

- Pourquoi Qwen3-Next-80B-A3B peut rivaliser avec un modèle de 235B ?
- Pourquoi choisir Trae comme outil d'agent de code ?
- Comment Qwen3-Next-80B-A3B + Trae améliore les capacités ?
- Comment utiliser Qwen3-Next-80B-A3B via Trae ?
- Qwen 3 Coder 480B A35B avec Trae
- Limites et dépannage pour Qwen3-Next-80B-A3B dans Trae
Un examen approfondi de Trae en tant qu’outil d’agent de code révèle un environnement de développement intégré (IDE) puissant et polyvalent, conçu pour améliorer le processus de développement logiciel grâce à l’intelligence artificielle. Lorsqu’il est combiné à des modèles de langage avancés (LLM) comme Qwen3-Next-80B-A3B, les capacités de Trae sont considérablement améliorées, offrant une boîte à outils performante pour les développeurs. Ce rapport explore les raisons de choisir Trae, les améliorations qu’il tire de Qwen3-Next-80B-A3B, les instructions pour leur intégration, ainsi que les limites potentielles et les mesures de dépannage.
Pourquoi Qwen3-Next-80B-A3B peut rivaliser avec un modèle de 235B ?
Qwen3-Next-80B-A3B est le premier modèle de la série Qwen3-Next, conçu pour gérer des charges de travail massives et à contexte long avec une efficacité et une stabilité remarquables. Grâce à des mécanismes d’attention innovants, une utilisation plus intelligente des ressources, une robustesse accrue et un entraînement et une inférence plus rapides, il offre des performances puissantes pour des applications réelles exigeantes.
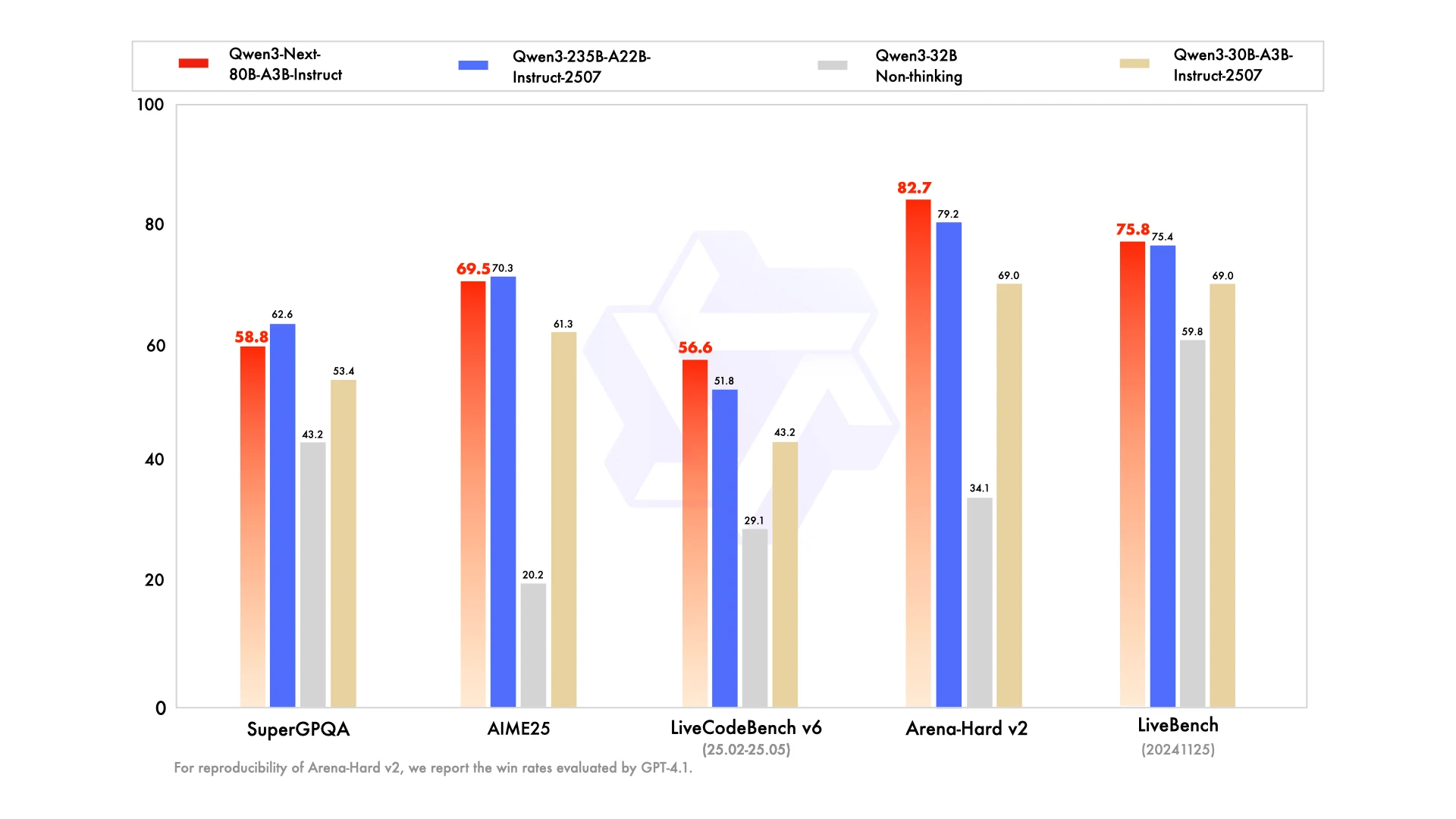
Depuis Hugging Face
Pourquoi choisir Trae comme outil d’agent de code ?
Programmation IA basée sur des agents
La capacité définitive de Trae est son flux de travail agentique. Propulsé par des agents IA, il peut gérer de manière autonome des tâches complexes avec un minimum d’orientation de l’utilisateur. Cette fonctionnalité est centrée autour de deux modes principaux :
- Mode Constructeur : Décompose automatiquement les grands projets en tâches plus petites et séquentielles, et applique des modifications de code sur plusieurs fichiers.
- Mode Chat : Fournit une interface interactive en langage naturel pour poser des questions, déboguer et demander des extraits de code.
