

Kimi K2.5 和 DeepSeek V3.2 是当今讨论最广泛的两大模型系列,在越来越多的实际应用中被采用。
本文从实践相关的维度对这两个模型进行比较:基准测试集群(推理、智能体工具使用、长上下文可靠性、编码)、速度与延迟,以及成本。我们还纳入了LM Arena的结果,以反映真实对战中的人类偏好。此外,我们重点突出了关键能力差异——例如多模态输入支持——这些差异会实质性影响生产系统的设计。
通过本次对比,您将清楚了解每个模型的优势所在、其中的权衡,以及如何根据您的工作负载(而非单一指标)做出选择。
基本介绍
| Kimi K2.5 | DeepSeek V3.2 | |
| 发布者 | Moonshot AI | DeepSeek |
| 架构/参数量 |
MoE架构,总参数量~1T,激活参数量~32B | MoE架构,总参数量~671B,每个token激活参数量~37B |
| 架构/参数量(公开声明) | K2被描述为MoE,总参数量~1T / 激活32B(来自Moonshot定价/文档) | DeepSeek-V3.2模型页面(社区发布) |
| Novita AI上的上下文长度 | 262,144 tokens | 163,840 tokens |
| 支持的输入/输出 | 文本、图像、视频 → 文本 | 文本 → 文本 |
基准测试对比
这两个模型系列在实际使用中通常展现两种运行时行为:
- 非思考模式:针对速度/用户体验和通用任务进行了优化
- 思考模式:针对更困难的、需要多步推理和智能体规划的任务进行了优化(以增加延迟为代价)
数据来源:Artificial Analysis
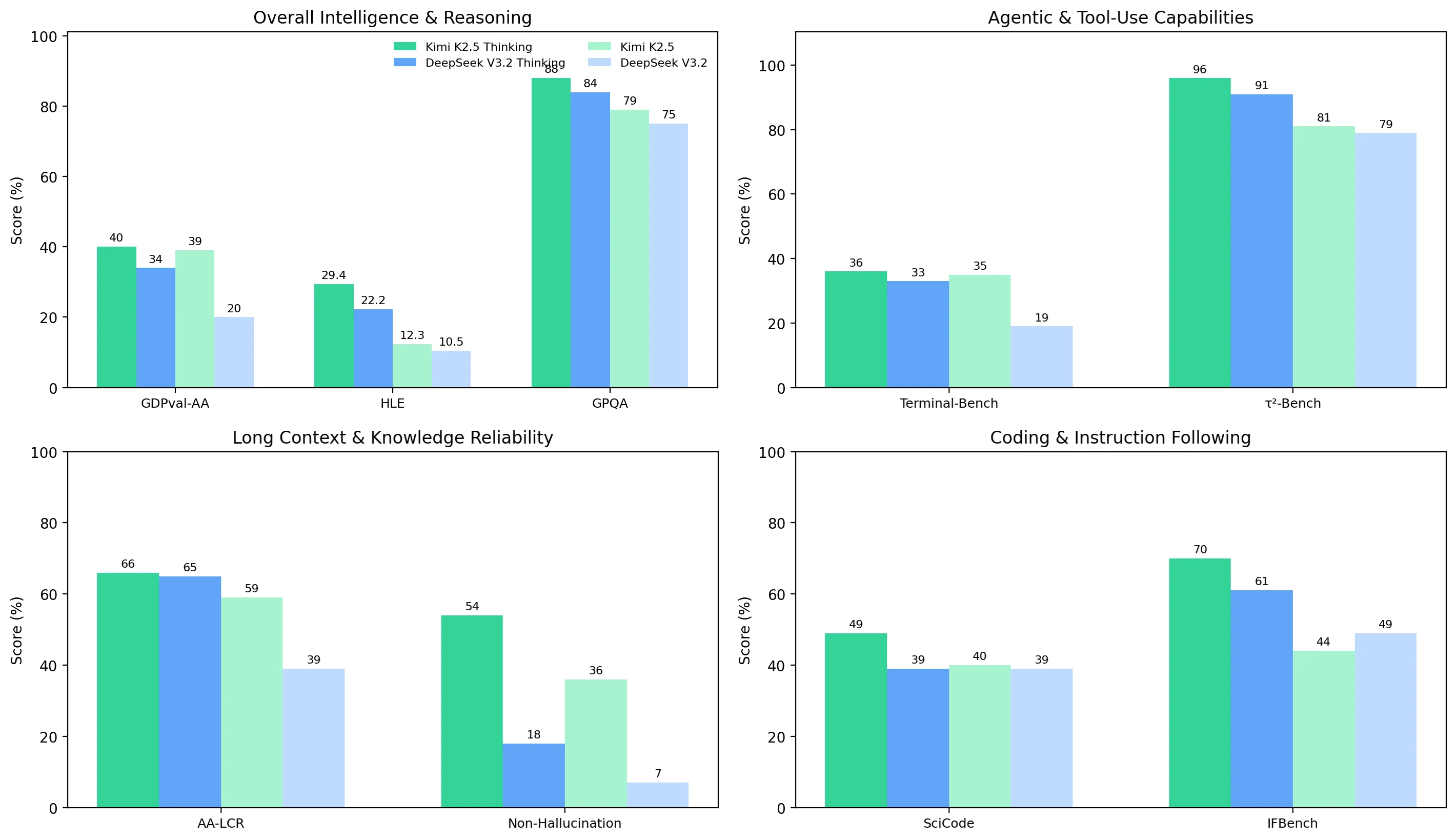
在四个基准测试集群中,Kimi K2.5 整体上比 DeepSeek V3.2 更稳定、更强,并且其思考模式在最困难的任务上带来了更大的质量提升:
- 整体智能与推理:Kimi 在两种模式下均领先(例如,思考模式下 GDPval-AA 40% vs 34%;GPQA 88% vs 84%)。
- 智能体与工具使用:Kimi 更强、更稳健,尤其在非思考模式下(Terminal-Bench Hard 35% vs 19%);思考模式缩小了差距但未完全消除(36% vs 33%)。
- 长上下文与可靠性:AA-LCR 在思考模式下接近(66% vs 65%),但幻觉控制是重要的区分因素——Kimi 的非幻觉率远高于 DeepSeek(思考模式下 54% vs 18%;非思考模式下 36% vs 7%)。
- 编码与指令遵循:非思考模式下编码能力相似(40% vs 39%),但 Kimi 在思考模式下优势明显(SciCode 49% vs 39%;IFBench 70% vs 61%)。
LM Arena(人类偏好)
上述基准测试集群表明Kimi K2.5 整体上更稳定、更强大。作为补充的“野外”信号,LM Arena 反映了人类在直接对决中的偏好(数据更新至 1月29日),并分为文本和编码两个领域。
✍文本竞技场:Kimi K2.5 思考模式 排名 #12(范围 #7–#21),得分 1450(±9);而 DeepSeek V3.2 思考模式 排名 #36(范围 #27–#51),得分 1420(±5)(DeepSeek V3.2 非思考模式排名 #37,范围 #28–#51,同样得分 1420(±5))。


💻编码竞技场:DeepSeek V3.2 思考模式 排名 #15(范围 #9–#16),得分 1372(+11/-11);而 Kimi K2 Thinking Turbo 排名 #20(范围 #18–#21),得分 1329(+8/-8)。


