

Kimi K2.5 und DeepSeek V3.2 sind zwei der heute am meisten diskutierten großen Modellfamilien, die beide in einer wachsenden Anzahl von realen Anwendungen eingesetzt werden.
Dieser Beitrag vergleicht die beiden Modelle anhand von praktisch relevanten Kriterien: Benchmark-Cluster (Reasoning, agentische Werkzeugnutzung, Langkontext-Zuverlässigkeit und Programmierung), Geschwindigkeit und Latenz sowie Kosten. Wir fügen außerdem LM Arena-Ergebnisse hinzu, die die menschliche Präferenz bei realen direkten Vergleichen widerspiegeln. Darüber hinaus heben wir wichtige Funktionsunterschiede – wie die Unterstützung multimodaler Eingaben – hervor, die sich erheblich auf das Design von Produktionssystemen auswirken können.
Am Ende dieses Vergleichs hast du eine klare Vorstellung davon, wo jedes Modell seine Stärken hat, welche Kompromisse damit verbunden sind und wie du die Wahl basierend auf deinem Workflow triffst, statt anhand einer einzelnen Metrik.
Grundlegende Einführung
| Kimi K2.5 | DeepSeek V3.2 | |
| Herausgeber | Moonshot AI | DeepSeek |
| Architektur / Parameter |
MoE-Architektur, ~1 Billionen Gesamtparameter, ~32 Milliarden aktive Parameter | MoE-Architektur, ~671 Milliarden Gesamtparameter, ~37 Milliarden aktivierte Parameter pro Token |
| Architektur / Parameter (öffentlich angegeben) | K2 wird als MoE beschrieben, ~1 Billionen Gesamtparameter / 32 Milliarden aktive Parameter in Moonshots Preisliste/Dokumentation | DeepSeek-V3.2 Modellseite (Community-Distribution) |
| Kontextlänge auf Novita AI | 262.144 Token | 163.840 Token |
| Unterstützte Eingaben/Ausgaben | Text, Bild, Video → Text | Text → Text |
Benchmark-Vergleich
Beide Modellfamilien bieten in der Praxis typischerweise zwei Laufzeitmodi an:
- Non-thinking: Optimiert für Geschwindigkeit, Benutzererfahrung (UX) und allgemeine Aufgaben
