

Aspectos clave
Resumen del modelo
Llama 3.3 70B está diseñado para tareas multilingües amplias, con énfasis en el seguimiento de instrucciones y la codificación.
Gemma 2 9B es un modelo ligero más pequeño, optimizado para entornos con recursos limitados.
Diferencias principales
Arquitectura: tanto Llama 3.3 70B como Gemma 2 9B usan Transformer con GQA.
Parámetros: Llama 3.3 70B tiene 70 mil millones de parámetros, Gemma 2 9B tiene 9 mil millones.
Ventana de contexto: Llama 3.3 70B admite 128k tokens, Gemma 2 9B admite 8k tokens.
Rendimiento
Llama 3.3 70B muestra un rendimiento superior en los benchmarks MMLU, HumanEval y MATH.
Idiomas compatibles
Llama 3.3 70B admite 8 idiomas: inglés, alemán, francés, italiano, portugués, hindi, español y tailandés.
Gemma 2 9B está basado principalmente en inglés.
Requisitos de hardware
Llama 3.3 70B funciona en GPUs comunes y estaciones de trabajo de desarrolladores.
Gemma 2 9B es adecuado para entornos con recursos limitados, como portátiles y ordenadores de sobremesa.
Casos de uso
Llama 3.3 70B: chatbots multilingües, asistencia en codificación, generación de datos sintéticos.
Gemma 2 9B: tareas de generación de texto, entornos con recursos limitados.
Si estás evaluando Llama 3.3 70B y Gemma 2 9B para tus propios casos de uso, al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
Llama 3.3 70B y Gemma 2 9B son modelos de lenguaje grandes y potentes, pero difieren significativamente en arquitectura, rendimiento y casos de uso previstos. Este artículo ofrece una comparación práctica y técnica para ayudar a los desarrolladores a tomar decisiones informadas según sus necesidades específicas.
Introducción básica del modelo
Para comenzar nuestra comparación, primero conocemos las características fundamentales de cada modelo.
Llama 3.3 70b
- Fecha de lanzamiento: 6 de diciembre de 2024
- Escala del modelo:
- Características clave:
- Modelo de solo texto ajustado por instrucciones
- Utiliza Grouped-Query Attention (GQA) para mejorar la eficiencia
- Optimizado para diálogos multilingües y diversas tareas basadas en texto
- Compatible con inglés, alemán, francés, italiano, portugués, hindi, español y tailandés
Gemma 2 9B
- Fecha de lanzamiento: 27 de junio de 2024
- Escala del modelo:
- Características clave:
- Entrenado a partir del modelo más grande (27B).
- Modelo de texto a texto solo decodificador
- Diseñado para diversas tareas de generación de texto
- Utiliza Grouped-Query Attention (GQA) para mejorar la eficiencia
- Principalmente basado en inglés
Comparación de modelos
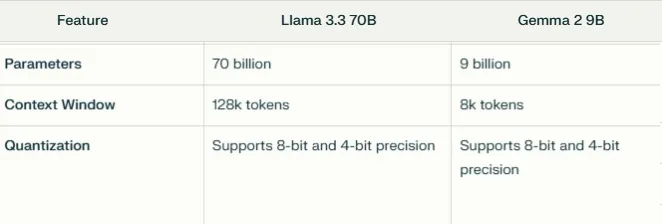
-
Tamaño del modelo y parámetros: Llama 3.3 70B es significativamente más grande, con 70 mil millones de parámetros, frente a los 9 mil millones de Gemma 2 9B.
-
Tamaño de la ventana de contexto: Llama 3.3 70B puede manejar contextos de hasta 128k tokens, mientras que Gemma 2 9B está limitado a 8k tokens.
-
Opciones de cuantización: Ambos modelos admiten precisión de 8 y 4 bits, pero Llama 3.3 70B ofrece opciones adicionales (2,25 bpw, 4,65 bpw) para una mayor flexibilidad de hardware y manejo de contextos más grandes (28.000 tokens en una GPU de 24 GB).
-
Casos de uso: Gemma 2 9B es más adecuado para entornos con recursos limitados como portátiles, mientras que Llama 3.3 70B, que requiere hardware más potente, destaca en tareas complejas, aplicaciones multilingües y procesamiento de textos largos.