LM Arena 进一步证实了 Kimi 在文本用户体验方面的优势,同时也突显了 DeepSeek 在编码领域的领先潜力。
速度与延迟对比
| 指标 | Kimi K2.5 | DeepSeek V3.2 | Kimi K2.5 思考模式 | DeepSeek V3.2 思考模式 |
| 端到端响应时间(秒)— 500 个输出 token | 5.9 | 17.3 | 22.7 | 81.9 |
| 延迟/TTFT(秒)— 到第一个答案 token 的时间 | 1.1 | 1.2 | 18.3 | 65.7 |
| 输出速度(token/秒) | 103 | 31 | 116 | 31 |
解读
- 两种截然不同的运行状态: 在非思考模式下,Kimi K2.5 和 DeepSeek V3.2 在开始时表现相似(TTFT 约 1.1-1.2s),但随着输出增长,它们的完成时间很快出现分化——Kimi 完成 500 个 token 的响应需要 5.9s,而 DeepSeek 需要 17.3s。
- 思考模式将瓶颈转移到“启动时间”: 最主要的成本变成了等待第一个 token 出现之前的时间:Kimi K2.5 思考模式 TTFT 为 18.3s,DeepSeek V3.2 思考模式为 65.7s。这意味着思考模式不仅仅是“慢一点”,而是完全属于“不同的用户体验类别”。
- 吞吐量解释了端到端的差距: Kimi 能够维持 103-116 tok/s,而 DeepSeek 在两种模式下都停留在 31 tok/s——因此即使是在第一个 token 之后,DeepSeek 的生成速度仍然是限制因素。
成本对比
本节使用 Novita AI 的定价页面 中确切接口的价格:
| 模型(Novita 接口) | 输入 ($/Mt) | 缓存读取 ($/Mt) | 输出 ($/Mt) |
| moonshotai/kimi-k2.5 | 0.6 | 0.1 | 3 |
| deepseek/deepseek-v3.2 | 0.269 | 0.1345 | 0.4 |
成本直觉:
- 如果您的应用是输出密集型(长答案、代码生成),输出价格占主导地位——并且差距很大。
- 如果您的应用是输入密集型(大型 RAG 上下文、大量检索文本),DeepSeek 较低的输入价格可能具有吸引力——尤其是当您可以控制输出长度和/或使用缓存时。
如何部署:API、SDK 和第三方集成
选项 A:API
在 Novita AI 上获取 API 密钥
- 步骤 1:创建或登录您的账户:访问
[https://novita.ai](https://novita.ai)并注册或登录。 - 步骤 2:导航至密钥管理:登录后,找到“API Keys”。
- 步骤 3:创建新密钥:点击“Add New Key”按钮。
- 步骤 4:立即保存您的密钥:密钥生成后立即复制并存储;它只会显示一次。

通过接口调用 Novita
只需更改:
base_url:https://api.novita.ai/openaiapi_key:您的 Novita 密钥model:moonshotai/kimi-k2.5或deepseek/deepseek-v3.2
from openai import OpenAI
client = OpenAI(
api_key="<您的 API 密钥>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.5",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "你好,最近怎么样?"}
],
max_tokens=262144,
temperature=0.7
)
