

Ein detaillierter Blick auf Trae als Code-Agent-Tool offenbart eine leistungsstarke und vielseitige integrierte Entwicklungsumgebung (IDE), die darauf ausgelegt ist, den Softwareentwicklungsprozess mit künstlicher Intelligenz zu erweitern. In Kombination mit fortschrittlichen Large Language Models (LLMs) wie Qwen3-Next-80B-A3B werden die Fähigkeiten von Trae deutlich verbessert und bieten Entwicklern ein leistungsfähiges Toolkit. Dieser Bericht geht auf die Gründe für die Wahl von Trae, die Stärkung durch Qwen3-Next-80B-A3B, Anweisungen zur Integration sowie mögliche Einschränkungen und Fehlerbehebungsmaßnahmen ein.
Warum Qwen3-Next-80B-A3B mit einem 235B-Modell mithalten kann?
Qwen3-Next-80B-A3B ist das erste Modell der Qwen3-Next-Serie, das für die effiziente und stabile Verarbeitung von massiven und langen Kontext-Workloads entwickelt wurde. Durch innovative Aufmerksamkeitsmechanismen, intelligentere Ressourcennutzung, verbesserte Robustheit sowie schnellere Training und Inferenz liefert es leistungsstarke Ergebnisse für anspruchsvolle praktische Anwendungen.
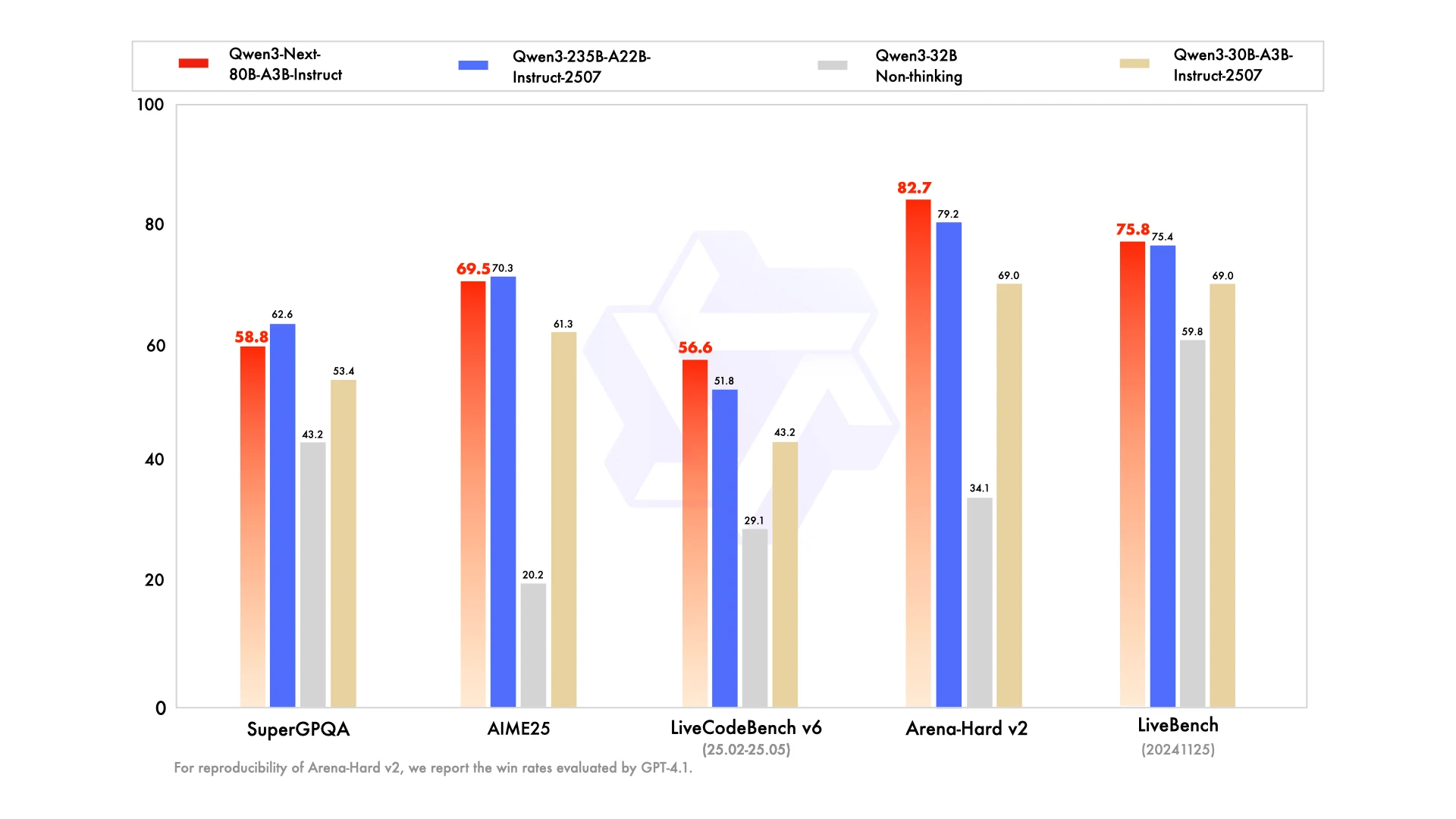
Von Hugging Face
Warum Trae als Code-Agent-Tool wählen?