Assistance intelligente et consciente du contexte
Trae va au-delà de l’autocomplétion en offrant une conscience profonde du contexte. Il fournit une détection de bugs en temps réel, une analyse de vulnérabilités et des suggestions de refactorisation, en s’appuyant sur l’ensemble de l’environnement du projet — y compris les fichiers et les interactions avec le terminal — pour construire une compréhension holistique.
Interaction multimodale
Les développeurs peuvent aller au-delà du texte en téléchargeant des images, des diagrammes ou des captures d’écran. Trae interprète ces entrées, ce qui est particulièrement utile pour des tâches comme la conversion de maquettes de conception en code.
Extensibilité et personnalisation
Trae prend en charge un écosystème IA flexible. Les développeurs peuvent intégrer des modèles tiers — y compris des options de pointe comme Claude 3.7 et GPT-4o — via des clés API. Il permet également la création d’agents personnalisés, adaptés à des flux de travail spécifiques, offrant aux utilisateurs la liberté d’adapter l’automatisation à leurs besoins.
Accessible et gratuit
L’un des plus grands avantages de Trae est son accessibilité : ses fonctionnalités principales sont proposées gratuitement, ce qui réduit la barrière d’entrée pour les outils de développement avancés alimentés par l’IA. Des plans premium existent pour des fonctionnalités supplémentaires, mais la boîte à outils essentielle reste gratuite.
Intégration transparente
Construit sur la base familière de VS Code, Trae assure une transition confortable pour les développeurs. Il s’intègre également en douceur avec des plateformes populaires comme GitHub, s’inscrivant naturellement dans les flux de travail existants.
Comment Qwen3-Next-80B-A3B + Trae améliore les capacités ?
Raisonnement amélioré pour les tâches d’agent
La série inclut une variante « Thinking » (Qwen3-Next-80B-A3B-Thinking), spécialement conçue pour le raisonnement approfondi et la génération de chaînes de pensée plus longues. Lorsqu’il alimente les agents de Trae, ce modèle permet une résolution de problèmes plus avancée, prend en charge une décomposition de tâches plus efficace en Mode Constructeur et fournit des réponses plus pertinentes en Mode Chat.
