

Kimi K2.5 et DeepSeek V3.2 sont deux des familles de grands modèles les plus discutées aujourd’hui, chacune adoptée dans un nombre croissant d’applications réelles.
Cet article compare les deux modèles sur des dimensions qui comptent en pratique : groupes de benchmarks (raisonnement, utilisation d’outils agentiques, fiabilité du long contexte et codage), vitesse et latence, et coût. Nous incluons également les résultats de LM Arena pour refléter les préférences humaines lors d’utilisations en confrontation réelle. En outre, nous mettons en évidence les différences de capacités clés — comme la prise en charge des entrées multimodales — qui peuvent avoir un impact significatif sur la conception de systèmes de production.
À la fin de cette comparaison, vous aurez une idée claire de là où chaque modèle excelle, des compromis impliqués et de comment choisir en fonction de votre charge de travail plutôt que d’une seule métrique.
Introduction générale
| Kimi K2.5 | DeepSeek V3.2 | |
| Éditeur | Moonshot AI | DeepSeek |
| Architecture / Paramètres |
Architecture MoE, ~1 000 milliards de paramètres totaux, ~32 milliards de paramètres actifs | Architecture MoE, ~671 milliards de paramètres totaux, ~37 milliards activés par token |
| Architecture / paramètres (déclarés publiquement) | K2 est décrit comme MoE, ~1 000 milliards de paramètres totaux / 32 milliards actifs dans la tarification et la documentation Moonshot | Page du modèle DeepSeek-V3.2 (distribution communautaire) |
| Longueur de contexte sur Novita AI | 262 144 tokens | 163 840 tokens |
| Entrées/Sorties prises en charge | Texte, Image, Vidéo → Texte | Texte → Texte |
Comparaison des benchmarks
Les deux familles de modèles exposent généralement deux comportements d’exécution en pratique :
- Non-thinking : optimisé pour la vitesse et l’expérience utilisateur (UX) ainsi que les tâches générales
