

Kimi K2.5 和 DeepSeek V3.2 是當前討論度最高的兩款大型模型家族,已被廣泛應用於越來越多實際場景中。
這篇文章會從實務上重要的多個維度比較這兩款模型:基準測試集群(推理、智能體工具調用、長上下文可靠性、程式碼任務)、速度與延遲,以及成本。我們也納入了 LM Arena 的結果,反映真實頭對頭使用場景中的人類偏好。此外我們還會標註關鍵能力差異(例如多模態輸入支援),這些差異會對生產系統設計產生實質影響。
讀完這篇比較後,你將能清楚了解每款模型的優勢所在、涉及的取捨,以及如何根據你的工作負載而非單一指標來選擇合適的模型。
基本介紹
| Kimi K2.5 | DeepSeek V3.2 | |
| 開發商 | Moonshot AI | DeepSeek |
| 架構 / 參數量 |
MoE 架構,總參數量約 1T,每次推理活躍參數量約 32B | MoE 架構,總參數量約 671B,每次 token 推理活躍參數量約 37B |
| 架構 / 參數量(公開資訊) | K2 在 Moonshot 定價/文件中描述為 MoE 架構,總參數量約 1T / 活躍參數量 32B | DeepSeek-V3.2 模型頁面(社群發行版本) |
| Novita AI 平台上下文長度 | 262,144 tokens | 163,840 tokens |
| 支援的輸入/輸出類型 | 文字、圖片、影片 → 文字 | 文字 → 文字 |
基準測試比較
這兩款模型家族在實際使用中通常會提供兩種運行模式:
- Non-thinking:優化速度/使用者體驗與通用任務
- Thinking:優化複雜多步驟推理與智能體規劃(代价是更高的延遲)
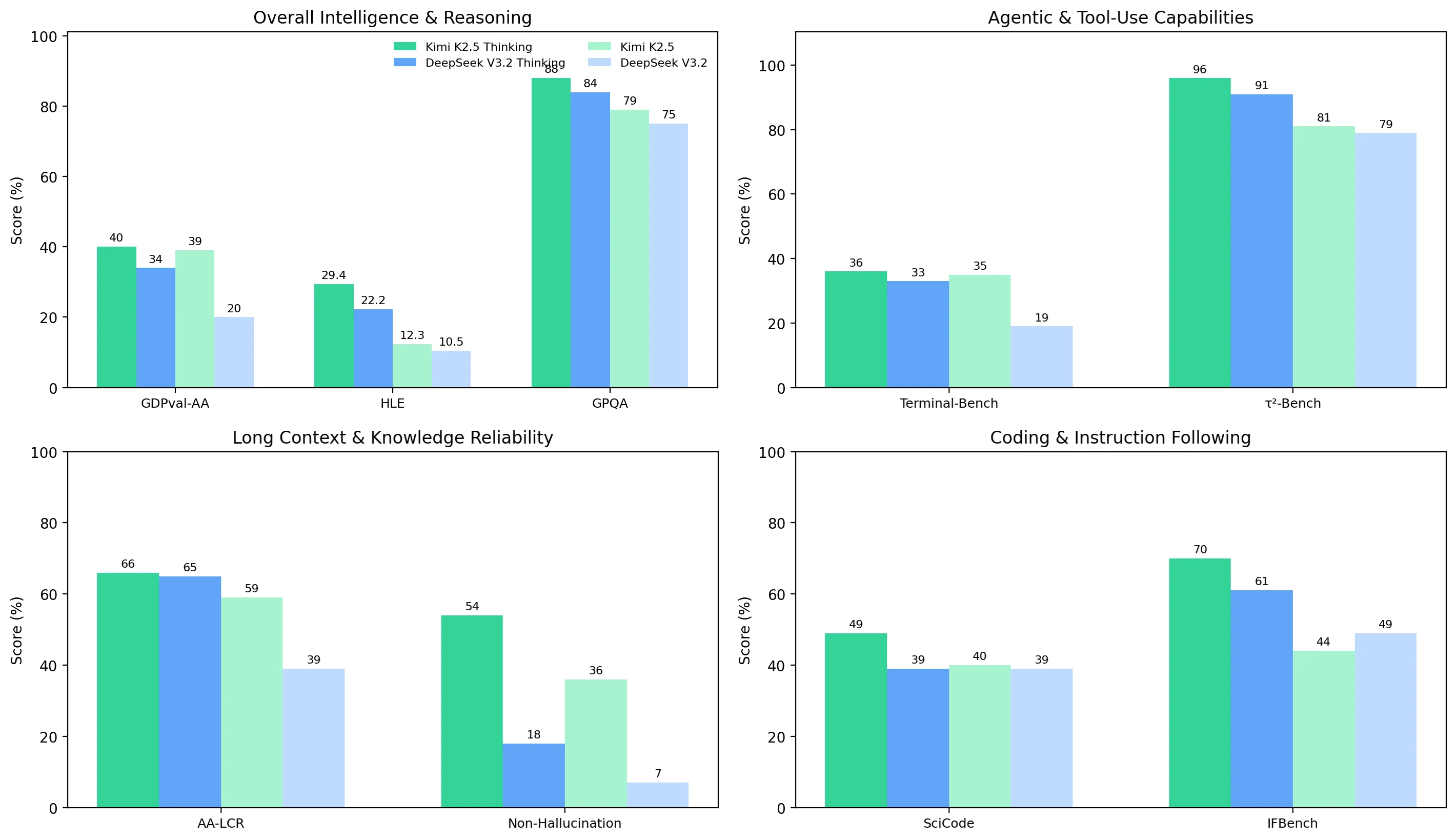
From Artificial Analysis
在四個基準測試集群中,Kimi K2.5 的表現整體更穩定地優於 DeepSeek V3.2,且其思考模式在難度最高的任務中帶來的品質提升幅度更大:
- 整體智慧與推理能力:Kimi 在兩種模式下都領先(例如思考模式下 GDPval-AA 得分 40% 對比 34%;GPQA 得分 88% 對比 84%)。
- 智能體與工具調用:Kimi 更強且更穩定,尤其在非思考模式下(Terminal-Bench Hard 得分 35% 對比 19%);思考模式下差距縮小但未逆轉(36% 對比 33%)。
- 長上下文與可靠性:思考模式下 AA-LCR 得分接近(66% 對比 65%),但幻覺控制是最大的差異點——Kimi 的非幻覺率遠高於 DeepSeek(思考模式下 54% 對比 18%;非思考模式下 36% 對比 7%)。
- 程式碼與指令遵循:非思考模式下程式碼能力相近(40% 對比 39%),但 Kimi 在思考模式下優勢明顯(SciCode 得分 49% 對比 39%;IFBench 得分 70% 對比 61%)。
LM Arena(人類偏好)
上述基準測試集群的結果表明Kimi K2.5 的整體表現更穩定。作為補充的真實場景訊號,LM Arena 反映了頭對頭比對中的人類偏好(數據更新於 1 月 29 日),且分為文字與程式碼兩個賽道。
✍文字賽道:Kimi K2.5 Thinking 排名第 12 位(區間第 7–21 位),得分1450(±9),而 DeepSeek V3.2 Thinking 排名第 36 位(區間第 27–51 位),得分1420(±5)(DeepSeek V3.2 非思考模式排名第 37 位,區間第 28–51 位,得分同樣為 1420(±5))。