Comparación de velocidad
Si quieres probarlo tú mismo, puedes iniciar una prueba gratuita en el sitio web de Novita AI.
Comparación de velocidad
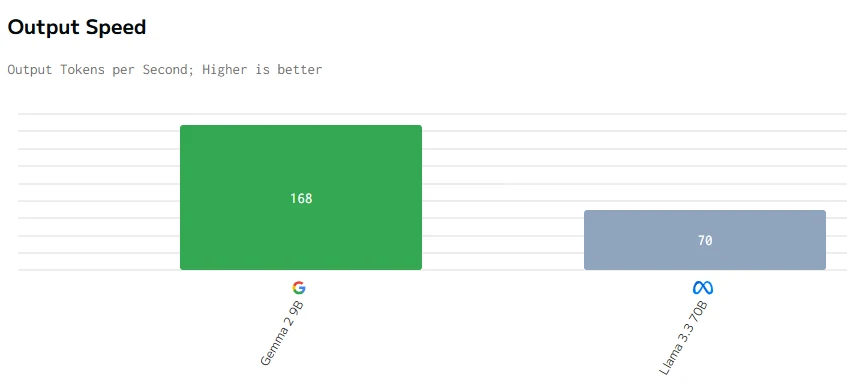
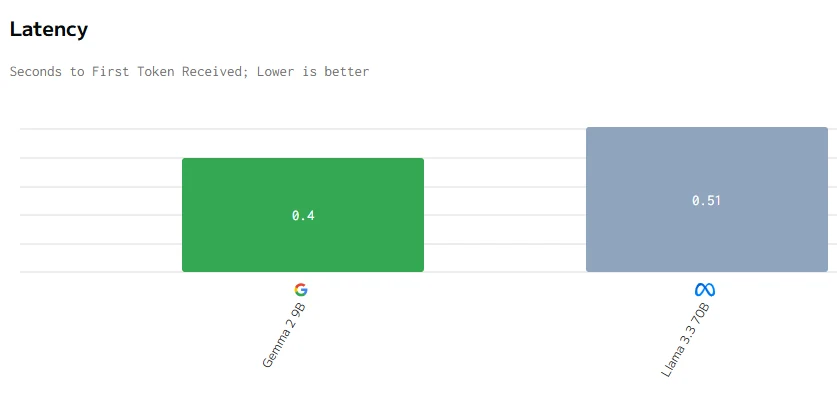
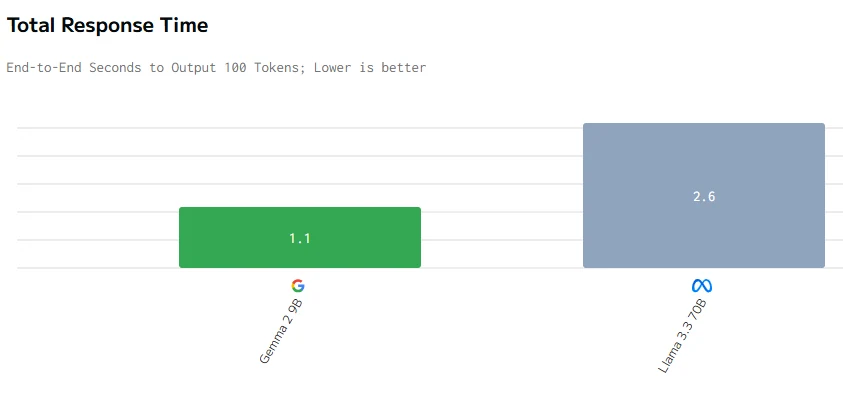
fuente de artificialanalysis
Comparación de costos
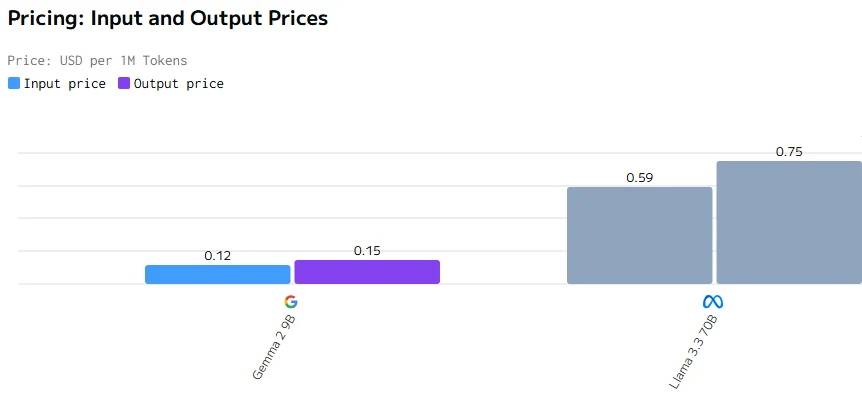
En conclusión, a pesar de que Gemma 2 9B es más pequeño con 9 mil millones de parámetros, supera a Llama 3.3 70B en precio, latencia, velocidad de salida y tiempo de respuesta. Esto probablemente se debe a una mejor optimización, una arquitectura más eficiente y un despliegue de hardware potencialmente más efectivo, demostrando que un tamaño menor no limita necesariamente el rendimiento.
