

Principais Destaques
Visão Geral do Modelo
Llama 3.3 70B é projetado para tarefas multilíngues amplas, com ênfase em seguir instruções e codificação
Gemma 2 9B é um modelo menor e leve, otimizado para ambientes com recursos limitados
Diferenças Principais
Arquitetura: Llama 3.3 70B e Gemma 2 9B ambos usam Transformer com GQA.
Parâmetros: Llama 3.3 70B tem 70 bilhões de parâmetros, Gemma 2 9B tem 9 bilhões
Janela de Contexto: Llama 3.3 70B suporta 128k tokens, Gemma 2 9B suporta 8k tokens
Desempenho
Llama 3.3 70B mostra desempenho superior nos benchmarks MMLU, HumanEval e MATH
Suporte a Idiomas
Llama 3.3 70B suporta 8 idiomas, incluindo inglês, alemão, francês, italiano, português, hindi, espanhol e tailandês
Gemma 2 9B é principalmente baseado em inglês
Requisitos de Hardware
Llama 3.3 70B roda em GPUs comuns e estações de trabalho de desenvolvedores
Gemma 2 9B é adequado para ambientes com recursos limitados, como laptops e desktops
Casos de Uso
Llama 3.3 70B: Chatbots multilíngues, suporte a codificação, geração de dados sintéticos
Gemma 2 9B: Tarefas de geração de texto, ambientes com recursos limitados
Se você está procurando avaliar o Llama 3.3 70b e o Gemma 2 9B em seus próprios casos de uso — Ao se registrar, a Novita AI fornece um crédito de $0,5 para você começar!
Llama 3.3 70B e Gemma 2 9B são ambos modelos de linguagem grandes poderosos, mas diferem significativamente em sua arquitetura, desempenho e casos de uso pretendidos. Este artigo fornece uma comparação prática e técnica para ajudar desenvolvedores a tomar decisões informadas para suas necessidades específicas.
Introdução Básica do Modelo
Para começar nossa comparação, primeiro entendemos as características fundamentais de cada modelo.
Llama 3.3 70b
- Data de Lançamento: 6 de dezembro de 2024
- Escala do Modelo:
- Principais Características:
- Modelo somente texto ajustado por instruções
- Utiliza Grouped-Query Attention (GQA) para eficiência melhorada
- Otimizado para diálogo multilíngue e várias tarefas baseadas em texto
- Suporta inglês, alemão, francês, italiano, português, hindi, espanhol e tailandês
Gemma 2 9B
- Data de Lançamento: 27 de junho de 2024
- Escala do Modelo:
- Principais Características:
- Treinado a partir do modelo maior (27B).
- Modelo texto-para-texto somente decodificador
- Projetado para várias tarefas de geração de texto
- Utiliza Grouped-Query Attention (GQA) para eficiência melhorada
- Principalmente baseado em inglês
Comparação de Modelos
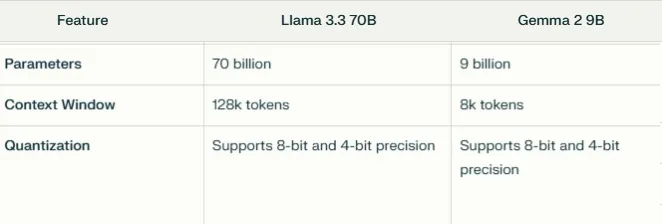
-
Tamanho e Parâmetros do Modelo: Llama 3.3 70B é significativamente maior com 70 bilhões de parâmetros, comparado aos 9 bilhões de parâmetros do Gemma 2 9B.
-
Tamanho da Janela de Contexto: Llama 3.3 70B pode lidar com contextos de até 128k tokens, enquanto Gemma 2 9B está limitado a 8k tokens.
-
Opções de Quantização: Ambos os modelos suportam precisão de 8 bits e 4 bits, mas Llama 3.3 70B oferece opções adicionais (2,25 bpw, 4,65 bpw) para melhor flexibilidade de hardware e lidar com contextos maiores (28.000 tokens em uma GPU de 24GB).
-
Casos de Uso: Gemma 2 9B é mais adequado para ambientes com recursos limitados, como laptops, enquanto Llama 3.3 70B, exigindo hardware mais potente, se destaca em tarefas complexas, aplicações multilíngues e processamento de texto longo.