💻程式碼賽道:DeepSeek V3.2 Thinking 排名第 15 位(區間第 9–16 位),得分1372(+11/-11),而 Kimi K2 Thinking Turbo 排名第 20 位(區間第 18–21 位),得分1329(+8/-8)。


LM Arena 的結果印證了 Kimi 在文字使用體驗上的優勢,同時也凸顯了 DeepSeek 在程式碼相關場景中的領先潛力。
速度與延遲比較
| 指標 | Kimi K2.5 | DeepSeek V3.2 | Kimi K2.5 思考模式 | DeepSeek V3.2 思考模式 |
| 端到端回應時間(秒)—— 500 個輸出 token | 5.9 | 17.3 | 22.7 | 81.9 |
| 延遲 / 首 token 回應時間(秒)—— 第一個回答 token 的耗時 | 1.1 | 1.2 | 18.3 | 65.7 |
| 輸出速度(token/秒) | 103 | 31 | 116 | 31 |
解讀
- 兩種截然不同的運行模式:在非思考模式下,Kimi K2.5 與 DeepSeek V3.2 的啟動階段表現相近(首 token 回應時間約 1.1–1.2 秒),但隨著輸出內容增加,完成時間的差距迅速拉大——Kimi 生成 500 個 token 的回應耗時 5.9 秒,而 DeepSeek 需要 17.3 秒。
- 思考模式將瓶頸轉移到「啟動時間」:主要耗時來自於等待第一個 token 輸出:Kimi K2.5 思考模式的首 token 回應時間為 18.3 秒,DeepSeek V3.2 思考模式則高達 65.7 秒。這意味著思考模式並非只是「稍微慢一點」,而是完全屬於不同的使用者體驗類別。
- 吞吐量決定了端到端的差距:Kimi 的輸出速度能穩定維持在 103–116 token/秒,而 DeepSeek 在兩種模式下都只有 31 token/秒——因此即使第一個 token 輸出後,DeepSeek 的生成速度仍然是制約因素。
成本比較
本節採用** Novita AI 定價頁面**的官方端點價格:
| 模型(Novita 端點) | 輸入價格(美元/百萬 token) | 快取讀取價格(美元/百萬 token) | 輸出價格(美元/百萬 token) |
| moonshotai/kimi-k2.5 | 0.6 | 0.1 | 3 |
| deepseek/deepseek-v3.2 | 0.269 | 0.1345 | 0.4 |
成本直觀說明:
- 如果你的應用是輸出密集型(需要長回覆、程式碼生成),輸出價格會是主要成本,兩者的差距非常大。
- 如果你的應用是輸入密集型(需要大規模 RAG 上下文、大量檢索文字),DeepSeek 更低的輸入價格會很有吸引力——尤其當你能控制輸出長度、或使用快取功能時。
部署方式:API、SDK 與第三方整合
選項 A:API
在 Novita AI 取得 API 金鑰
- 步驟 1:建立或登入帳號:造訪
[https://novita.ai](https://novita.ai)註冊或登入。 - 步驟 2:前往金鑰管理頁面:登入後找到「API Keys」選項。
- 步驟 3:建立新金鑰:點擊「Add New Key」按鈕。
- 步驟 4:立即保存金鑰:金鑰生成後請立即複製儲存,頁面只會顯示一次。

透過端點呼叫 Novita 服務
只需修改以下參數:
base_url:https://api.novita.ai/openaiapi_key:你的 Novita 金鑰model:moonshotai/kimi-k2.5或deepseek/deepseek-v3.2
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