- Thinking : optimisé pour des tâches de raisonnement multi-étapes plus complexes et la planification agentique (au détriment de la latence)
D’après Artificial Analysis
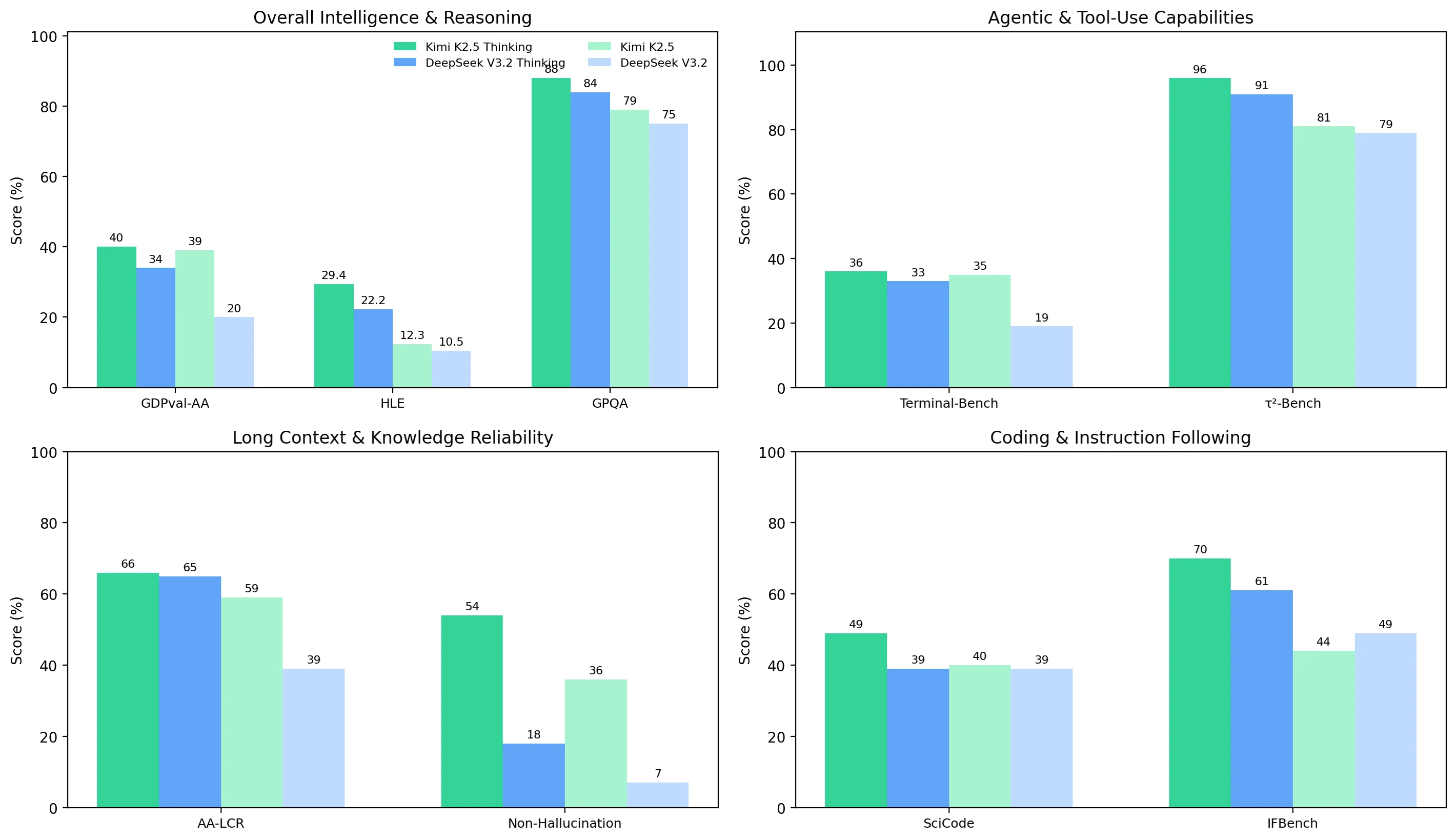
Sur les quatre groupes de benchmarks, Kimi K2.5 est plus performant de manière plus cohérente que DeepSeek V3.2, et son mode Thinking offre une amélioration de qualité plus importante sur les tâches les plus difficiles :
- Intelligence générale et raisonnement : Kimi est en tête dans les deux modes (par exemple, GDPval-AA 40 % contre 34 % en mode Thinking ; GPQA 88 % contre 84 %).
- Tâches agentiques et utilisation d’outils : Kimi est plus performant et plus robuste, notamment en mode non-thinking (Terminal-Bench Hard 35 % contre 19 %) ; le mode Thinking réduit l’écart mais ne le comble pas (36 % contre 33 %).
- Long contexte et fiabilité : AA-LCR est similaire en mode Thinking (66 % contre 65 %), mais la maîtrise des hallucinations est le grand facteur distinctif : le taux de non-hallucination de Kimi est bien plus élevé (54 % contre 18 % en mode Thinking ; 36 % contre 7 % en mode non-thinking).
- Codage et respect des instructions : Le codage en mode non-thinking est similaire (40 % contre 39 %), mais Kimi obtient des avantages clairs avec le mode Thinking (SciCode 49 % contre 39 % ; IFBench 70 % contre 61 %).
LM Arena (Préférences humaines)
Les groupes de benchmarks ci-dessus suggèrent que Kimi K2.5 est globalement plus performant de manière plus cohérente. Comme signal complémentaire « en conditions réelles », LM Arena reflète les préférences humaines lors de confrontations directes (données mises à jour le 29 janvier), et se divise entre texte et code.
✍Arène Texte : Kimi K2.5 Thinking est classé #12 (intervalle #7–#21) avec 1450 (±9), tandis que DeepSeek V3.2 Thinking est classé #36 (intervalle #27–#51) avec 1420 (±5) (DeepSeek V3.2 en mode non-thinking est #37, #28–#51, également 1420 (±5)).