Comparação de Velocidade
Se você quiser testar por conta própria, pode iniciar um teste gratuito no site da Novita AI.
Comparação de Velocidade
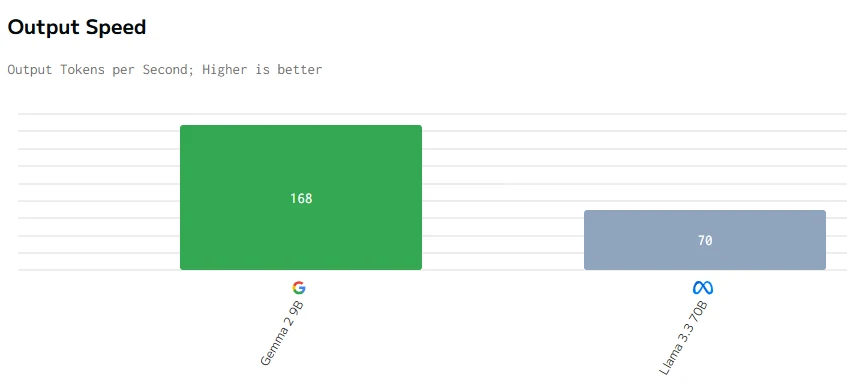
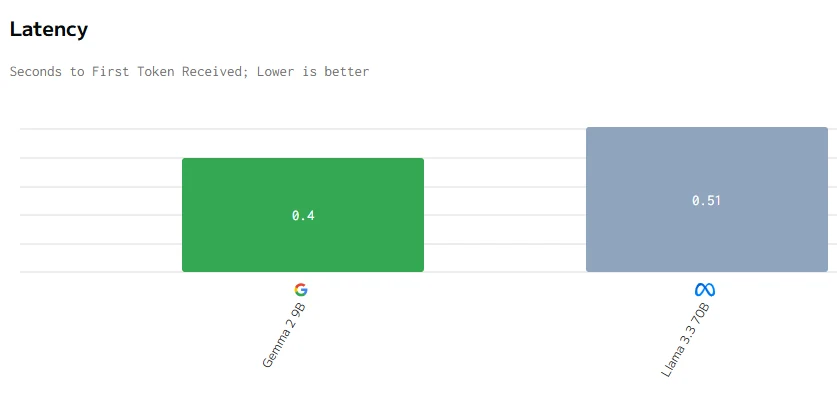
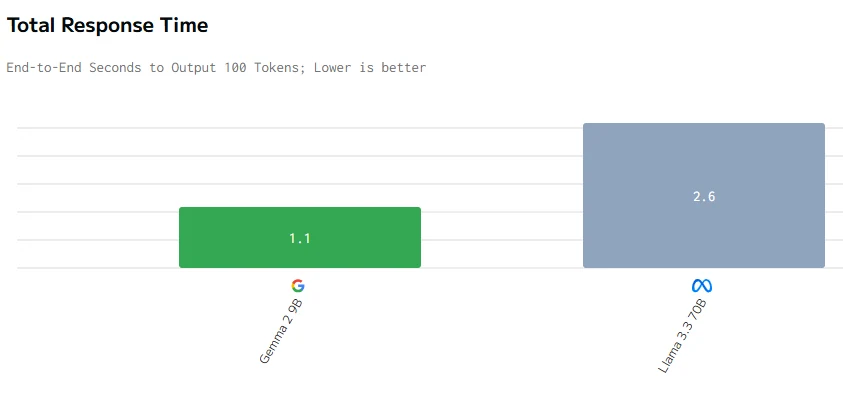
fonte de artificialanalysis
Comparação de Custos
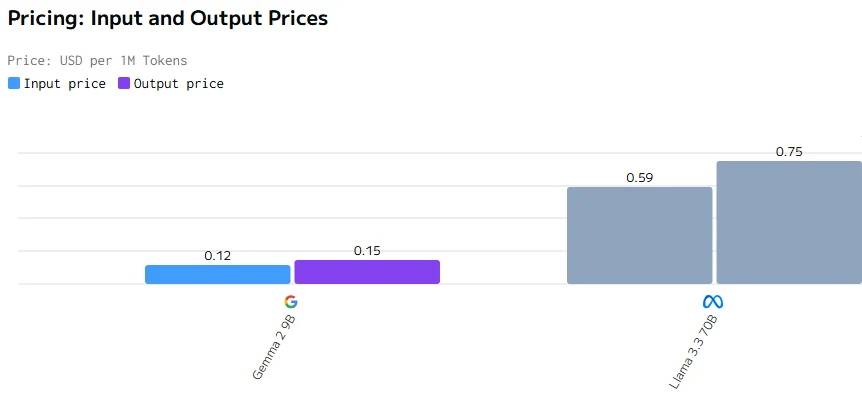
Concluindo, apesar do Gemma 2 9B ser menor com 9 bilhões de parâmetros, ele supera o Llama 3.3 70B em preço, latência, velocidade de saída e tempo de resposta. Isso provavelmente se deve a uma melhor otimização, arquitetura mais eficiente e potencialmente uma implantação de hardware mais eficaz, demonstrando que o tamanho menor não limita necessariamente o desempenho.
