

Kimi K2.5 と DeepSeek V3.2 は、現在最も広く議論されている大規模モデルファミリーの2つであり、それぞれ実世界のアプリケーションでますます採用されています。
この記事では、実際に重要な次元で2つのモデルを比較します:ベンチマーククラスター(推論、エージェントツール使用、長文脈信頼性、コーディング)、速度とレイテンシ、コストです。また、実際の対決使用における人間の好みを反映するためにLM Arenaの結果も含めます。さらに、マルチモーダル入力サポートなど、プロダクションシステム設計に実質的に影響を与える可能性のある主要な能力の違いを強調します。
この比較の終わりまでに、各モデルがどこで優れているか、関連するトレードオフ、そして単一の指標ではなくワークロードに基づいて選択する方法について明確な理解が得られるでしょう。
基本紹介
| Kimi K2.5 | DeepSeek V3.2 | |
| 開発元 | Moonshot AI | DeepSeek |
| アーキテクチャ / パラメータ |
MoEアーキテクチャ、総パラメータ約1T、アクティブパラメータ約32B | MoEアーキテクチャ、総パラメータ約671B、トークンあたり約37Bアクティブ |
| アーキテクチャ / パラメータ(公式発表) | K2はMoEとして説明され、Moonshotの価格/ドキュメントでは総パラメータ約1T / アクティブ32B | DeepSeek-V3.2モデルページ(コミュニティ配布) |
| Novita AIでのコンテキスト長 | 262,144トークン | 163,840トークン |
| 対応入力/出力 | テキスト、画像、動画 → テキスト | テキスト → テキスト |
ベンチマーク比較
両方のモデルファミリーは通常、実際には2つのランタイム動作を提供します:
- 非思考モード:速度/UXと一般的なタスクに最適化
- 思考モード:より難しい多段階推論とエージェント計画に最適化(レイテンシとのトレードオフ)
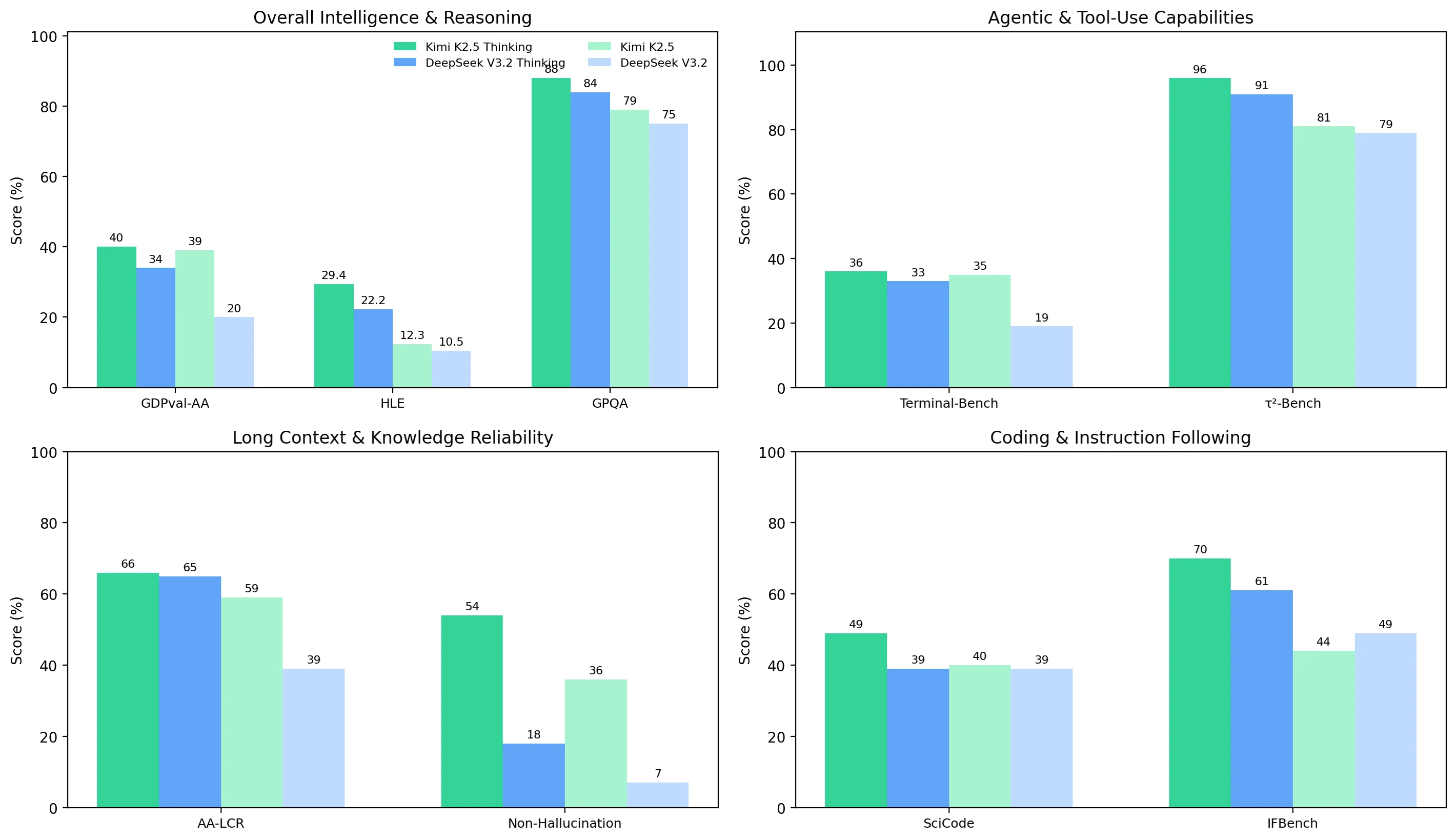
4つのベンチマーククラスター全体で、Kimi K2.5はDeepSeek V3.2よりも一貫して強力であり、その思考モードは最も難しいタスクでより大きな品質向上をもたらします。
- 全体的な知能と推論: Kimiは両方のモードでリード(例:思考モードのGDPval-AA 40% vs 34%、GPQA 88% vs 84%)。
- エージェントとツール使用: Kimiはより強力で堅牢、特に非思考モード(Terminal-Bench Hard 35% vs 19%);思考モードではギャップが縮まるが解消しない(36% vs 33%)。
- 長文脈と信頼性: 思考モードのAA-LCRは拮抗(66% vs 65%)しているが、幻覚抑制が大きな差別化要因—Kimiの非幻覚率ははるかに高い(思考モード54% vs 18%、非思考モード36% vs 7%)。
- コーディングと指示従順: 非思考モードのコーディングは類似(40% vs 39%)しているが、Kimiは思考モードで明確なアドバンテージを得る(SciCode 49% vs 39%、IFBench 70% vs 61%)。
LMアリーナ(人間の好み)
上記のベンチマーククラスターは、Kimi K2.5が全体的に一貫して強いことを示唆しています。補完的な「実環境」シグナルとして、LMアリーナは直接対決における人間の好みを反映しており(データは1月29日更新)、テキストとコードに分かれています。
✍テキストアリーナ: Kimi K2.5 Thinkingは1450(±9)で12位(範囲7~21位)、一方DeepSeek V3.2 Thinkingは1420(±5)で36位(範囲27~51位)(DeepSeek V3.2非思考モードは37位、範囲28~51位、同じく1420(±5))。


💻コードアリーナ: DeepSeek V3.2 Thinkingは1372(+11/-11)で15位(範囲9~16位)、一方Kimi K2 Thinking Turboは1329(+8/-8)で20位(範囲18~21位)。


