

Kimi K2.5 e DeepSeek V3.2 são duas das famílias de grandes modelos mais discutidas atualmente, cada uma adotada em uma gama crescente de aplicações do mundo real.
Esta postagem compara os dois modelos em dimensões que importam na prática: clusters de benchmark (raciocínio, uso de ferramentas agênticas, confiabilidade de contexto longo e codificação), velocidade e latência, e custo. Também incluímos resultados do LM Arena para refletir a preferência humana em uso em confrontos diretos reais. Além disso, destacamos diferenças de capacidade essenciais – como suporte a entrada multimodal – que podem afetar materialmente o design de sistemas de produção.
Ao final desta comparação, você terá uma noção clara de onde cada modelo se destaca, os trade-offs envolvidos e como escolher com base na sua carga de trabalho, e não em uma única métrica.
Introdução Básica
| Kimi K2.5 | DeepSeek V3.2 | |
| Publicador | Moonshot AI | DeepSeek |
| Arquitetura / Parâmetros |
Arquitetura MoE, ~1T de parâmetros totais, ~32B de parâmetros ativos | Arquitetura MoE, ~671B de parâmetros totais, ~37B ativados por token |
| Arquitetura / parâmetros (declarados publicamente) | O K2 é descrito como MoE, ~1T de parâmetros totais / 32B ativos na documentação/preços da Moonshot | Página do modelo DeepSeek-V3.2 (distribuição comunitária) |
| Comprimento de contexto na Novita AI | 262.144 tokens | 163.840 tokens |
| Entradas/Saídas Suportadas | Texto, Imagem, Vídeo → Texto | Texto → Texto |
Comparação de Benchmarks
Ambas as famílias de modelos normalmente expõem dois comportamentos de execução na prática:
- Sem pensamento: otimizado para velocidade/UX e tarefas gerais
- Com pensamento: otimizado para tarefas de raciocínio multi-etapas mais complexas e planejamento de agentes (ao custo de latência)
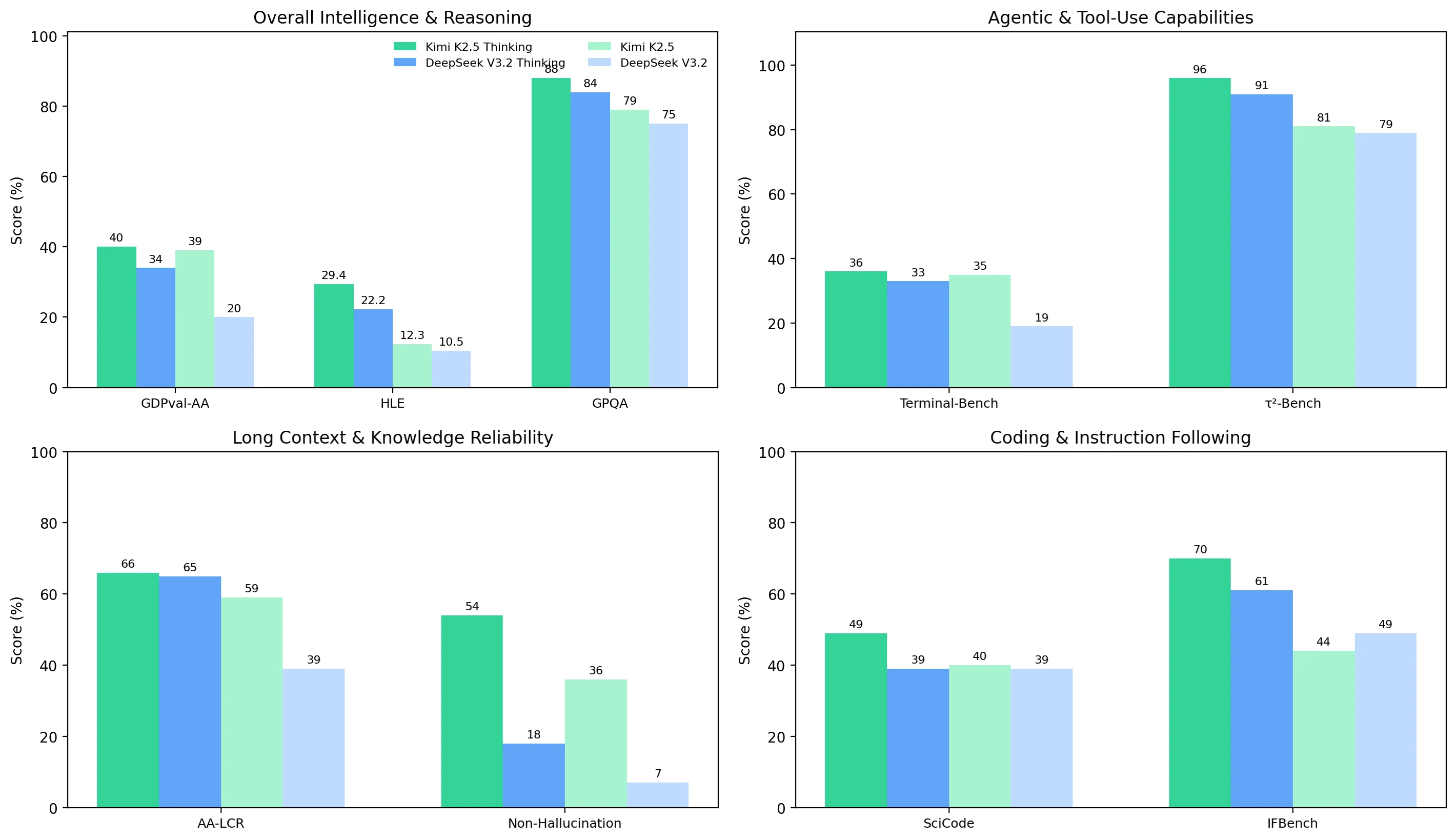
Nos quatro clusters de benchmark, o Kimi K2.5 é consistentemente mais forte que o DeepSeek V3.2, e seu modo de pensamento oferece um ganho de qualidade maior nas tarefas mais difíceis:
- Inteligência geral e raciocínio: O Kimi lidera em ambos os modos (ex.: GDPval-AA 40% vs 34% no modo de pensamento; GPQA 88% vs 84%).
