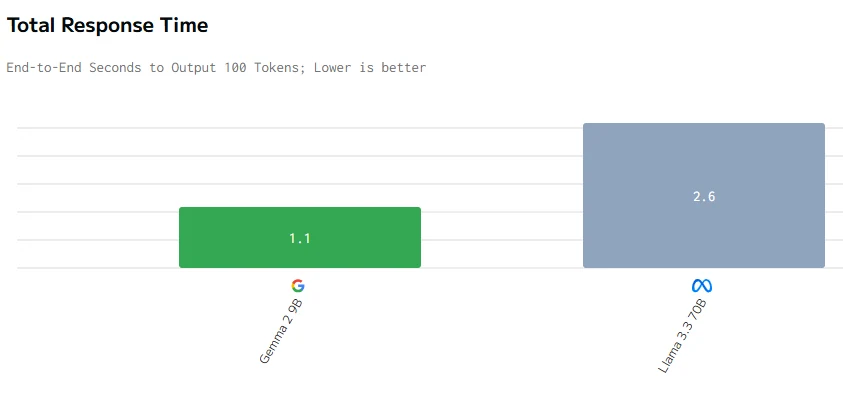
source : artificialanalysis
Comparaison des coûts
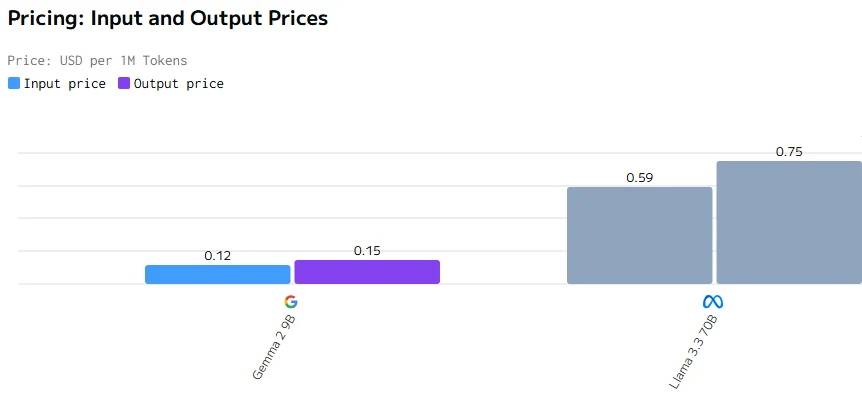
En conclusion, bien que Gemma 2 9B soit plus petit avec 9 milliards de paramètres, il surpasse Llama 3.3 70B en termes de prix, de latence, de vitesse de sortie et de temps de réponse. Cela est probablement dû à une meilleure optimisation, une architecture plus efficace et un déploiement matériel potentiellement mieux adapté, démontrant qu’une taille plus petite ne limite pas nécessairement les performances.
Comparaison des benchmarks
Maintenant que nous avons établi les caractéristiques de base de chaque modèle, examinons leurs performances sur différents benchmarks. Cette comparaison aidera à illustrer leurs forces dans différents domaines.

Llama 3.3 70B excelle dans de multiples tâches, surpassant Gemma 2 9B en codage, résolution de problèmes mathématiques complexes, et démontre de solides capacités multilingues dans les tests MMLU et MGSM. Ses performances montrent une polyvalence et une robustesse dans divers domaines.
Si vous souhaitez en savoir plus sur les connaissances du benchmark llama3.3, vous pouvez consulter cet article :
Pour voir d’autres comparaisons entre llama 3.3 et d’autres modèles, consultez ces articles :
- Qwen 2.5 72b vs Llama 3.3 70b : Quel modèle correspond à vos besoins ?
- Llama 3.1 70b vs. Llama 3.3 70b : Meilleures performances, prix plus élevé
- Llama 3.3 70B est-il vraiment comparable à Llama 3.1 405B ?
Applications et cas d’utilisation
Llama 3.3 70B
- Chatbots et assistants multilingues
- Assistance au codage et développement logiciel
- Génération de données synthétiques
- Création de contenu multilingue et localisation
- Recherche et expérimentation
- Applications basées sur la connaissance
- Déploiement flexible pour les petites équipes
Gemma 2 9B
- Tâches de génération de texte (résumé, réponse aux questions, raisonnement)
- Environnements aux ressources limitées
Accessibilité et déploiement via Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Lancez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page Settings, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Obtenez la clé API Novita AI en vous référant à : https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<VOTRE Clé API Novita AI>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # ou False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Agissez comme un assistant serviable.",
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Après inscription, Novita AI offre un crédit de 0,5 $ pour démarrer !
Si les crédits gratuits sont épuisés, vous pouvez payer pour continuer à utiliser.
Llama 3.3 70B est un modèle performant qui excelle dans diverses tâches, notamment les applications multilingues et le codage. Son efficacité sur du matériel standard le rend attractif pour de nombreux développeurs. Gemma 2 9B, avec sa taille plus petite, offre une solution légère et économique pour les tâches de génération de texte, particulièrement utile dans les environnements aux ressources limitées.
Le choix entre ces deux modèles dépend des exigences spécifiques du projet. Llama 3.3 70B est mieux adapté aux tâches complexes, variées et multilingues, tandis que Gemma 2 9B est préférable lorsque les ressources ou le budget sont limités.
Questions fréquemment posées
Quelles sont les principales différences entre Llama 3.3 70B et Claude 3.5 Sonnet ?
Llama 3.3 70B est un modèle textuel uniquement, axé sur l’efficacité et l’accessibilité, tandis que Claude 3.5 Sonnet est un modèle multimodal qui excelle dans le raisonnement, le codage et les tâches visuelles.
Quel modèle est le meilleur pour le codage ?
Les deux modèles sont compétents en codage, mais Claude 3.5 Sonnet possède des capacités de pointe dans ce domaine. Llama 3.3 démontre également de solides performances en codage.
Llama 3.3 peut-il fonctionner sur mon ordinateur portable ?
Oui, Llama 3.3 est conçu pour fonctionner sur du matériel de développeur courant, ce qui le rend accessible aux petites équipes.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions en IA. API intégrées, serverless, GPU Instance — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



