

Points clés
Contexte de 10 millions de tokens : Bien supérieur à la plupart des modèles.
Support multimodal : Gère à la fois le texte et les images en entrée.
Capacité multilingue : Prend en charge 12 langues, permettant des applications globales.
Open Source : Gratuit à utiliser et à personnaliser.
Profitez de la commodité de commencer votre essai gratuit avec l’API Novita AI dès aujourd’hui — rapide, simple et sans tracas !
Llama 4 Scout se distingue avec 10 millions de tokens de contexte, ce qui le différencie de la plupart des modèles d’IA aux fenêtres de contexte limitées. Cette capacité élevée le rend idéal pour gérer des tâches à grande échelle comme l’analyse de longs documents, la synthèse multilingue ou le traitement d’entrées multimodales.
Qu’est-ce que Llama 4 Scout ?
https://www.youtube.com/watch?v=MwHol73Cw\_I
Aperçu de Llama 4 Scout
| Propriété | Valeur |
|---|---|
| Date de sortie | 5 avril 2025 |
| Taille du modèle | 109 milliards de paramètres (17B actifs/token) |
| Open Source | Oui |
| Architecture | 16 Mixture-of-Experts (MoE) |
| Contexte | 10M (10000k) |
| Langues supportées | Arabe, Anglais, Français, Allemand, Hindi, Indonésien, Italien, Portugais, Espagnol, Tagalog, Thaï et Vietnamien |
| Multimodal | Entrée : Texte et image multilingues Sortie : Texte et code multilingues |
| Données d’entraînement | ~40 billions de tokens |
| Pré-entraînement | MetaP (Configuration adaptative des experts + entraînement intermédiaire) |
| Post-entraînement | SFT (Easy Data) → RL (Hard Data) → DPO |
| Type de tenseur | BF16 |
Benchmark de Llama 4 Scout
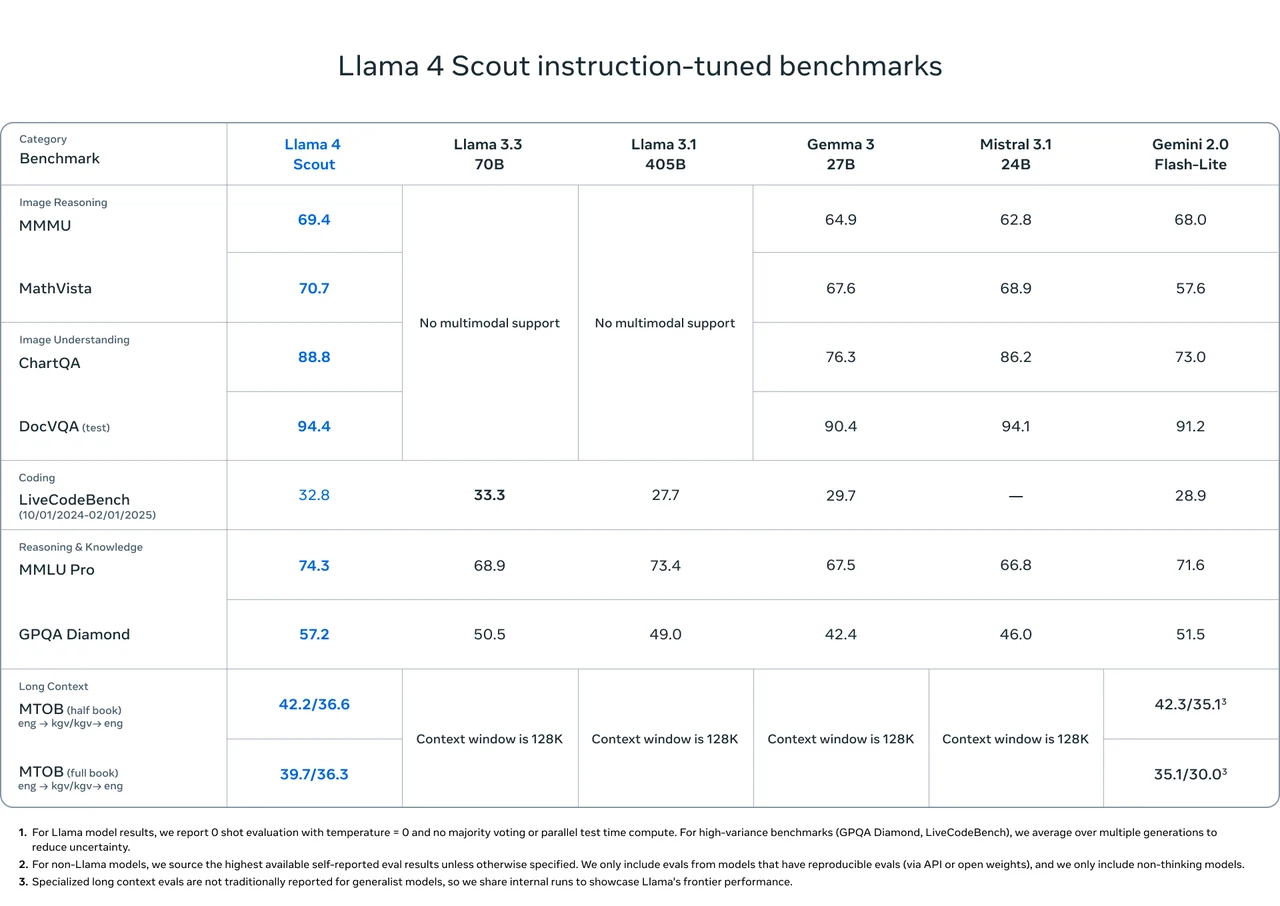
Source : Meta
Comment accéder à Llama 4 Scout localement ?
Configuration matérielle requise pour Llama 4 Scout
| Longueur du contexte | VRAM Int4 | GPU nécessaire (Int4) | VRAM FP16 | GPU nécessaire (FP16) |
|---|---|---|---|---|
| 4K tokens | ~99,5 Go / ~76,2 Go | 1xH100 | ~345 Go | 8×H100 |
| 128K tokens | ~334 Go | 8×H100 | ~579 Go | 8×H100 |
| 10M tokens | ~18,8 To (dominé par le cache KV) | 240×H100 | Identique à INT4 (dominance KV) | 240×H100 |
Bien que la promotion affirme que LLaMA 4 Scout peut fonctionner sur un seul H100, cela n’est possible qu’avec une quantification, des longueurs de contexte plus courtes, des tailles de lots réduites et un framework d’inférence efficace.
Installer Llama 4 Scout localement
Étape 1 : Préparer l’environnement
- Installer Python : Assurez-vous que votre système dispose d’une version appropriée de Python (requise pour Llama 4).
- Configurer le GPU : Vérifiez que votre système dispose d’un GPU puissant capable d’exécuter le modèle.
- Créer un environnement Python : Utilisez des outils comme
condaouvenvpour gérer les dépendances.
Étape 2 : Obtenir le modèle
- Visiter le site web : Rendez-vous sur www.llama.com.
- Sélectionner le modèle : Téléchargez Llama 4 Scout.
Étape 3 : Installer les dépendances
Exécutez la commande suivante pour installer les packages Python requis :
pip install llama-stack
Étape 4 : Vérifier le modèle
Listez tous les modèles disponibles et localisez l’ID du modèle pour Llama 4 Scout :
llama model list
Étape 5 : Télécharger et exécuter le modèle
- Spécifier l’ID du modèle : Saisissez l’ID du modèle correct et l’URL de téléchargement.
- Vérifier l’expiration de l’URL : Le lien de téléchargement est généralement valable seulement 48 heures ; vous devrez peut-être le retélécharger.
Une fois ces étapes terminées, vous serez prêt à exécuter Llama 4 Scout !
Comment accéder à Llama 4 Scout via l’API Novita ?
Étape 1 : Se connecter et accéder à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez Llama 4 Scout maintenant !
Étape 2 : Choisir votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencer votre essai gratuit
Débutez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenir votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Settings » , vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installer l’API
Installez l’API à l’aide du gestionnaire de packages spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Utiliser Llama 4 Scout via un GPU cloud
Étape 1 : Créer un compte
Si vous êtes nouveau sur Novita AI, commencez par créer un compte sur notre site web. Une fois inscrit, allez dans l’onglet « GPUs » pour explorer les ressources disponibles et commencer votre parcours.