LMアリーナはテキストUXにおけるKimiの優位性を強化しつつ、DeepSeekがリードできるコード中心の領域を強調しています。
速度とレイテンシの比較
| 指標 | Kimi K2.5 | DeepSeek V3.2 | Kimi K2.5 Thinking | DeepSeek V3.2 Thinking |
| エンドツーエンド応答時間(秒)— 500出力トークン | 5.9 | 17.3 | 22.7 | 81.9 |
| レイテンシ / TTFT(秒)— 最初の回答トークンまでの時間 | 1.1 | 1.2 | 18.3 | 65.7 |
| 出力速度(トークン/秒) | 103 | 31 | 116 | 31 |
解釈
- 2つの非常に異なる動作モード: 非思考モードでは、Kimi K2.5とDeepSeek V3.2は開始時に同様の動作を示します(TTFT約1.1~1.2秒)が、出力が増えるにつれて完了時間は急速に乖離します—Kimiは500トークンの応答を5.9秒で完了するのに対し、DeepSeekは17.3秒です。
- 思考モードはボトルネックを「起動時間」に移す: 支配的なコストは何も表示される前に待つことになります:Kimi K2.5 ThinkingのTTFTは18.3秒、DeepSeek V3.2 Thinkingは65.7秒。つまり、思考モードは「少し遅い」というよりも、完全に「異なるUXカテゴリ」であることを意味します。
- スループットがエンドツーエンドのギャップを説明: Kimiは103~116トークン/秒を維持するのに対し、DeepSeekは両モードで31トークン/秒に留まります—そのため、最初のトークン以降も、DeepSeekの生成速度が制限要因のままです。
コスト比較
このセクションでは、正確なエンドポイントにNovita AIの価格ページを使用します:
| モデル(Novitaエンドポイント) | 入力($/Mt) | キャッシュ読み取り($/Mt) | 出力($/Mt) |
| moonshotai/kimi-k2.5 | 0.6 | 0.1 | 3 |
| deepseek/deepseek-v3.2 | 0.269 | 0.1345 | 0.4 |
コストの直感:
- アプリが出力重視(長い回答、コード生成)の場合、出力価格が支配的で、ギャップは大きくなります。
- アプリが入力重視(大規模RAGコンテキスト、多くの取得テキスト)の場合、DeepSeekの低い入力価格が魅力的になる可能性があります—特に出力長を制御できる場合やキャッシュを使用できる場合。
デプロイ方法:API、SDK、サードパーティ連携
オプションA: API
Novita AIでAPIキーを取得する
- ステップ1:アカウントを作成またはログイン:
[https://novita.ai](https://novita.ai)にアクセスしてサインアップまたはログインします。 - ステップ2:キー管理に移動:ログイン後、「APIキー」を見つけます。
- ステップ3:新しいキーを作成:「新しいキーを追加」ボタンをクリックします。
- ステップ4:キーをすぐに保存:生成されたらすぐにキーをコピーして保存します;一度だけ表示されます。

エンドポイント経由でNovitaを呼び出す
以下の変更を行うだけです:
base_url:https://api.novita.ai/openaiapi_key: あなたのNovitaキーmodel:moonshotai/kimi-k2.5またはdeepseek/deepseek-v3.2
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
オプションB: SDK
エージェントワークフロー(ルーティング、ハンドオフ、ツール/関数呼び出し)を構築している場合、Novitaは最小限の変更でOpenAI互換SDKと連携します:
- ドロップイン互換:既存のクライアントロジックを維持し、base_urlとmodelを変更するだけ