- Thinking: Optimiert für anspruchsvollere mehrstufige Schlussfolgerungen und Agentenplanung (auf Kosten der Latenz)
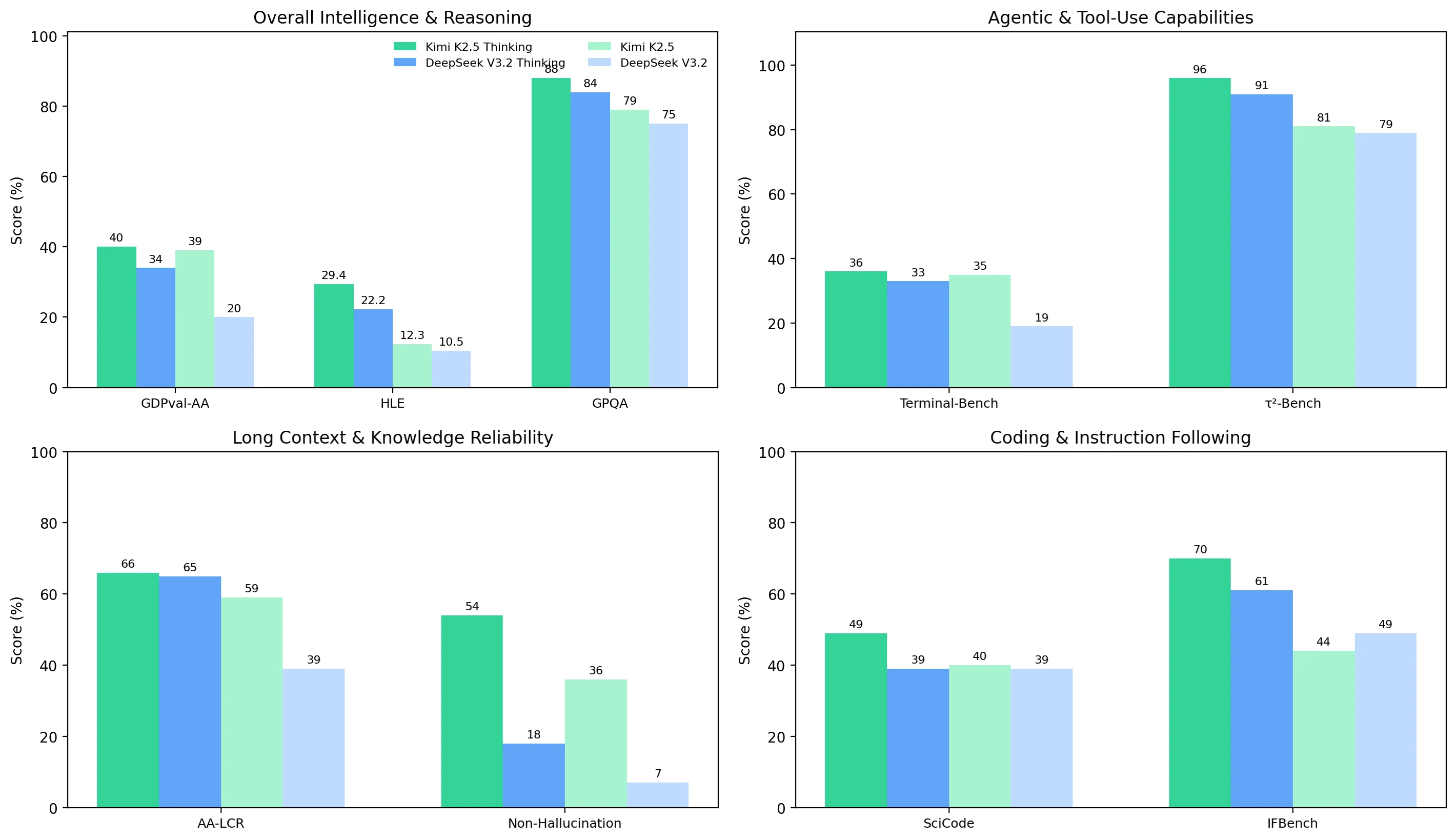
Über die vier Benchmark-Cluster hinweg ist Kimi K2.5 konsistenter stärker als DeepSeek V3.2, und sein Thinking-Modus liefert bei den schwierigsten Aufgaben einen größeren Qualitätszuwachs:
- Allgemeine Intelligenz & Schlussfolgerung: Kimi führt in beiden Modi (z. B. GDPval-AA 40 % vs. 34 % im Thinking-Modus; GPQA 88 % vs. 84 %).
- Agentische & Werkzeugnutzung: Kimi ist stärker und robuster, insbesondere im Non-thinking-Modus (Terminal-Bench Hard 35 % vs. 19 %); der Thinking-Modus verkleinert die Lücke, schließt sie aber nicht (36 % vs. 33 %).
- Langkontext & Zuverlässigkeit: AA-LCR ist im Thinking-Modus nah beieinander (66 % vs. 65 %), aber Halluzinationskontrolle ist der große Unterscheidungsfaktor – Kimis Rate an nicht-halluzinierten Antworten ist deutlich höher (54 % vs. 18 % im Thinking-Modus; 36 % vs. 7 % im Non-thinking-Modus).
- Programmierung & Anweisungsbefolgung: Programmierung im Non-thinking-Modus ist ähnlich (40 % vs. 39 %), aber Kimi erzielt klare Vorteile mit dem Thinking-Modus (SciCode 49 % vs. 39 %; IFBench 70 % vs. 61 %).
LM Arena (Menschliche Präferenz)
Die obigen Benchmark-Cluster deuten darauf hin, dass Kimi K2.5 insgesamt konsistenter stark ist. Als ergänzendes Signal aus der Praxis spiegelt LM Arena die menschliche Präferenz bei direkten Vergleichen wider (Daten aktualisiert am 29. Januar) und unterscheidet zwischen Text und Code.
✍️ Text Arena: Kimi K2.5 Thinking belegt Platz #12 (Bereich #7–#21) mit 1450 (±9), während DeepSeek V3.2 Thinking Platz #36 (Bereich #27–#51) mit 1420 (±5) belegt (DeepSeek V3.2 Non-thinking ist #37, #28–#51, ebenfalls 1420 (±5)).