Étape 2 : Explorer les templates et les serveurs GPU
Commencez par sélectionner un template qui correspond aux besoins de votre projet, comme PyTorch, TensorFlow ou CUDA. Choisissez la version qui convient à vos besoins, par exemple PyTorch 2.2.1 ou CUDA 11.8.0. Ensuite, sélectionnez la configuration de serveur GPU A100, qui offre des performances puissantes pour gérer des charges de travail exigeantes avec une VRAM, une RAM et une capacité de disque suffisantes.

Essayez les GPU haute performance de Novita AI
Étape 3 : Personnaliser votre déploiement
Après avoir sélectionné un template et un GPU, personnalisez vos paramètres de déploiement en ajustant des paramètres comme la version du système d’exploitation (par exemple, CUDA 11.8). Vous pouvez également modifier d’autres configurations pour adapter l’environnement aux exigences spécifiques de votre projet.

Étape 4 : Lancer une instance
Une fois que vous avez finalisé le template et les paramètres de déploiement, cliquez sur « Launch Instance » pour configurer votre instance GPU. Cela démarrera la configuration de l’environnement, vous permettant de commencer à utiliser les ressources GPU pour vos tâches d’IA.

La longueur de contexte inégalée de Llama 4 Scout et ses capacités multimodales en font un outil révolutionnaire pour les tâches longues, multilingues et à grande échelle. Son évolutivité et sa nature open source garantissent une flexibilité pour les développeurs et les chercheurs.
Questions fréquemment posées
Qu’est-ce qui rend Llama 4 Scout unique ?
Contexte de 10M tokens : Bien supérieur à la plupart des modèles.
Support multimodal : Gère à la fois le texte et les images en entrée.
Capacité multilingue : Prend en charge 12 langues, permettant des applications globales.
Open Source : Gratuit à utiliser et à personnaliser.
Puis-je utiliser Llama 4 Scout sans un GPU haut de gamme ?
Oui, mais seulement pour des contextes plus petits (par exemple, 4K tokens) en quantifiant le modèle. Les contextes complets de 10M tokens nécessitent au moins 240×H100 GPU en raison des besoins en mémoire, surtout pour le cache KV. Ou vous pouvez choisir Novita AI via l’API !
Quel matériel est recommandé pour Llama 4 Scout ?
Petits contextes (4K tokens) : 1×H100 GPU
Grands contextes (128K tokens) : 8×H100 GPU
Contextes complets (10M tokens) : 240×H100 GPU
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un GPU cloud fiable et abordable pour créer et passer à l’échelle.