- オーケストレーション対応:ルーティングの実装が容易(Flashデフォルト→GLM-4.7エスカレーション)
- セットアップ:
https://api.novita.ai/openaiを指定し、NOVITA_API_KEYを設定し、moonshotai/kimi-k2.5またはdeepseek/deepseek-v3.2を選択
オプションC: サードパーティプラットフォーム
人気のエコシステムを通じてNovitaホストモデルを実行することもできます:
- エージェントフレームワークとアプリビルダー: Novitaのステップバイステップの統合ガイドに従って、Continue、AnythingLLM、LangChain、Langflow などの人気ツールと接続します。
- Hugging Face Hub: NovitaはHugging Faceで推論プロバイダーとしてリストされているため、Hugging Faceのプロバイダーワークフローとエコシステムを通じてサポートされているモデルを実行できます。
- OpenAI互換API: NovitaのLLMエンドポイントはOpenAI API標準と互換性があり、既存のOpenAIスタイルのアプリの移行や多くのOpenAI互換ツール( Cline、Cursor、Trae、Qwen Code )との接続が容易です。
- Anthropic互換API: NovitaはAnthropic SDK互換のアクセスも提供しており、Novitaバックエンドのモデルを**Claude Code** スタイルのエージェントコーディングワークフローに統合できます。
- OpenCode: Novita AIは現在、OpenCode にサポートプロバイダーとして直接統合されているため、ユーザーは手動設定なしでOpenCode内でNovitaを選択できます。
まとめ
Kimi K2.5は全体的に優れた選択肢です(より一貫したベンチマークでの勝利、思考モードでの大きな向上、テストでの高速な長出力)。一方、DeepSeek V3.2は、低い入力価格とLMアリーナのコードスライスでのコード嗜好の優位性により、入力重視のRAGに魅力的です。Novita AIでは、Playgroundですばやく両方を並べて評価し、製品の品質、応答性、コストのバランスに最も適したモデルをデプロイできます。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、さらに構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。
よくある質問
Kimi K2.5はオープンソースですか?
Kimi K2.5は厳密な意味での完全なオープンソースではありません。これは、Moonshot AIがMITライセンスの下で公開したオープンウェイトモデルです。モデルの重みと推論コードは、商用利用、ローカルデプロイ、ファインチューニングのために公開されています。ただし、Moonshot AIは完全なトレーニングコード、トレーニングデータセット、トレーニングパイプラインを公開していないため、モデルをゼロから完全に再現することはできません。
Kimi K2.5とは何ですか?
Kimi K2.5は、Moonshot AIによって開発されたアップグレード版のマルチモーダル大規模言語モデルです。Kimi K2の後継として、テキスト、画像、動画を含むマルチモーダル入力をサポートします。会話品質、論理的推論、長文脈処理、マルチモーダル理解においてパフォーマンスが向上しており、ユーザーはオープンウェイトを介してローカルでモデルをデプロイおよびカスタマイズできます。
KimiはDeepSeekより優れていますか?
すべてのシナリオに「優れた」単一のモデルはありません。当社の評価では、KimiとDeepSeekはそれぞれ推論、エージェントタスク、コスト、レイテンシにおいて強みを示しています。適切な選択は、ワークロード、パフォーマンス目標、予算によって異なります。Novita AIを使用すると、Playgroundで両方のモデルを簡単に並べてテストし、実際のユースケースに最適なモデルを選択できます。