- Agente e uso de ferramentas: O Kimi é mais forte e robusto, especialmente no modo sem pensamento (Terminal-Bench Hard 35% vs 19%); o modo de pensamento reduz a diferença, mas não a elimina (36% vs 33%).
- Contexto longo e confiabilidade: O AA-LCR é próximo no modo de pensamento (66% vs 65%), mas o controle de alucinações é o grande diferencial – a taxa de não alucinação do Kimi é muito maior (54% vs 18% no modo de pensamento; 36% vs 7% no modo sem pensamento).
- Codificação e seguimento de instruções: A codificação no modo sem pensamento é similar (40% vs 39%), mas o Kimi ganha vantagens claras com o modo de pensamento (SciCode 49% vs 39%; IFBench 70% vs 61%).
LM Arena (Preferência Humana)
Os clusters de benchmark acima sugerem que o Kimi K2.5 é consistentemente mais forte no geral. Como sinal complementar “no mundo real”, o LM Arena reflete a preferência humana em confrontos head-to-head (dados atualizados em 29 de janeiro), e se divide entre texto e código.
✍Arena de Texto: O Kimi K2.5 Thinking está em #12 (faixa #7–#21) com 1450 (±9), enquanto o DeepSeek V3.2 Thinking está em #36 (faixa #27–#51) com 1420 (±5) (o DeepSeek V3.2 no modo sem pensamento está em #37, #28–#51, também com 1420 (±5)).


💻Arena de Código: O DeepSeek V3.2 Thinking está em #15 (faixa #9–#16) com 1372 (+11/-11), enquanto o Kimi K2 Thinking Turbo está em #20 (faixa #18–#21) com 1329 (+8/-8).


O LM Arena reforça a vantagem do Kimi na UX de texto, ao mesmo tempo que destaca um segmento voltado para código onde o DeepSeek pode liderar.
Comparação de Velocidade e Latência
| Métrica | Kimi K2.5 | DeepSeek V3.2 | Kimi K2.5 Thinking | DeepSeek V3.2 Thinking |
| Tempo de Resposta End-to-End (s) — 500 tokens de saída | 5,9 | 17,3 | 22,7 | 81,9 |
| Latência / TTFT (s) — tempo até o primeiro token de resposta | 1,1 | 1,2 | 18,3 | 65,7 |
| Velocidade de Saída (tokens/seg) | 103 | 31 | 116 | 31 |
Interpretação
- Dois regimes de operação muito diferentes: No modo sem pensamento, o Kimi K2.5 e o DeepSeek V3.2 se comportam de forma similar no início (TTFT ~1,1–1,2s), mas seu tempo de conclusão diverge rapidamente conforme a saída cresce – o Kimi conclui uma resposta de 500 tokens em 5,9s contra os 17,3s do DeepSeek.
- O modo de pensamento move o gargalo para o “tempo de inicialização”: O custo dominante passa a ser esperar antes que qualquer coisa apareça: 18,3s de TTFT para o Kimi K2.5 Thinking e 65,7s para o DeepSeek V3.2 Thinking. Isso significa que o modo de pensamento não é sobre “um pouco mais lento”, e sim sobre uma “categoria de UX completamente diferente”.
- A vazão explica a diferença end-to-end: O Kimi mantém 103–116 tokens/s, enquanto o DeepSeek fica em 31 tokens/s em ambos os modos – então mesmo após o primeiro token, o ritmo de geração do DeepSeek continua sendo o fator limitante.
Comparação de Custo
Esta seção usa a página de preços da Novita AI para os endpoints exatos:
| Modelo (endpoint Novita) | Entrada ($/Mt) | Leitura de Cache ($/Mt) | Saída ($/Mt) |
| moonshotai/kimi-k2.5 | 0,6 | 0,1 | 3 |
| deepseek/deepseek-v3.2 | 0,269 | 0,1345 | 0,4 |
Intuição de custo:
- Se o seu aplicativo é voltado para saída (respostas longas, geração de código), o preço de saída domina – e a diferença é grande.