💻 Code Arena: DeepSeek V3.2 Thinking belegt Platz #15 (Bereich #9–#16) mit 1372 (+11/-11), während Kimi K2 Thinking Turbo Platz #20 (Bereich #18–#21) mit 1329 (+8/-8) belegt.


LM Arena bestätigt Kimis Vorteil bei der Text-Benutzererfahrung, während es einen code-zentrierten Bereich hervorhebt, in dem DeepSeek führen kann.
Geschwindigkeits- & Latenz-Vergleich
| Metrik | Kimi K2.5 | DeepSeek V3.2 | Kimi K2.5 Thinking | DeepSeek V3.2 Thinking |
| End-to-End-Antwortzeit (s) – 500 Ausgabe-Token | 5,9 | 17,3 | 22,7 | 81,9 |
| Latenz / TTFT (s) – Zeit bis zum ersten Antwort-Token | 1,1 | 1,2 | 18,3 | 65,7 |
| Ausgabegeschwindigkeit (Token/Sekunde) | 103 | 31 | 116 | 31 |
Interpretation
- Zwei sehr unterschiedliche Betriebsmodi: Im Non-thinking-Modus verhalten sich Kimi K2.5 und DeepSeek V3.2 zu Beginn ähnlich (TTFT ~1,1–1,2 s), aber ihre Generierungszeit weicht schnell ab, je länger die Ausgabe wird – Kimi beendet eine 500-Token-Antwort in 5,9 s im Vergleich zu DeepSeeks 17,3 s.
- Thinking verlagert den Engpass auf die „Startzeit“: Die dominierende Kostenstelle ist das Warten, bevor etwas angezeigt wird: 18,3 s TTFT für Kimi K2.5 Thinking und 65,7 s für DeepSeek V3.2 Thinking. Das bedeutet, dass der Thinking-Modus weniger „etwas langsamer“ ist, sondern vielmehr eine völlig andere Kategorie von Benutzererfahrung darstellt.
- Durchsatz erklärt den End-to-End-Unterschied: Kimi erreicht dauerhaft 103–116 Token/s, während DeepSeek in beiden Modi bei 31 Token/s bleibt – also bleibt auch nach dem ersten Token die Generierungsgeschwindigkeit von DeepSeek der limitierende Faktor.
Kostenvergleich
Dieser Abschnitt verwendet die Preisseite von Novita AI für die genauen Endpunkte:
| Modell (Novita-Endpunkt) | Eingabe ($/Mio. Token) | Cache-Lesen ($/Mio. Token) | Ausgabe ($/Mio. Token) |
| moonshotai/kimi-k2.5 | 0,6 | 0,1 | 3 |
| deepseek/deepseek-v3.2 | 0,269 | 0,1345 | 0,4 |
Kosten-Intuition:
- Wenn deine Anwendung ausgabelastig ist (lange Antworten, Codegenerierung), dominiert der Ausgabepreis – und die Lücke ist groß.
- Wenn deine Anwendung eingabelastig ist (große RAG-Kontexte, viele abgerufene Texte), kann DeepSeeks niedrigerer Eingabepreis attraktiv sein – insbesondere wenn du die Ausgabelänge kontrollieren und/oder Caching nutzen kannst.
Bereitstellung: API, SDK und Integrationen von Drittanbietern
Option A: API
API-Schlüssel auf Novita AI erhalten
- Schritt 1: Konto erstellen oder anmelden: Besuche
[https://novita.ai](https://novita.ai)und registriere dich oder melde dich an. - Schritt 2: Zum Schlüsselverwaltung navigieren: Nach der Anmeldung findest du „API-Schlüssel“.
- Schritt 3: Neuen Schlüssel erstellen: Klicke auf die Schaltfläche „Neuen Schlüssel hinzufügen“.
- Schritt 4: Schlüssel sofort speichern: Kopiere und speichere den Schlüssel, sobald er generiert wurde; er wird nur einmal angezeigt.