Agentenbasierte KI-Programmierung
Die definierende Fähigkeit von Trae ist sein agentischer Workflow. Unterstützt von KI-Agenten kann es komplexe Aufgaben mit minimaler Benutzeranleitung autonom bearbeiten. Diese Funktionalität konzentriert sich auf zwei Hauptmodi:
- Builder-Modus: Zerlegt große Projekte automatisch in kleinere, sequenzielle Aufgaben und wendet Codeänderungen über mehrere Dateien hinweg an.
- Chat-Modus: Bietet eine interaktive, natürlichsprachliche Oberfläche zum Stellen von Fragen, Debuggen und Anfordern von Code-Snippets.
Intelligente, kontextbewusste Unterstützung
Trae geht über Autovervollständigung hinaus und bietet tiefes Kontextbewusstsein. Es liefert Echtzeit-Fehlererkennung, Schwachstellenanalyse und Refactoring-Vorschläge, wobei es die gesamte Projektumgebung – einschließlich Dateien und Terminal-Interaktionen – nutzt, um ein ganzheitliches Verständnis aufzubauen.
Multimodale Interaktion
Entwickler können über Text hinausgehen, indem sie Bilder, Diagramme oder Screenshots hochladen. Trae interpretiert diese Eingaben, was es besonders nützlich für Aufgaben wie die Umwandlung von Design-Mockups in Code macht.
Erweiterbarkeit & Anpassung
Trae unterstützt ein flexibles KI-Ökosystem. Entwickler können Drittanbieter-Modelle – einschließlich modernster Optionen wie Claude 3.7 und GPT-4o – über API-Schlüssel integrieren. Es ermöglicht auch die Erstellung benutzerdefinierter, workflow-spezifischer Agenten, sodass Benutzer die Freiheit haben, die Automatisierung an ihre Bedürfnisse anzupassen.
Zugänglich und kostenlos nutzbar
Einer der größten Vorteile von Trae ist die Zugänglichkeit: Seine Kernfunktionen werden kostenlos angeboten, was die Einstiegshürde für fortschrittliche KI-gestützte Entwicklungstools senkt. Während es Premium-Pläne für zusätzliche Funktionen gibt, bleibt das essentielle Toolkit kostenlos.
Nahtlose Integration
Auf der vertrauten Grundlage von VS Code aufgebaut, sorgt Trae für einen komfortablen Übergang für Entwickler. Es integriert sich auch reibungslos mit beliebten Plattformen wie GitHub und passt natürlich in bestehende Workflows.
Wie Qwen3-Next-80B-A3B + Trae Entwickler stärkt?
Verbessertes Reasoning für Agentenaufgaben
Die Serie umfasst eine “Thinking”-Variante (Qwen3-Next-80B-A3B-Thinking), die speziell für tiefes Reasoning und die Generierung längerer Gedankenketten entwickelt wurde. Wenn es die Agenten von Trae antreibt, ermöglicht dieses Modell fortgeschrittenere Problemlösungen, unterstützt effektivere Aufgabenzerlegung im Builder-Modus und liefert aufschlussreichere Antworten im Chat-Modus.
Effiziente Verarbeitung großer Codebasen
Qwen3-Next ist für ultra-lange Kontextfenster optimiert, mit nativer Unterstützung für bis zu 262.144 Token und Erweiterbarkeit auf 1 Million Token. Innerhalb von Trae ermöglicht dies dem Modell, ein breiteres Verständnis der gesamten Codebasis zu erlangen, was zu genauerer und kontextuell relevanterer Codegenerierung und Analyse führt.
Kosteneffiziente Leistung
Durch die Nutzung einer sparse Mixture-of-Experts (MoE)-Architektur erreicht Qwen3-Next eine rechnerische Effizienz, die dichterer Modelle ähnlicher Größe überlegen ist. Dies ermöglicht Entwicklern, die Fähigkeiten eines 80B-Parameter-Modells in Trae zu nutzen, ohne prohibitive Kosten oder signifikante Latenz zu verursachen – insbesondere bei Verwendung eigener API-Schlüssel.
