

- ¿Por qué Qwen3-Next-80B-A3B puede competir con un modelo de 235B?
- ¿Por qué elegir Trae como herramienta de agente de código?
- ¿Cómo Qwen3-Next-80B-A3B + Trae potencia el desarrollo?
- ¿Cómo usar Qwen3-Next-80B-A3B a través de Trae?
- Qwen 3 Coder 480B A35B con Trae
- Limitaciones y solución de problemas de Qwen3-Next-80B-A3B en Trae
Un análisis exhaustivo de Trae como herramienta de agente de código revela un entorno de desarrollo integrado (IDE) potente y versátil, diseñado para mejorar el proceso de desarrollo de software con inteligencia artificial. Cuando se combina con modelos de lenguaje avanzados (LLM, por sus siglas en inglés) como Qwen3-Next-80B-A3B, las capacidades de Trae se ven significativamente mejoradas, ofreciendo un conjunto de herramientas potente para los desarrolladores. Este informe profundiza en las razones para elegir Trae, la mejora que obtiene de Qwen3-Next-80B-A3B, las instrucciones para su integración, así como las posibles limitaciones y medidas de solución de problemas.
¿Por qué Qwen3-Next-80B-A3B puede competir con un modelo de 235B?
Qwen3-Next-80B-A3B es el primer modelo de la serie Qwen3-Next, diseñado para manejar cargas de trabajo masivas y de contexto largo con una eficiencia y estabilidad notables. Mediante mecanismos de atención innovadores, un uso más inteligente de los recursos, una robustez mejorada y un entrenamiento e inferencia más rápidos, ofrece un rendimiento potente para aplicaciones del mundo real exigentes.
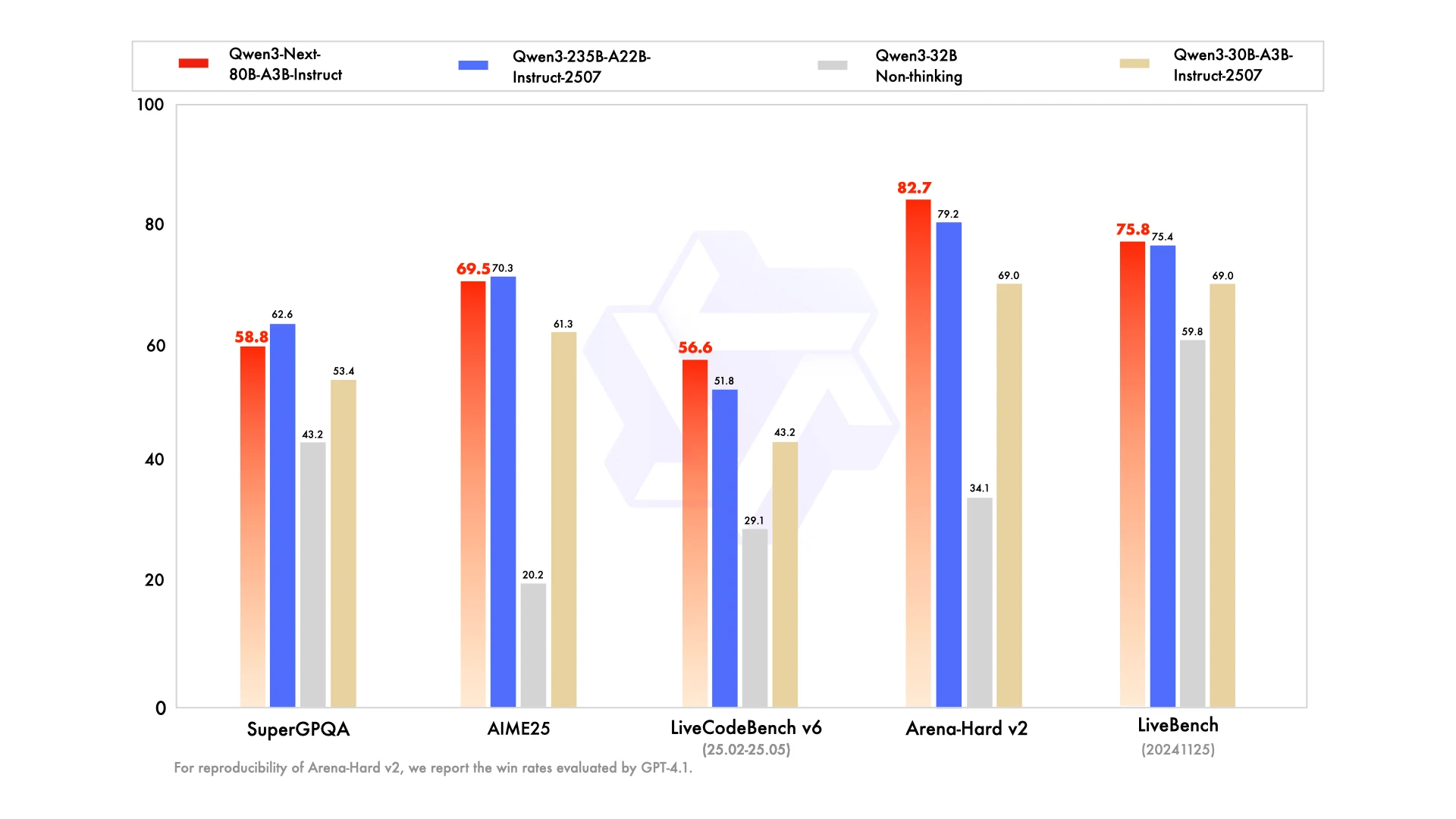
De Hugging Face
¿Por qué elegir Trae como herramienta de agente de código?
Programación de IA basada en agentes
La capacidad definitoria de Trae es su flujo de trabajo agéntico. Impulsado por agentes de IA, puede manejar de forma autónoma tareas complejas con una orientación mínima del usuario. Esta funcionalidad se centra en dos modos principales:
- Builder Mode: Descompone automáticamente proyectos grandes en tareas más pequeñas y secuenciales, y aplica cambios de código en múltiples archivos.
- Chat Mode: Proporciona una interfaz interactiva de lenguaje natural para hacer preguntas, depurar y solicitar fragmentos de código.