選項 B:SDK
如果你正在構建智能體工作流程(路由、交接、工具/函數調用),Novita 支援相容 OpenAI 的 SDK,只需極小修改即可接入:
- 即插即用相容:保留你現有的客戶端邏輯,只需修改 base_url 與 model 參數
- 適配協調框架:輕鬆實現路由功能(預設使用 Flash 模型,必要時切換至 GLM-4.7)
- 設定方式:將端點指向
https://api.novita.ai/openai,設定環境變數NOVITA_API_KEY,選擇moonshotai/kimi-k2.5或deepseek/deepseek-v3.2
選項 C:第三方平台
你也可以透過主流生態系使用 Novita 託管的模型:
- 智能體框架與應用構建工具:參閱 Novita 的逐步整合指南,連接熱門工具如 Continue、AnythingLLM、LangChain 和 Langflow。
- Hugging Face Hub:Novita 是 Hugging Face 的推理供應商,你可以透過 Hugging Face 的供應商工作流與生態系運行支援的模型。
- OpenAI 相容 API:Novita 的 LLM 端點相容 OpenAI API 標準,能輕鬆遷移現有的 OpenAI 風格應用,並連接眾多 OpenAI 相容工具(Cline、Cursor、Trae 和 Qwen Code)。
- Anthropic 相容 API:Novita 也提供相容 Anthropic SDK 的存取方式,你可以將 Novita 支援的模型整合到**Claude Code** 風格的智能體程式碼工作流程中。
- OpenCode:Novita AI 已直接整合到 OpenCode 作為支援的供應商,使用者無需手動設定即可在 OpenCode 中選擇 Novita。
總結
Kimi K2.5 是更全面的選擇(基準測試獲勝次數更多、思考模式提升幅度更大、長輸出速度在測試中快非常多),而 DeepSeek V3.2 則適合輸入密集型的 RAG 場景,因為其輸入價格更低,且在 LM Arena 的程式碼賽道中表現優異。在 Novita AI 上,你可以在 Playground 中快速並排測試兩款模型,再根據你的產品在品質、回應速度與成本之間的取捨,選擇最合適的模型部署。
Novita AI 是 AI 雲端平台,為開發者提供簡易的 API 介面部署 AI 模型,同時也提供實惠且可靠的 GPU 雲端資源,用於構建與擴展 AI 應用。
常見問題
Kimi K2.5 是開源模型嗎?
Kimi K2.5 並非嚴格意義上的完全開源。它是 Moonshot AI 在 MIT 許可證下發布的開放權重模型。模型權重與推理程式碼已公開,可用於商業用途、本地部署與微調。但 Moonshot AI 尚未公開完整的訓練程式碼、訓練數據集與訓練流程,因此無法從零開始完整複現該模型。
Kimi K2.5 是什麼?
Kimi K2.5 是由 Moonshot AI 開發的升級版多模態大型語言模型。作為 Kimi K2 的後續版本,它支援文字、圖片、影片等多模態輸入,在對話品質、邏輯推理、長上下文處理與多模態理解方面都有性能提升,使用者也可以透過其開放權重在本地部署與自訂模型。
Kimi 比 DeepSeek 更好嗎?
沒有適用於所有場景的「更好」模型。在我們的評估中,Kimi 與 DeepSeek 在推理、智能體任務、成本與延遲方面各有優勢。正確的選擇取決於你的工作負載、性能目標與預算。透過 Novita AI,你可以在 Playground 中輕鬆並排測試兩款模型,選擇最適合你實際使用場景的版本。