Gestion efficace des grandes bases de code
Qwen3-Next est optimisé pour des fenêtres de contexte ultra-longues, avec une prise en charge native jusqu’à 262 144 tokens et une extensibilité à 1 million de tokens. Au sein de Trae, cela permet au modèle d’acquérir une compréhension plus large de l’ensemble de la base de code, ce qui se traduit par une génération de code et une analyse plus précises et contextuellement pertinentes.
https://www.reddit.com/r/Trae_ai/comments/1m8u2kd/trae_agent_is_so_eager_to_code_and_have_a_bad/
Performances rentables
En s’appuyant sur une architecture sparse Mixture-of-Experts (MoE), Qwen3-Next atteint une efficacité computationnelle supérieure à celle des modèles denses de taille similaire. Cela permet aux développeurs de tirer parti des capacités d’un modèle de 80B paramètres dans Trae sans encourir de coûts prohibitifs ou de latence importante — en particulier lorsqu’ils utilisent leurs propres clés API.
Suivi d’instructions professionnel
La variante « Instruct » (Qwen3-Next-80B-A3B-Instruct) est optimisée pour une adhésion stable et fiable aux instructions. Cela la rend particulièrement adaptée aux tâches dans Trae qui nécessitent une génération de code précise, une refactorisation ou le respect de règles de formatage spécifiques.
Comment utiliser Qwen3-Next-80B-A3B via Trae ?
Étape 1 : Obtenir une clé API
Étape 1 : Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez Qwen3-Next-80B-A3B dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation. Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
Qwen 3 Coder 480B A35B avec Trae
Étape 1 : Ouvrez Trae et accédez aux modèles
Lancez l’application Trae. Cliquez sur le bouton Basculer la barre latérale IA dans le coin supérieur droit pour ouvrir la barre latérale IA. Ensuite, accédez à Gestion IA et sélectionnez Modèles.

Étape 2 : Ajoutez un modèle personnalisé et choisissez Novita comme fournisseur
Cliquez sur le bouton Ajouter un modèle pour créer une entrée de modèle personnalisé. Dans la boîte de dialogue d’ajout de modèle, sélectionnez Fournisseur = Novita dans le menu déroulant.


Étape 3 : Sélectionnez ou saisissez le modèle
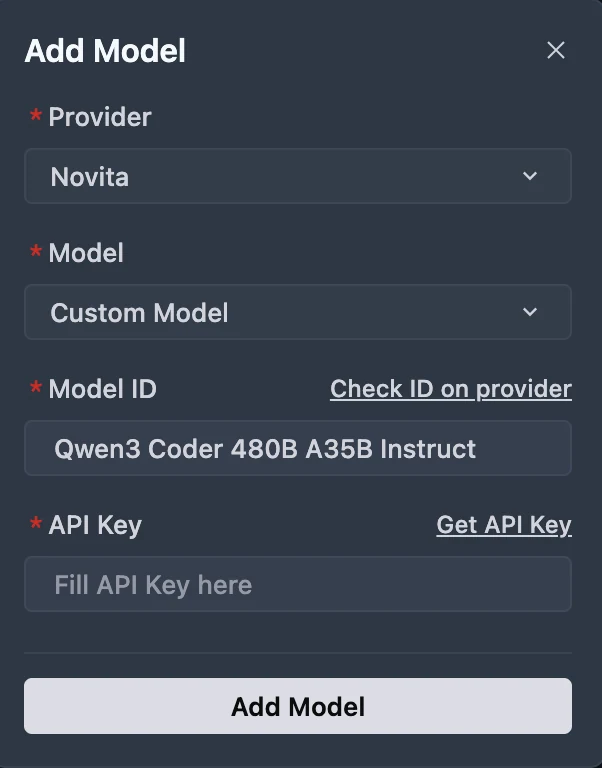
Dans le menu déroulant Modèle, choisissez le modèle souhaité (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324 ou MiniMax-M1-80k). Si le modèle exact n’est pas répertorié, saisissez simplement l’ID du modèle que vous avez noté dans la bibliothèque Novita. Assurez-vous de choisir la variante correcte du modèle que vous souhaitez utiliser.
Vous pouvez obtenir une clé API sur la console Novita !
Limites et dépannage pour Qwen3-Next-80B-A3B dans Trae
Limites connues des modèles MoE sparse
Exigences mémoire élevées pour l’inférence
Bien que les modèles MoE sparse soient efficaces sur le plan computationnel pendant l’inférence, ils nécessitent toujours que tous les paramètres des experts soient chargés en mémoire. Cela signifie que l’exécution d’un modèle comme Qwen3-Next-80B-A3B — même localement — demande une quantité substantielle de VRAM.