💻Arène Code : DeepSeek V3.2 Thinking est classé #15 (intervalle #9–#16) avec 1372 (+11/-11), tandis que Kimi K2 Thinking Turbo est classé #20 (intervalle #18–#21) avec 1329 (+8/-8).


LM Arena confirme l’avantage de Kimi en matière d’expérience utilisateur texte, tout en mettant en évidence un segment centré sur le code où DeepSeek peut prendre l’avantage.
Comparaison de la vitesse et de la latence
| Métrique | Kimi K2.5 | DeepSeek V3.2 | Kimi K2.5 Thinking | DeepSeek V3.2 Thinking |
| Temps de réponse de bout en bout (s) — 500 tokens de sortie | 5,9 | 17,3 | 22,7 | 81,9 |
| Latence / TTFT (s) — temps jusqu’au premier token de réponse | 1,1 | 1,2 | 18,3 | 65,7 |
| Vitesse de sortie (tokens/s) | 103 | 31 | 116 | 31 |
Interprétation
- Deux régimes de fonctionnement très différents : En mode non-thinking, Kimi K2.5 et DeepSeek V3.2 se comportent de manière similaire au démarrage (TTFT ~1,1–1,2 s), mais leur temps de complétion diverge rapidement à mesure que la sortie augmente : Kimi termine une réponse de 500 tokens en 5,9 s contre 17,3 s pour DeepSeek.
- Le mode Thinking déplace le goulot d’étranglement sur le « temps de démarrage » : Le coût dominant devient le temps d’attente avant l’apparition du premier token : 18,3 s de TTFT pour Kimi K2.5 Thinking et 65,7 s pour DeepSeek V3.2 Thinking. Cela signifie que le mode Thinking ne consiste pas seulement à être « un peu plus lent », mais relève d’une « catégorie d’expérience utilisateur totalement différente ».
- Le débit explique l’écart de temps de réponse de bout en bout : Kimi maintient un débit de 103 à 116 tok/s, tandis que DeepSeek reste à 31 tok/s dans les deux modes : même après le premier token, le rythme de génération de DeepSeek reste le facteur limitant.
Comparaison des coûts
Cette section utilise la page de tarification de Novita AI pour les endpoints exacts :
| Modèle (endpoint Novita) | Entrée ($/Mt) | Lecture de cache ($/Mt) | Sortie ($/Mt) |
| moonshotai/kimi-k2.5 | 0,6 | 0,1 | 3 |
| deepseek/deepseek-v3.2 | 0,269 | 0,1345 | 0,4 |
Intuition sur les coûts :
- Si votre application est orientée sortie (réponses longues, génération de code), le prix de la sortie est prépondérant — et l’écart est important.
- Si votre application est orientée entrée (contextes RAG volumineux, beaucoup de texte récupéré), le prix d’entrée plus bas de DeepSeek peut être intéressant — surtout si vous pouvez contrôler la longueur de la sortie et/ou utiliser la mise en cache.
Comment déployer : API, SDK et intégrations tierces
Option A : API
Obtenir votre clé API sur Novita AI
- Étape 1 : Créer un compte ou se connecter : Rendez-vous sur
[https://novita.ai](https://novita.ai)et inscrivez-vous ou connectez-vous. - Étape 2 : Accéder à la gestion des clés : Après vous être connecté, trouvez « Clés API ».
- Étape 3 : Créer une nouvelle clé : Cliquez sur le bouton « Ajouter une nouvelle clé ».
- Étape 4 : Enregistrez votre clé immédiatement : Copiez et stockez la clé dès qu’elle est générée ; elle n’est affichée qu’une seule fois.