Comparação de Benchmarks
Agora que estabelecemos as características básicas de cada modelo, vamos nos aprofundar em seu desempenho em vários benchmarks. Essa comparação ajudará a ilustrar seus pontos fortes em diferentes áreas.

Llama 3.3 70B se destaca em várias tarefas, superando Gemma 2 9B em codificação, resolução de problemas matemáticos complexos e demonstrando fortes capacidades multilíngues nos testes MMLU e MGSM. Seu desempenho mostra versatilidade e força em vários domínios.
Se você quiser saber mais sobre o conhecimento de benchmark do llama 3.3, pode consultar este artigo a seguir:
Se quiser ver mais comparações entre llama 3.3 e outros modelos, confira estes artigos:
- Qwen 2.5 72b vs Llama 3.3 70b: Qual Modelo Atende Suas Necessidades?
- Llama 3.1 70b vs. Llama 3.3 70b: Melhor Desempenho, Preço Mais Alto
- O Llama 3.3 70B é Realmente Comparável ao Llama 3.1 405B?
Aplicações e Casos de Uso
Llama 3.3 70B
- Chatbots e assistentes multilíngues
- Suporte a codificação e desenvolvimento de software
- Geração de dados sintéticos
- Criação de conteúdo multilíngue e localização
- Pesquisa e experimentação
- Aplicações baseadas em conhecimento
- Implantação flexível para pequenas equipes
Gemma 2 9B
- Tarefas de geração de texto (sumarização, resposta a perguntas, raciocínio)
- Ambientes com recursos limitados
Acessibilidade e Implantação Através da Novita AI
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login em sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entrando na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com a Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Ao se registrar, a Novita AI fornece um crédito de $0,5 para você começar!
Se os créditos gratuitos acabarem, você pode pagar para continuar usando.
Llama 3.3 70B é um modelo de alto desempenho que se destaca em diversas tarefas, incluindo aplicações multilíngues e codificação. Sua eficiência em hardware padrão o torna atraente para muitos desenvolvedores. Gemma 2 9B, com seu tamanho menor, oferece uma solução leve e econômica para tarefas de geração de texto, particularmente útil em ambientes com recursos limitados.
A escolha entre esses dois modelos depende dos requisitos específicos do projeto. Llama 3.3 70B é mais adequado para tarefas complexas, variadas e multilíngues, enquanto Gemma 2 9B é preferível quando recursos ou orçamento são limitados.
Perguntas Frequentes
Quais são as principais diferenças entre o Llama 3.3 70B e o Claude 3.5 Sonnet?
Llama 3.3 70B é um modelo somente texto focado em eficiência e acessibilidade, enquanto Claude 3.5 Sonnet é um modelo multimodal que se destaca em raciocínio, codificação e tarefas visuais.
Qual modelo é melhor para codificação?
Ambos os modelos são proficientes em codificação, mas Claude 3.5 Sonnet possui capacidades de ponta nesta área. Llama 3.3 também demonstra forte desempenho em codificação.
O Llama 3.3 pode rodar no meu laptop?
Sim, o Llama 3.3 foi projetado para rodar em hardware comum de desenvolvedores, tornando-o acessível para equipes menores.
Novita AI é a plataforma All-in-one na nuvem que potencializa suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