Non-déterminisme
Les modèles MoE sparse peuvent présenter un degré de non-déterminisme plus élevé, même avec un paramètre de température de 0. Ce comportement est souvent lié à la nature de l’inférence par lots dans l’architecture, qui peut produire des sorties légèrement différentes pour la même entrée.
Défis d’entraînement et de spécialisation
Même si cela ne concerne pas directement l’utilisateur final, l’entraînement des modèles MoE sparse présente ses propres défis. S’assurer que les experts se spécialisent correctement et gérer l’équilibre de charge sont des étapes critiques ; si elles ne sont pas abordées, ces facteurs peuvent avoir un impact sur la qualité et la fiabilité globales du modèle.
Complexité du déploiement local
L’exécution de Qwen3-Next-80B-A3B en local peut être complexe. Elle nécessite souvent des bibliothèques à jour, des configurations matérielles spécifiques et un dépannage de problèmes — tels que des problèmes de compatibilité avec des frameworks comme vLLM sous certains paramètres de déchargement.
Conseils de dépannage
Redémarrez ou rechargez
En cas de problèmes tels qu’un comportement inattendu ou un gel de l’IDE, essayez de recharger la fenêtre ou de redémarrer l’application.
Utilisez des modèles personnalisés
Pour contourner les files d’attente des modèles natifs de Trae, connectez un modèle personnalisé depuis des fournisseurs comme OpenRouter ou Alibaba Cloud.
Vérifiez les mises à jour
Assurez-vous d’utiliser la dernière version de Trae, car les nouvelles versions corrigent souvent des bugs et améliorent la stabilité.
Accélération matérielle
Si vous rencontrez des erreurs de fermeture de fenêtre ou des bugs graphiques, la désactivation de l’accélération matérielle dans les paramètres de Trae peut aider.
Consultez la documentation et la communauté
Pour des problèmes liés à des modèles personnalisés ou à des fonctionnalités avancées, reportez-vous à la documentation officielle de Trae. Les forums communautaires comme Reddit sont également de bonnes sources de solutions et d’astuces proposées par les utilisateurs.
Pour les problèmes liés à Qwen3-Next
Lors du déploiement ou de l’utilisation de Qwen3-Next via une API, suivez les paramètres recommandés pour les paramètres d’échantillonnage et la longueur de contexte dans sa documentation. Si vous rencontrez des erreurs de mémoire insuffisante, réduire la longueur du contexte peut résoudre le problème.
La combinaison de Qwen3-Next-80B-A3B et Trae crée un environnement de développement puissant qui rivalise même avec des modèles beaucoup plus grands. Qwen3-Next apporte un raisonnement avancé, une compréhension de contexte long et des performances MoE efficaces, tandis que Trae fournit un IDE piloté par des agents, conçu pour la collaboration, l’automatisation et l’intégration transparente du contexte. Ensemble, ils permettent aux développeurs de gérer des bases de code massives, d’accélérer des flux de travail complexes et d’accéder à une assistance IA de pointe — le tout avec flexibilité et rentabilité.
Foire aux questions
Pourquoi Qwen3-Next-80B-A3B peut-il rivaliser avec un modèle de 235B ?
Grâce à des mécanismes d’attention innovants, une allocation plus intelligente des ressources et l’efficacité MoE sparse, il offre des performances comparables à celles de modèles denses plus grands, tout en maintenant une inférence plus rapide et des coûts plus bas.
Pourquoi devrais-je choisir Trae comme outil d’agent de code ?
Trae propose une programmation basée sur des agents avec le Mode Constructeur et le Mode Chat, une conscience profonde du contexte, des entrées multimodales, une extensibilité avec des modèles tiers et une intégration transparente avec VS Code et GitHub — le tout avec un point d’entrée gratuit.
Comment Qwen3-Next-80B-A3B et Trae fonctionnent-ils ensemble ?
Qwen3-Next améliore Trae avec un raisonnement supérieur, une compréhension des grandes bases de code, des performances rentables et un suivi d’instructions solide. Cela permet aux agents de Trae de traiter de manière autonome des tâches de codage et de refactorisation complexes.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