Comparación de benchmarks
Ahora que hemos establecido las características básicas de cada modelo, profundicemos en su rendimiento en varios benchmarks. Esta comparación ayudará a ilustrar sus fortalezas en diferentes áreas.

Llama 3.3 70B sobresale en múltiples tareas, superando a Gemma 2 9B en codificación, resolución de problemas matemáticos complejos y mostrando sólidas capacidades multilingües en las pruebas MMLU y MGSM. Su rendimiento demuestra versatilidad y solidez en diversos dominios.
Si deseas obtener más información sobre el benchmark de Llama 3.3, puedes consultar este artículo:
Si quieres ver más comparaciones entre Llama 3.3 y otros modelos, puedes consultar estos artículos:
- Qwen 2.5 72b vs Llama 3.3 70b: ¿Qué modelo se adapta a tus necesidades?
- Llama 3.1 70b vs. Llama 3.3 70b: Mejor rendimiento, mayor precio
- ¿Es Llama 3.3 70B realmente comparable a Llama 3.1 405B?
Aplicaciones y casos de uso
Llama 3.3 70B
- Chatbots y asistentes multilingües
- Asistencia en codificación y desarrollo de software
- Generación de datos sintéticos
- Creación y localización de contenido multilingüe
- Investigación y experimentación
- Aplicaciones basadas en conocimiento
- Despliegue flexible para equipos pequeños
Gemma 2 9B
- Tareas de generación de texto (resumen, respuesta a preguntas, razonamiento)
- Entornos con recursos limitados
Accesibilidad e implementación a través de Novita AI
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página Settings y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Obtén la clave API de Novita AI consultando: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<TU Clave API de Novita AI>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # o False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Actúa como si fueras un asistente útil.",
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
Si el crédito gratuito se agota, puedes pagar para continuar usándolo.
Llama 3.3 70B es un modelo de alto rendimiento que destaca en diversas tareas, incluyendo aplicaciones multilingües y codificación. Su eficiencia en hardware estándar lo hace atractivo para muchos desarrolladores. Gemma 2 9B, con su tamaño más pequeño, ofrece una solución ligera y rentable para tareas de generación de texto, especialmente útil en entornos con recursos limitados.
La elección entre estos dos modelos depende de los requisitos específicos del proyecto. Llama 3.3 70B es más adecuado para tareas complejas, variadas y multilingües, mientras que Gemma 2 9B es preferible cuando los recursos o el presupuesto son limitados.
Preguntas frecuentes
¿Cuáles son las diferencias clave entre Llama 3.3 70B y Claude 3.5 Sonnet?
Llama 3.3 70B es un modelo de solo texto centrado en la eficiencia y accesibilidad, mientras que Claude 3.5 Sonnet es un modelo multimodal que destaca en razonamiento, codificación y tareas visuales.
¿Qué modelo es mejor para codificar?
Ambos modelos son competentes en codificación, pero Claude 3.5 Sonnet tiene capacidades de vanguardia en esta área. Llama 3.3 también muestra un sólido rendimiento en codificación.
¿Puede Llama 3.3 ejecutarse en mi portátil?
Sí, Llama 3.3 está diseñado para funcionar en hardware común de desarrollador, lo que lo hace accesible para equipos pequeños.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancia de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