Professionelle Befolgung von Anweisungen
Die “Instruct”-Variante (Qwen3-Next-80B-A3B-Instruct) ist für stabile und zuverlässige Befolgung von Anweisungen optimiert. Dies macht sie besonders geeignet für Aufgaben in Trae, die präzise Codegenerierung, Refactoring oder Einhaltung spezifischer Formatierungsregeln erfordern.
Wie verwendet man Qwen3-Next-80B-A3B über Trae?
Zuerst: API-Schlüssel holen
Schritt 1: Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Probieren Sie Qwen3-Next-80B-A3B jetzt aus!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite “Einstellungen” können Sie den API-Schlüssel wie im Bild gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Nutzer.
#Chat API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
#Completion API
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.completions.create(
model="qwen/qwen3-next-80b-a3b-instruct",
prompt="The following is a conversation with an AI assistant.",
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].text)
Qwen 3 Coder 480B A35B mit Trae
Schritt 1: Öffnen Sie Trae und greifen Sie auf Modelle zu
Starten Sie die Trae-App. Klicken Sie oben rechts auf die Schaltfläche “KI-Seitenleiste umschalten”, um die KI-Seitenleiste zu öffnen. Gehen Sie dann zu KI-Verwaltung und wählen Sie Modelle aus.

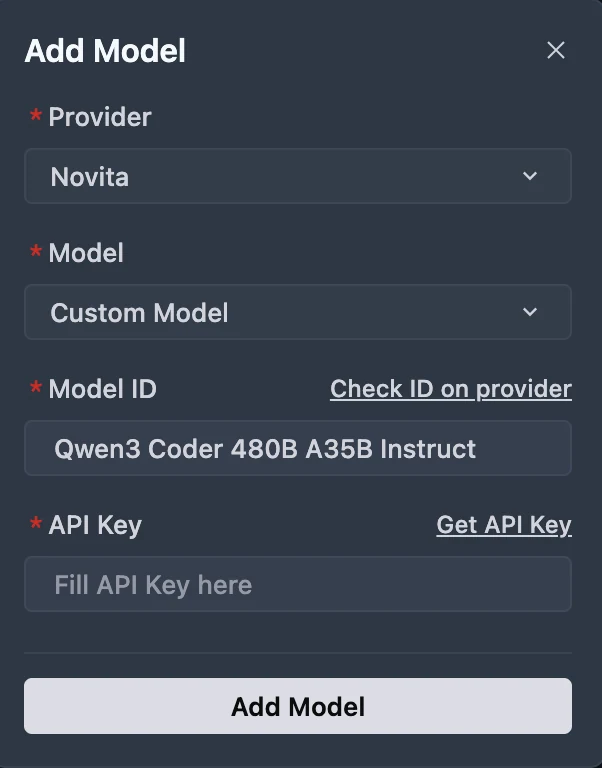
Schritt 2: Fügen Sie ein benutzerdefiniertes Modell hinzu und wählen Sie Novita als Anbieter aus
Klicken Sie auf die Schaltfläche Modell hinzufügen, um einen benutzerdefinierten Modelleintrag zu erstellen. Wählen Sie im Dialogfeld “Modell hinzufügen” aus dem Dropdown-Menü Anbieter = Novita aus.


Schritt 3: Wählen oder geben Sie das Modell ein
Wählen Sie aus dem Modell-Dropdown Ihr gewünschtes Modell aus (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324 oder MiniMax-M1-80k). Wenn das genaue Modell nicht aufgeführt ist, geben Sie einfach die Modell-ID ein, die Sie aus der Novita-Bibliothek notiert haben. Stellen Sie sicher, dass Sie die korrekte Variante des Modells auswählen, das Sie verwenden möchten.
Sie können den API-Schlüssel auf der Novita-Konsole! holen.
Einschränkungen und Fehlerbehebung für Qwen3-Next-80B-A3B in Trae
Bekannte Einschränkungen von Sparse-MoE-Modellen
Hoher Speicherbedarf für die Inferenz
Obwohl sparse MoE-Modelle während der Inferenz rechnerisch effizient sind, müssen dennoch alle Expertenparameter in den Speicher geladen werden. Dies bedeutet, dass die Ausführung eines Modells wie Qwen3-Next-80B-A3B – selbst lokal – eine erhebliche Menge an VRAM erfordert.