Asistencia inteligente y consciente del contexto
Trae va más allá del autocompletado al ofrecer conciencia profunda del contexto. Proporciona detección de errores en tiempo real, análisis de vulnerabilidades y sugerencias de refactorización, basándose en todo el entorno del proyecto, incluidos archivos e interacciones con la terminal, para construir una comprensión holística.
Interacción multimodal
Los desarrolladores pueden ir más allá del texto cargando imágenes, diagramas o capturas de pantalla. Trae interpreta estas entradas, lo que lo hace especialmente útil para tareas como convertir maquetas de diseño en código.
Extensibilidad y personalización
Trae es compatible con un ecosistema de IA flexible. Los desarrolladores pueden integrar modelos de terceros, incluidas opciones de última generación como Claude 3.7 y GPT-4o, mediante claves de API. También permite la creación de agentes personalizados específicos del flujo de trabajo, lo que brinda a los usuarios la libertad de adaptar la automatización a sus necesidades.
Accesible y de uso gratuito
Una de las mayores ventajas de Trae es su accesibilidad: sus funciones principales se ofrecen de forma gratuita, lo que reduce la barrera de entrada para las herramientas de desarrollo avanzadas impulsadas por IA. Si bien existen planes premium para funcionalidades adicionales, el conjunto de herramientas esencial se mantiene gratuito.
Integración perfecta
Construido sobre la base familiar de VS Code, Trae garantiza una transición cómoda para los desarrolladores. También se integra sin problemas con plataformas populares como GitHub, encajando de forma natural en los flujos de trabajo existentes.
¿Cómo Qwen3-Next-80B-A3B + Trae potencia el desarrollo?
Razonamiento mejorado para tareas de agente
La serie incluye una variante “Thinking” (Qwen3-Next-80B-A3B-Thinking), diseñada específicamente para el razonamiento profundo y la generación de cadenas de pensamiento más largas. Al impulsar los agentes de Trae, este modelo permite una resolución de problemas más avanzada, admite una descomposición de tareas más efectiva en el Builder Mode y ofrece respuestas más perspicaces en el Chat Mode.