- Se o seu aplicativo é voltado para entrada (contextos RAG grandes, muito texto recuperado), o preço de entrada mais baixo do DeepSeek pode ser atraente – especialmente se você controlar o comprimento da saída e/ou usar cache.
Como Implantar: API, SDK e Integrações de Terceiros
Opção A: API
Obtendo sua Chave de API na Novita AI
- Passo 1: Crie ou faça login na sua conta: Acesse
[https://novita.ai](https://novita.ai)e cadastre-se ou faça login. - Passo 2: Acesse o Gerenciamento de Chaves: Após o login, encontre a seção “Chaves de API”.
- Passo 3: Crie uma Nova Chave: Clique no botão “Adicionar Nova Chave”.
- Passo 4: Salve sua Chave Imediatamente: Copie e armazene a chave assim que ela for gerada; ela é exibida apenas uma vez.

Chamar a Novita via endpoint
Apenas altere:
base_url:https://api.novita.ai/openaiapi_key: sua chave Novitamodel:moonshotai/kimi-k2.5oudeepseek/deepseek-v3.2
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Opção B: SDK
Se você está construindo fluxos de trabalho agênticos (roteamento, transferências, chamadas de ferramentas/funções), a Novita funciona com SDKs compatíveis com o OpenAI com alterações mínimas:
- Compatibilidade imediata: mantenha a lógica do seu cliente existente; basta alterar o
base_url+ omodel - Pronto para orquestração: fácil de implementar roteamento (padrão Flash → escalonamento para GLM-4.7)
- Configuração: aponte para
https://api.novita.ai/openai, defina aNOVITA_API_KEY, selecionemoonshotai/kimi-k2.5oudeepseek/deepseek-v3.2
Opção C: Plataformas de Terceiros
Você também pode executar modelos hospedados na Novita por meio de ecossistemas populares:
- Frameworks de agentes e construtores de aplicativos: Siga os guias de integração passo a passo da Novita para conectar-se a ferramentas populares como Continue, AnythingLLM, LangChain e Langflow.
- Hugging Face Hub: A Novita está listada como um Provedor de Inferência no Hugging Face, então você pode executar modelos suportados por meio do fluxo de trabalho e ecossistema do Hugging Face.
- API compatível com o OpenAI: Os endpoints de LLM da Novita são compatíveis com o padrão de API do OpenAI, facilitando a migração de aplicativos existentes no estilo OpenAI e a conexão com muitas ferramentas compatíveis com o OpenAI ( Cline, Cursor **, Trae e Qwen Code ) .
- API compatível com o Anthropic: A Novita também fornece acesso compatível com o SDK do Anthropic, para que você possa integrar modelos suportados pela Novita em fluxos de trabalho de codificação agêntica no estilo Claude Code.
- OpenCode: A Novita AI agora está integrada diretamente ao OpenCode como um provedor suportado, então os usuários podem selecionar a Novita no OpenCode sem configuração manual.
Conclusão
O Kimi K2.5 é a escolha mais forte geral (mais vitórias consistentes em benchmarks, ganho maior no modo de pensamento e saídas longas muito mais rápidas nos seus testes), enquanto o DeepSeek V3.2 pode ser atraente para RAG voltado para entrada, graças ao preço de entrada mais baixo e uma vantagem em preferência por código no segmento de código do LM Arena. Na Novita AI, você pode avaliar ambos rapidamente lado a lado no Playground e depois implantar o que melhor corresponder à combinação de qualidade, responsividade e custo do seu produto.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construir e escalar.
Perguntas Frequentes
O Kimi K2.5 é de código aberto?
O Kimi K2.5 não é totalmente de código aberto no sentido estrito. É um modelo de pesos abertos lançado pela Moonshot AI sob a licença MIT. Os pesos do modelo e o código de inferência estão disponíveis publicamente para uso comercial, implantação local e ajuste fino. No entanto, a Moonshot AI não lançou seu código de treinamento completo, conjunto de dados de treinamento ou pipeline de treinamento, então o modelo não pode ser totalmente reproduzido do zero.
O que é o Kimi K2.5?
O Kimi K2.5 é um modelo de linguagem grande multimodal atualizado desenvolvido pela Moonshot AI. Como sucessor do Kimi K2, ele suporta entradas multimodais, incluindo texto, imagens e vídeo. Ele oferece desempenho aprimorado em qualidade de conversa, raciocínio lógico, processamento de contexto longo e compreensão multimodal, e permite que os usuários implantem e personalizem o modelo localmente por meio de seus pesos abertos.
O Kimi é melhor que o DeepSeek?
Não há um modelo “melhor” único para todos os cenários. Em nossas avaliações, o Kimi e o DeepSeek cada um mostra pontos fortes em raciocínio, tarefas agênticas, custo e latência. A escolha certa depende da sua carga de trabalho, metas de desempenho e orçamento. Com a Novita AI, você pode testar ambos os modelos lado a lado facilmente no Playground e selecionar o que melhor se adapta aos seus casos de uso do mundo real.