Nicht-Determinismus
Sparse MoE-Modelle können einen höheren Grad an Nicht-Determinismus aufweisen, selbst bei einer Temperatureinstellung von 0. Dieses Verhalten hängt oft mit der Natur der Batch-Inferenz in der Architektur zusammen, die leicht unterschiedliche Ausgaben für dieselbe Eingabe erzeugen kann.
Herausforderungen bei Training und Spezialisierung
Auch wenn es keine direkte Endbenutzer-Sorge ist, bringt das Training von sparse MoE-Modellen eigene Herausforderungen mit sich. Die ordnungsgemäße Spezialisierung der Experten und die Verwaltung des Lastausgleichs sind kritische Schritte; wenn diese nicht berücksichtigt werden, können sie die Gesamtqualität und Zuverlässigkeit des Modells beeinträchtigen.
Komplexität der lokalen Bereitstellung
Die lokale Ausführung von Qwen3-Next-80B-A3B kann komplex sein. Sie erfordert oft aktuelle Bibliotheken, spezifische Hardwarekonfigurationen und die Fehlerbehebung von Problemen – wie Kompatibilitätsproblemen mit Frameworks wie vLLM unter bestimmten Auslagerungseinstellungen.
Fehlerbehebungstipps
Neustart oder Neuladen
Bei Problemen wie unerwartetem Verhalten oder Einfrieren der IDE versuchen Sie, das Fenster neu zu laden oder die Anwendung neu zu starten.
Benutzerdefinierte Modelle verwenden
Um Warteschlangen in den nativen Modellen von Trae zu umgehen, verbinden Sie ein benutzerdefiniertes Modell von Anbietern wie OpenRouter oder Alibaba Cloud.
Auf Updates prüfen
Stellen Sie sicher, dass Sie die neueste Version von Trae verwenden, da neue Versionen oft Fehler beheben und die Stabilität verbessern.
Hardwarebeschleunigung
Wenn Sie Fensterabsturzfehler oder grafische Störungen feststellen, kann das Deaktivieren der Hardwarebeschleunigung in den Einstellungen von Trae helfen.
Dokumentation und Community konsultieren
Bei Problemen mit benutzerdefinierten Modellen oder erweiterten Funktionen lesen Sie die offizielle Dokumentation von Trae. Community-Foren wie Reddit sind ebenfalls gute Quellen für benutzerorientierte Lösungen und Workarounds.
Für Qwen3-Next-Probleme
Bei der Bereitstellung oder Verwendung von Qwen3-Next über eine API befolgen Sie die empfohlenen Einstellungen für Sampling-Parameter und Kontextlänge aus der zugehörigen Dokumentation. Wenn Sie Speicherüberlauf-Fehler feststellen, kann eine Reduzierung der Kontextlänge das Problem beheben.
Die Kombination aus Qwen3-Next-80B-A3B und Trae schafft eine leistungsstarke Entwicklungsumgebung, die selbst mit viel größeren Modellen mithalten kann. Qwen3-Next bringt fortschrittliches Reasoning, Langzeit-Kontextverständnis und effiziente MoE-Leistung, während Trae eine agentengetriebene IDE liefert, die für Zusammenarbeit, Automatisierung und nahtlose Kontextintegration entwickelt wurde. Gemeinsam ermöglichen sie Entwicklern, massive Codebasen zu verwalten, komplexe Workflows zu beschleunigen und auf modernste KI-Unterstützung zuzugreifen – alles mit Flexibilität und Kosteneffizienz.
Häufig gestellte Fragen
Warum kann Qwen3-Next-80B-A3B mit einem 235B-Modell mithalten? Durch innovative Aufmerksamkeitsmechanismen, intelligentere Ressourcenzuweisung und sparse MoE-Effizienz liefert es eine Leistung, die mit größeren dichten Modellen vergleichbar ist, bei gleichzeitig schnellerer Inferenz und niedrigeren Kosten.
Warum sollte ich Trae als mein Code-Agent-Tool wählen? Trae bietet agentenbasierte Programmierung mit Builder-Modus und Chat-Modus, tiefes Kontextbewusstsein, multimodale Eingaben, Erweiterbarkeit mit Drittanbieter-Modellen sowie nahtlose VS Code- und GitHub-Integration – alles mit einem kostenlosen Einstieg.
Wie arbeiten Qwen3-Next-80B-A3B und Trae zusammen? Qwen3-Next erweitert Trae mit überlegenem Reasoning, Verständnis großer Codebasen, kosteneffizienter Leistung und starker Befolgung von Anweisungen. Dies ermöglicht es den Agenten von Trae, komplexe Codierungs- und Refactoring-Aufgaben autonom zu bewältigen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung von KI-Lösungen bietet.