Gestión eficiente de bases de código grandes
Qwen3-Next está optimizado para ventanas de contexto ultra largas, con soporte nativo de hasta 262.144 tokens y extensibilidad hasta 1 millón de tokens. Dentro de Trae, esto permite que el modelo obtenga una comprensión más amplia de toda la base de código, lo que se traduce en una generación y análisis de código más precisos y relevantes para el contexto.
Rendimiento rentable
Aprovechando una arquitectura dispersa Mixture-of-Experts (MoE), Qwen3-Next logra una eficiencia computacional superior a la de los modelos densos de escala similar. Esto permite a los desarrolladores aprovechar las capacidades de un modelo de 80B parámetros en Trae sin incurrir en costos prohibitivos o latencia significativa, especialmente cuando usan sus propias claves de API.
Seguimiento profesional de instrucciones
La variante “Instruct” (Qwen3-Next-80B-A3B-Instruct) está optimizada para un cumplimiento de instrucciones estable y fiable. Esto la hace especialmente adecuada para tareas en Trae que requieren una generación de código precisa, refactorización o cumplimiento de reglas de formato específicas.
¿Cómo usar Qwen3-Next-80B-A3B a través de Trae?
El primer paso: Obtén tu clave de API
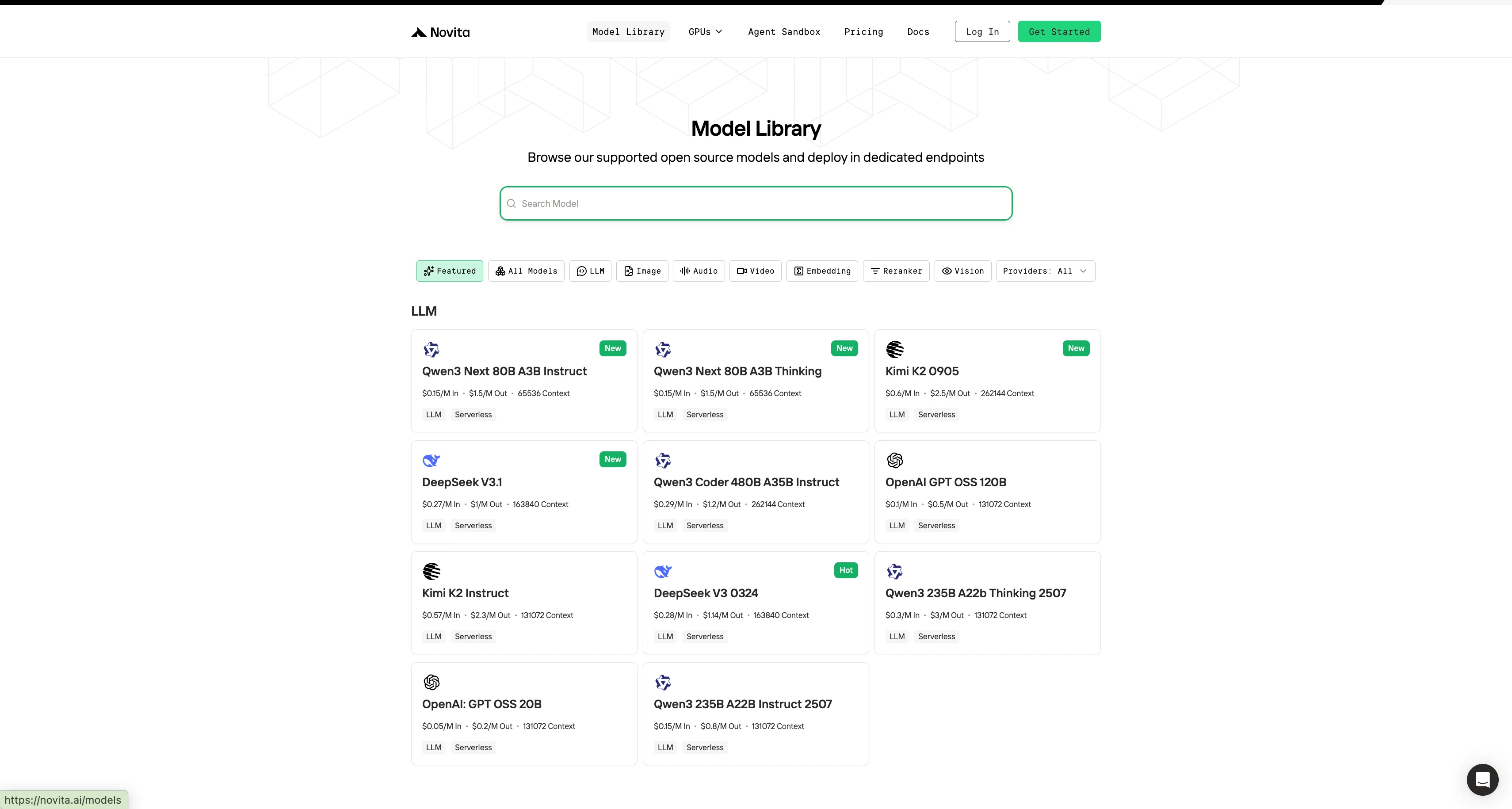