Appeler Novita via l’endpoint
Modifiez simplement :
base_url:https://api.novita.ai/openaiapi_key: votre clé Novitamodel:moonshotai/kimi-k2.5oudeepseek/deepseek-v3.2
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Option B : SDK
Si vous développez des flux de travail agentiques (routage, transferts, appels d’outils/fonctions), Novita fonctionne avec des SDK compatibles OpenAI avec des modifications minimales :
- Compatible en remplacement direct : conservez la logique client existante ; modifiez simplement base_url + model
- Prêt pour l’orchestration : facile à mettre en œuvre pour le routage (par défaut Flash → escalade vers GLM-4.7)
- Configuration : pointez vers
https://api.novita.ai/openai, définissezNOVITA_API_KEY, sélectionnezmoonshotai/kimi-k2.5oudeepseek/deepseek-v3.2
Option C : Plateformes tierces
Vous pouvez également exécuter les modèles hébergés par Novita via des écosystèmes populaires :
- Frameworks d’agents et outils de création d’applications : Suivez les guides d’intégration pas à pas de Novita pour vous connecter à des outils populaires tels que Continue, AnythingLLM, LangChain et Langflow.
- Hub Hugging Face : Novita est répertorié comme fournisseur d’inférence sur Hugging Face, vous pouvez donc exécuter les modèles pris en charge via le flux de travail et l’écosystème de fournisseur de Hugging Face.
- API compatible OpenAI : Les endpoints LLM de Novita sont compatibles avec la norme d’API OpenAI, ce qui facilite la migration d’applications existantes de type OpenAI et la connexion à de nombreux outils compatibles OpenAI ( Cline, Cursor, Trae et Qwen Code).
- API compatible Anthropic : Novita propose également un accès compatible avec le SDK Anthropic pour que vous puissiez intégrer des modèles supportés par Novita dans des flux de travail de codage agentiques de type Claude Code.
- OpenCode : Novita AI est désormais intégré directement à OpenCode en tant que fournisseur pris en charge, ce qui permet aux utilisateurs de sélectionner Novita dans OpenCode sans configuration manuelle.
Conclusion
Kimi K2.5 est le choix le plus polyvalent (plus de victoires cohérentes aux benchmarks, amélioration plus importante en mode Thinking et sorties longues beaucoup plus rapides lors de vos tests), tandis que DeepSeek V3.2 peut être intéressant pour les RAG orientés entrée grâce à un prix d’entrée plus bas et un avantage sur le code dans le segment code de LM Arena. Sur Novita AI, vous pouvez évaluer rapidement les deux côte à côte dans le Playground, puis déployer celui qui correspond le mieux au mélange de qualité, de réactivité et de coût de votre produit.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.
Foire aux questions
Kimi K2.5 est-il open source ?
Kimi K2.5 n’est pas entièrement open source au sens strict. C’est un modèle à poids ouverts publié par Moonshot AI sous licence MIT. Les poids du modèle et le code d’inférence sont publiquement disponibles pour une utilisation commerciale, un déploiement local et le fine-tuning. Cependant, Moonshot AI n’a pas publié l’intégralité de son code d’entraînement, de son jeu de données d’entraînement ou de son pipeline d’entraînement, il n’est donc pas possible de reproduire le modèle intégralement à partir de zéro.
Qu’est-ce que Kimi K2.5 ?
Kimi K2.5 est un grand modèle linguistique multimodal amélioré développé par Moonshot AI. Successeur de Kimi K2, il prend en charge les entrées multimodales notamment le texte, les images et la vidéo. Il offre des performances améliorées en matière de qualité conversationnelle, de raisonnement logique, de traitement du long contexte et de compréhension multimodale, et permet aux utilisateurs de déployer et de personnaliser le modèle localement via ses poids ouverts.
Kimi est-il meilleur que DeepSeek ?
Il n’existe pas de modèle « meilleur » dans tous les scénarios. Lors de nos évaluations, Kimi et DeepSeek présentent chacun des points forts en matière de raisonnement, de tâches agentiques, de coût et de latence. Le choix dépend de votre charge de travail, de vos objectifs de performance et de votre budget. Avec Novita AI, vous pouvez tester facilement les deux modèles côte à côte dans le Playground et sélectionner celui qui correspond le mieux à vos cas d’usage réels.