Novita über Endpunkt aufrufen
Ändere nur folgende Werte:
base_url:https://api.novita.ai/openaiapi_key: dein Novita-Schlüsselmodel:moonshotai/kimi-k2.5oderdeepseek/deepseek-v3.2
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
Option B: SDK
Wenn du agentische Workflows (Routing, Übergaben, Tool-/Funktionsaufrufe) erstellst, funktioniert Novita mit OpenAI-kompatiblen SDKs mit minimalen Änderungen:
- Drop-in kompatibel: Behalte deine bestehende Client-Logik; ändere nur base_url + model
- Für Orchestrierung bereit: Einfach zu implementierendes Routing (Flash-Standard → GLM-4.7-Eskalation)
- Einrichtung: Zeige auf
https://api.novita.ai/openai, setzeNOVITA_API_KEY, wählemoonshotai/kimi-k2.5oderdeepseek/deepseek-v3.2
Option C: Plattformen von Drittanbietern
Du kannst die von Novita gehosteten Modelle auch über beliebte Ökosysteme ausführen:
- Agenten-Frameworks & App-Builder: Folge Novitas Schritt-für-Schritt-Integrationsanleitungen, um beliebte Tools wie Continue, AnythingLLM, LangChain und Langflow zu verbinden.
- Hugging Face Hub: Novita ist als Inferenzanbieter auf Hugging Face gelistet, sodass du unterstützte Modelle über den Workflow und das Ökosystem von Hugging Face ausführen kannst.
- OpenAI-kompatible API: Novitas LLM-Endpunkte sind kompatibel mit dem OpenAI-API-Standard, sodass du bestehende OpenAI-ähnliche Anwendungen einfach migrieren und viele OpenAI-kompatible Tools verbinden kannst ( Cline, Cursor , Trae und Qwen Code) .
- Anthropic-kompatible API: Novita bietet außerdem mit dem Anthropic SDK kompatiblen Zugriff, sodass du von Novita unterstützte Modelle in agentische Programmierworkflows im Stil von Claude Code integrieren kannst.
- OpenCode: Novita AI ist jetzt direkt in OpenCode als unterstützter Anbieter integriert, sodass Benutzer Novita in OpenCode ohne manuelle Konfiguration auswählen können.
Fazit
Kimi K2.5 ist die stärkere Allround-Lösung (mehr konsistente Benchmark-Erfolge, größerer Qualitätszuwachs im Thinking-Modus und deutlich schnellere lange Ausgaben in deinen Tests), während DeepSeek V3.2 für eingabelastige RAG-Anwendungen durch niedrigere Eingabepreise und einen Vorteil im code-zentrierten Bereich der LM Arena interessant sein kann. Auf Novita AI kannst du beide Modelle schnell nebeneinander im Playground testen und dann dasjenige bereitstellen, das am besten zur Mischung aus Qualität, Reaktionsfähigkeit und Kosten deines Produkts passt.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Häufig gestellte Fragen
Ist Kimi K2.5 Open Source?
Kimi K2.5 ist im strengen Sinne nicht vollständig Open Source. Es handelt sich um ein Open-Weight-Modell, das von Moonshot AI unter der MIT-Lizenz veröffentlicht wurde. Die Modellgewichte und der Inferenzcode sind öffentlich für kommerzielle Nutzung, lokale Bereitstellung und Fine-Tuning verfügbar. Moonshot AI hat jedoch seinen vollständigen Trainingscode, seinen Trainingsdatensatz und seine Trainingspipeline nicht veröffentlicht, sodass das Modell nicht vollständig von Grund auf reproduziert werden kann.
Was ist Kimi K2.5?
Kimi K2.5 ist ein aktualisiertes multimodales großes Sprachmodell, das von Moonshot AI entwickelt wurde. Als Nachfolger von Kimi K2 unterstützt es multimodale Eingaben wie Text, Bilder und Video. Es bietet verbesserte Leistung bei Gesprächsqualität, logischer Schlussfolgerung, Langkontext-Verarbeitung und multimodaler Verständnis und ermöglicht es Benutzern, das Modell lokal über seine offenen Gewichte bereitzustellen und anzupassen.
Ist Kimi besser als DeepSeek?
Es gibt kein einzelnes „besseres“ Modell für jedes Szenario. In unseren Bewertungen zeigen Kimi und DeepSeek jeweils Stärken bei Reasoning, agentischen Aufgaben, Kosten und Latenz. Die richtige Wahl hängt von deinem Workflow, deinen Leistungszielen und deinem Budget ab. Mit Novita AI kannst du beide Modelle einfach nebeneinander im Playground testen und dasjenige auswählen, das am besten zu deinen realen Anwendungsfällen passt.