print(response.choices[0].message.content)
选项 B:SDK
如果您正在构建智能体工作流(路由、交接、工具/函数调用),Novita 与 兼容 OpenAI 的 SDK 配合使用,只需进行少量更改:
- 即插即用兼容:保留您现有的客户端逻辑;只需更改 base_url + model
- 编排就绪:轻松实现路由(默认 Flash → GLM-4.7 升级)
- 设置:指向
https://api.novita.ai/openai,设置NOVITA_API_KEY,选择moonshotai/kimi-k2.5或deepseek/deepseek-v3.2
选项 C:第三方平台
您还可以通过流行的生态系统运行 Novita 托管的模型:
- 智能体框架和应用构建器:按照 Novita 的分步集成指南,连接诸如 Continue、AnythingLLM、LangChain 和 Langflow 等流行工具。
- Hugging Face Hub:Novita 被列为 Hugging Face 上的推理提供者,因此您可以通过 Hugging Face 的提供者工作流和生态系统运行支持的模型。
- 兼容 OpenAI 的 API:Novita 的 LLM 接口兼容 OpenAI API 标准,使得迁移现有的 OpenAI 风格应用以及连接许多兼容 OpenAI 的工具(Cline、Cursor、Trae 和 Qwen Code)变得简单。
- 兼容 Anthropic 的 API:Novita 还提供兼容 Anthropic SDK 的访问方式,使您能够将 Novita 支持的模型集成到 Claude Code 风格的智能体编码工作流中。
- OpenCode:Novita AI 现已直接集成到 OpenCode 中,作为受支持的提供者,因此用户可以在 OpenCode 中选择 Novita,无需手动配置。
结论
Kimi K2.5 是更全面的选择(更稳定的基准测试表现、更显著的思考模式提升、以及更快的长输出速度),而 DeepSeek V3.2 则因较低的输入价格和在 LM Arena 编码领域的偏好优势,对输入密集型 RAG 场景具有吸引力。在 Novita AI 上,您可以在 Playground 中快速并排评估两者,然后部署最符合您产品在质量、响应速度和成本组合方面需求的模型。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时也提供经济实惠且可靠的 GPU 云服务用于构建和扩展。
常见问题解答
Kimi K2.5 是开源的吗?
Kimi K2.5 严格来说并非完全开源。它是 Moonshot AI 在 MIT 许可下发布的开放权重模型。模型权重和推理代码可公开获取,用于商业使用、本地部署和微调。然而,Moonshot AI 尚未发布其完整的训练代码、训练数据集或训练流程,因此无法从头完全复现该模型。
什么是 Kimi K2.5?
Kimi K2.5 是由 Moonshot AI 开发的升级版多模态大语言模型。作为 Kimi K2 的继任者,它支持包括文本、图像和视频在内的多模态输入。在对话质量、逻辑推理、长上下文处理和多模态理解方面性能有所提升,并允许用户通过其开放权重在本地部署和自定义模型。
Kimi 比 DeepSeek 更好吗?
没有一种模型在所有场景下都是“更好”的。在我们的评估中,Kimi 和 DeepSeek 在推理、智能体任务、成本和延迟等方面各有优势。正确的选择取决于您的工作负载、性能目标和预算。通过 Novita AI,您可以轻松在 Playground 中并排测试这两个模型,并选择最适合您实际使用场景的模型。