Paso 1: Inicia sesión en tu cuenta y haz clic en el botón de Biblioteca de Modelos.

¡Prueba Qwen3-Next-80B-A3B ahora!
Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Al ingresar a la página de “Configuración“, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API utilizando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
Qwen 3 Coder 480B A35B con Trae
Paso 1: Abre Trae y accede a los modelos
Inicia la aplicación de Trae. Haz clic en el botón de Alternar barra lateral de IA en la esquina superior derecha para abrir la barra lateral de IA. Luego, ve a Gestión de IA y selecciona Modelos.

Paso 2: Agrega un modelo personalizado y elige Novita como proveedor
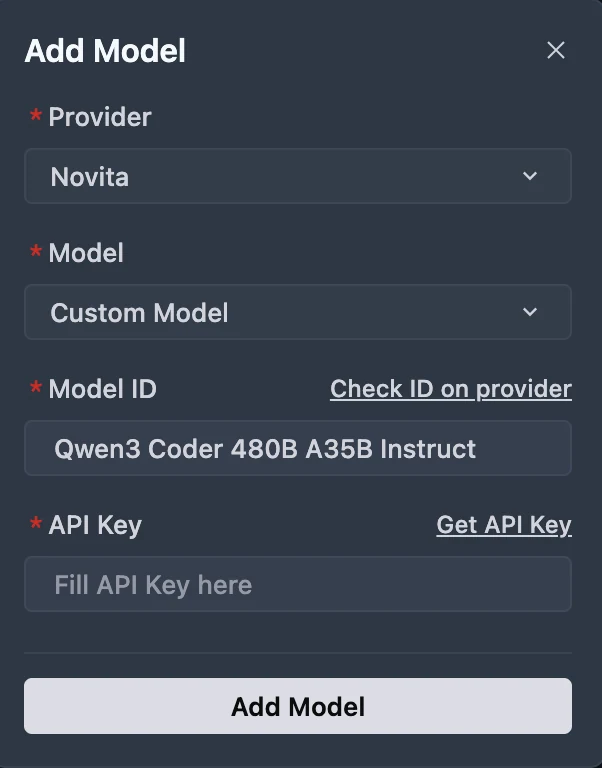
Haz clic en el botón Agregar modelo para crear una entrada de modelo personalizado. En el diálogo de agregar modelo, selecciona Proveedor = Novita en el menú desplegable.


Paso 3: Selecciona o ingresa el modelo
En el menú desplegable de Modelo, selecciona el modelo que desees (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324 o MiniMax-M1-80k). Si el modelo exacto no aparece en la lista, simplemente escribe el ID del modelo que anotaste de la biblioteca de Novita. Asegúrate de elegir la variante correcta del modelo que quieres usar.
Puedes obtener la clave de API en la consola de Novita!
