

Aspectos Destacados
Contexto de 10M tokens: Mucho mayor que la mayoría de los modelos.
Soporte multimodal: Maneja tanto texto como imágenes como entrada.
Capacidad multilingüe: Soporta 12 idiomas, permitiendo aplicaciones globales.
Código abierto: Gratuito de usar y personalizar.
Experimenta la conveniencia de comenzar tu prueba gratuita con la API de Novita AI hoy mismo: ¡rápido, fácil y sin complicaciones!
Llama 4 Scout se destaca por 10 millones de tokens de contexto, diferenciándose de la mayoría de los modelos de IA con ventanas de contexto limitadas. Esta alta capacidad lo hace ideal para manejar tareas a gran escala como análisis de documentos extensos, síntesis multilingüe o procesamiento de entrada multimodal.
¿Qué es Llama 4 Scout?
https://www.youtube.com/watch?v=MwHol73Cw\_I
Resumen de Llama 4 Scout
| Característica | Valor |
|---|---|
| Fecha de lanzamiento | 5 de abril de 2025 |
| Tamaño del modelo | 109B parámetros (17B activos/token) |
| Código abierto | Sí |
| Arquitectura | 16 Mezcla de Expertos (MoE) |
| Contexto | 10M (10000k) |
| Idiomas compatibles | Árabe, Inglés, Francés, Alemán, Hindi, Indonesio, Italiano, Portugués, Español, Tagalo, Tailandés y Vietnamita |
| Multimodal | Entrada: Texto e imagen multilingüe Salida: Texto y código multilingüe |
| Datos de entrenamiento | ~40 billones de tokens |
| Pre-entrenamiento | MetaP (Configuración adaptativa de expertos + entrenamiento intermedio) |
| Post-entrenamiento | SFT (Datos fáciles) → RL (Datos difíciles) → DPO |
| Tipo de tensor | BF16 |
Prueba de rendimiento de Llama 4 Scout
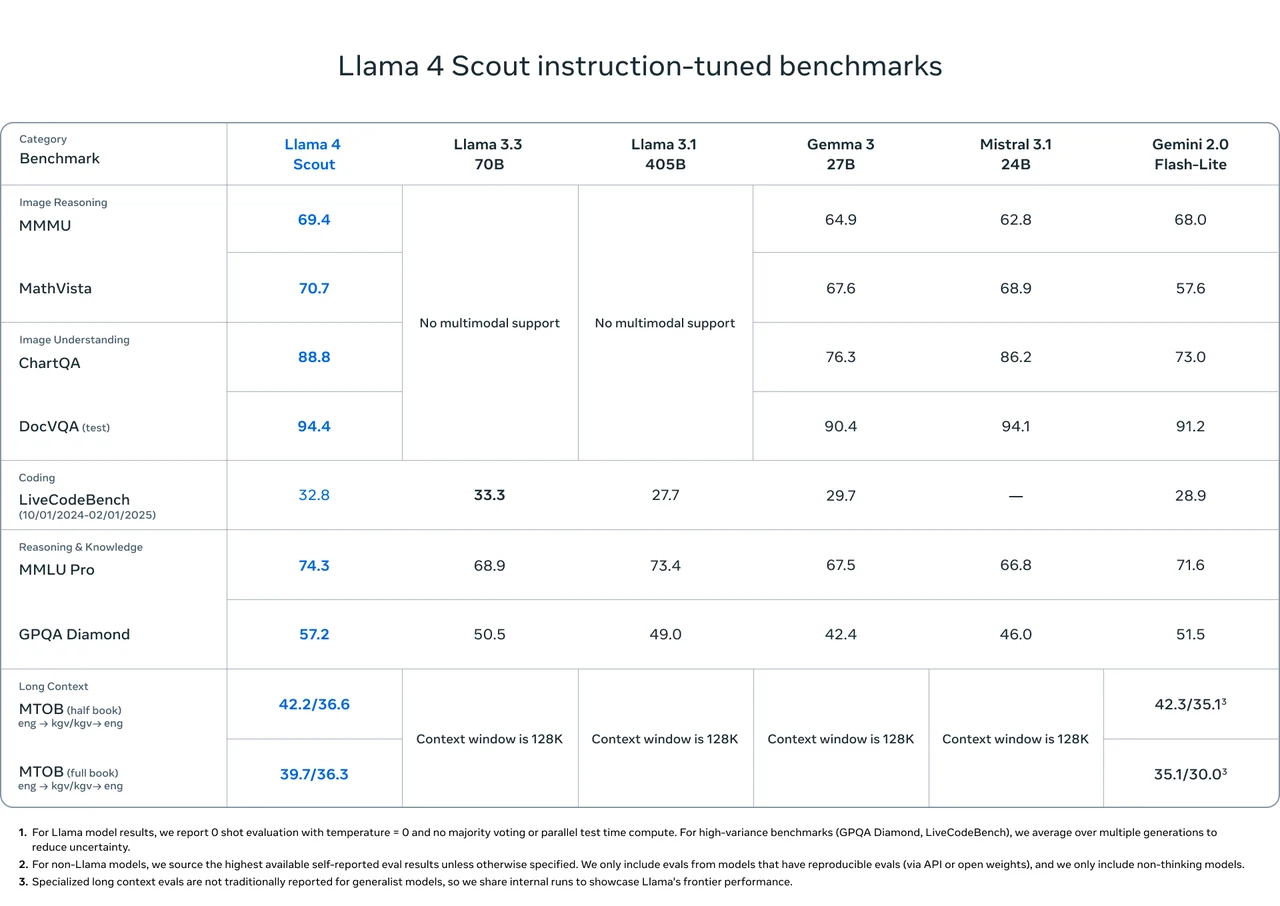
De Meta
¿Cómo acceder a Llama 4 Scout localmente?
Requisitos de hardware para Llama 4 Scout
| Longitud del contexto | VRAM Int4 | GPU necesaria (Int4) | VRAM FP16 | GPU necesaria (FP16) |
|---|---|---|---|---|
| 4K Tokens | ~99.5 GB / ~76.2 GB | 1xH100 | ~345 GB | 8×H100 |
| 128K Tokens | ~334 GB | 8×H100 | ~579 GB | 8×H100 |
| 10M Tokens | ~18.8 TB (dominado por KV Cache) | 240×H100 | Igual que INT4 (dominio de KV) | 240×H100 |
Aunque la promoción afirma que LLaMA 4 Scout puede ejecutarse en una sola H100, esto solo es factible con cuantización, longitudes de contexto más cortas, tamaños de lote más pequeños y un framework de inferencia eficiente.
Instalar Llama 4 Scout localmente
Paso 1: Preparar el entorno
- Instalar Python: Asegúrate de que tu sistema tenga una versión adecuada de Python instalada (requerida para Llama 4).
- Configurar GPU: Verifica que tu sistema tenga una GPU potente capaz de ejecutar el modelo.
- Crear entorno de Python: Usa herramientas como
condaovenvpara gestionar las dependencias.
Paso 2: Obtener el modelo
- Visitar el sitio web: Ve a www.llama.com.
- Seleccionar el modelo: Descarga Llama 4 Scout.
Paso 3: Instalar dependencias
Ejecuta el siguiente comando para instalar los paquetes de Python necesarios:
pip install llama-stack
Paso 4: Verificar el modelo
Lista todos los modelos disponibles y localiza el ID del modelo para Llama 4 Scout:
llama model list
Paso 5: Descargar y ejecutar el modelo
- Especificar el ID del modelo: Introduce el ID del modelo correcto y la URL de descarga.
- Verificar la expiración de la URL: El enlace de descarga suele ser válido solo por 48 horas; es posible que necesites volver a descargarlo.
Una vez completados estos pasos, ¡estarás listo para ejecutar Llama 4 Scout!
¿Cómo acceder a Llama 4 Scout mediante la API de Novita?
Paso 1: Iniciar sesión y acceder a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elegir tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comenzar tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtener tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresando a la página de “Settings” (Configuración), puedes copiar la clave API como se indica en la imagen.

Paso 5: Instalar la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Usar Llama 4 Scout mediante GPU en la nube
Paso 1: Registrar una cuenta
Si eres nuevo en Novita AI, comienza creando una cuenta en nuestro sitio web. Una vez registrado, dirígete a la pestaña “GPUs” para explorar los recursos disponibles y comenzar tu viaje.

Paso 2: Explorar plantillas y servidores GPU
Comienza seleccionando una plantilla que se ajuste a las necesidades de tu proyecto, como PyTorch, TensorFlow o CUDA. Elige la versión que se adapte a tus requisitos, como PyTorch 2.2.1 o CUDA 11.8.0. Luego, selecciona la configuración del servidor GPU A100, que ofrece un rendimiento potente para manejar cargas de trabajo exigentes con amplia VRAM, RAM y capacidad de disco.

Prueba las GPUs de alto rendimiento de Novita AI
Paso 3: Personalizar tu implementación
Después de seleccionar una plantilla y una GPU, personaliza la configuración de tu implementación ajustando parámetros como la versión del sistema operativo (por ejemplo, CUDA 11.8). También puedes modificar otras configuraciones para adaptar el entorno a los requisitos específicos de tu proyecto.

Paso 4: Lanzar una instancia
Una vez que hayas finalizado la plantilla y la configuración de implementación, haz clic en “Launch Instance” para configurar tu instancia de GPU. Esto iniciará la configuración del entorno, permitiéndote comenzar a usar los recursos de GPU para tus tareas de IA.

La longitud de contexto incomparable de Llama 4 Scout y sus capacidades multimodales lo convierten en una herramienta revolucionaria para tareas extensas, multilingües y a gran escala. Su escalabilidad y naturaleza de código abierto garantizan flexibilidad para desarrolladores e investigadores.
Preguntas frecuentes
¿Qué hace único a Llama 4 Scout?
Contexto de 10M tokens: Mucho mayor que la mayoría de los modelos.
Soporte multimodal: Maneja tanto texto como imágenes como entrada.
Capacidad multilingüe: Soporta 12 idiomas, permitiendo aplicaciones globales.
Código abierto: Gratuito de usar y personalizar.
¿Puedo usar Llama 4 Scout sin una GPU de alta gama?
Sí, pero solo para contextos más pequeños (por ejemplo, 4K tokens) mediante la cuantización del modelo. Los contextos completos de 10M tokens requieren al menos 240×H100 GPUs debido a las demandas de memoria, especialmente para la caché KV. O puedes elegir Novita AI mediante API.
¿Qué hardware se recomienda para Llama 4 Scout?
Contextos pequeños (4K tokens): 1 GPU H100
Contextos grandes (128K tokens): 8 GPUs H100
Contextos completos (10M tokens): 240 GPUs H100
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