Limitaciones y solución de problemas de Qwen3-Next-80B-A3B en Trae
Limitaciones conocidas de los modelos MoE dispersos
Requisitos altos de memoria para la inferencia
Aunque los modelos MoE dispersos son computacionalmente eficientes durante la inferencia, aún requieren que todos los parámetros de los expertos se carguen en la memoria. Esto significa que ejecutar un modelo como Qwen3-Next-80B-A3B, incluso de forma local, demanda una cantidad sustancial de VRAM.
No determinismo
Los modelos MoE dispersos pueden mostrar un mayor grado de no determinismo, incluso con una configuración de temperatura de 0. Este comportamiento suele estar relacionado con la naturaleza de la inferencia por lotes en la arquitectura, que puede producir salidas ligeramente diferentes para la misma entrada.
Desafíos de entrenamiento y especialización
Si bien no es una preocupación directa para el usuario final, el entrenamiento de modelos MoE dispersos presenta sus propios desafíos. Garantizar que los expertos se especialicen correctamente y gestionar el equilibrio de carga son pasos críticos; si no se abordan, estos factores pueden afectar la calidad y fiabilidad generales del modelo.
Complejidad de la implementación local
Ejecutar Qwen3-Next-80B-A3B de forma local puede ser complejo. A menudo requiere bibliotecas actualizadas, configuraciones de hardware específicas y solución de problemas, como problemas de compatibilidad con frameworks como vLLM en determinadas configuraciones de descarga.
Consejos para la solución de problemas
Reiniciar o recargar
Para problemas como comportamiento inesperado o bloqueo del IDE, prueba a recargar la ventana o reiniciar la aplicación.
Usar modelos personalizados
Para evitar las colas de los modelos nativos de Trae, conecta un modelo personalizado de proveedores como OpenRouter o Alibaba Cloud.
Buscar actualizaciones
Asegúrate de ejecutar la última versión de Trae, ya que las nuevas versiones suelen corregir errores y mejorar la estabilidad.
Aceleración de hardware
Si encuentras errores de cierre de ventana o fallos gráficos, desactivar la aceleración de hardware en la configuración de Trae puede ayudar.
Consultar la documentación y la comunidad
Para problemas con modelos personalizados o funciones avanzadas, consulta la documentación oficial de Trae. Los foros de la comunidad como Reddit también son buenas fuentes de soluciones y alternativas aportadas por los usuarios.
Para problemas con Qwen3-Next
Al implementar o usar Qwen3-Next a través de una API, sigue la configuración recomendada para parámetros de muestreo y longitud de contexto de su documentación. Si te encuentras con errores de falta de memoria, reducir la longitud de contexto puede resolver el problema.
La combinación de Qwen3-Next-80B-A3B y Trae crea un entorno de desarrollo potente que compite incluso con modelos mucho más grandes. Qwen3-Next aporta razonamiento avanzado, comprensión de contexto largo y un rendimiento MoE eficiente, mientras que Trae ofrece un IDE impulsado por agentes diseñado para la colaboración, la automatización y la integración perfecta del contexto. Juntos, capacitan a los desarrolladores para gestionar bases de código masivas, acelerar flujos de trabajo complejos y acceder a asistencia de IA de vanguardia, todo con flexibilidad y eficiencia de costos.
Preguntas frecuentes
¿Por qué Qwen3-Next-80B-A3B puede competir con un modelo de 235B?
Mediante mecanismos de atención innovadores, una asignación de recursos más inteligente y la eficiencia de MoE disperso, ofrece un rendimiento comparable al de los modelos densos más grandes, manteniendo al mismo tiempo una inferencia más rápida y costos más bajos.
¿Por qué debería elegir Trae como mi herramienta de agente de código?
Trae proporciona programación basada en agentes con el Builder Mode y el Chat Mode, conciencia profunda del contexto, entradas multimodales, extensibilidad con modelos de terceros e integración perfecta con VS Code y GitHub, todo con un punto de entrada gratuito.
¿Cómo funcionan juntos Qwen3-Next-80B-A3B y Trae?
Qwen3-Next mejora Trae con un razonamiento superior, comprensión de bases de código grandes, rendimiento rentable y un seguimiento de instrucciones sólido. Esto permite que los agentes de Trae aborden de forma autónoma tareas complejas de codificación y refactorización.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



