

Ключевые особенности
Контекст 10M токенов – значительно больше, чем у большинства моделей.
Мультимодальная поддержка – обрабатывает как текст, так и изображения на входе.
Многоязычность – поддерживает 12 языков, что позволяет использовать модель в глобальных приложениях.
Открытый исходный код – бесплатно для использования и кастомизации.
Попробуйте удобный бесплатный пробный период с помощью API Novita AI – быстро, просто и без лишних хлопот!
Llama 4 Scout выделяется контекстом в 10 миллионов токенов, что отличает её от большинства AI‑моделей с ограниченными окнами контекста. Такая высокая ёмкость делает её идеальной для масштабных задач: анализ длинных документов, многоязычный синтез или обработка мультимодальных входных данных.
Что такое Llama 4 Scout?
https://www.youtube.com/watch?v=MwHol73Cw\_I
Обзор Llama 4 Scout
| Свойство | Значение |
|---|---|
| Дата выпуска | 5 апреля 2025 г. |
| Размер модели | 109B параметров (17B активных на токен) |
| Открытый исходный код | open |
| Архитектура | 16 Mixture-of-Experts (MoE) |
| Контекст | 10M (10000k) |
| Поддерживаемые языки | арабский, английский, французский, немецкий, хинди, индонезийский, итальянский, португальский, испанский, тагальский, тайский и вьетнамский |
| Мультимодальность | Вход: многоязычный текст и изображение Выход: многоязычный текст и код |
| Обучающие данные | ~40 триллионов токенов |
| Предварительное обучение | MetaP (адаптивная конфигурация экспертов + промежуточное обучение) |
| Пост‑обучение | SFT (лёгкие данные) → RL (сложные данные) → DPO |
| Тип тензора | BF16 |
Бенчмарк Llama 4 Scout
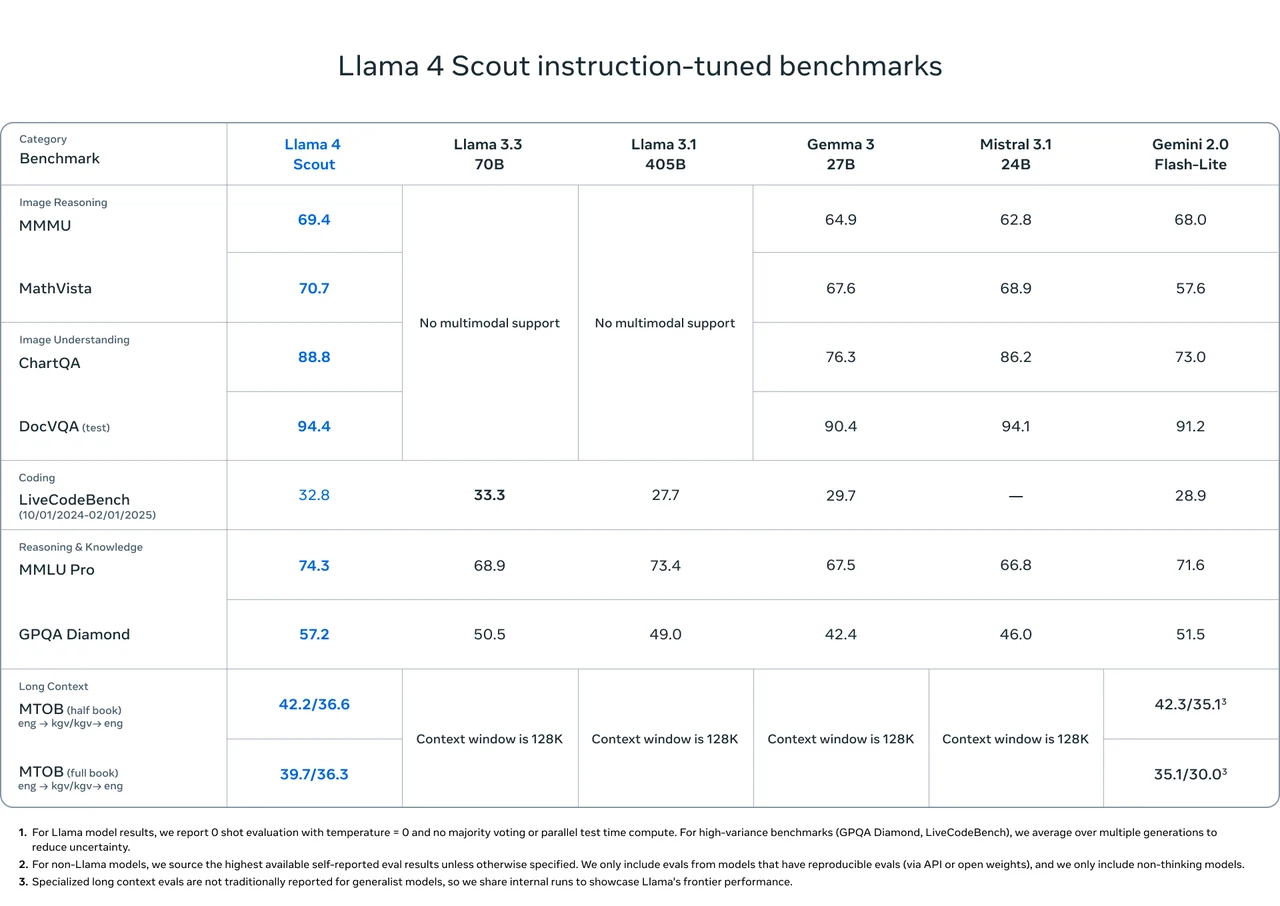
Источник: Meta
Как получить доступ к Llama 4 Scout локально?
Требования к оборудованию для Llama 4 Scout
| Длина контекста | VRAM (Int4) | Необходимые GPU (Int4) | VRAM (FP16) | Необходимые GPU (FP16) |
|---|---|---|---|---|
| 4K токенов | ~99,5 ГБ / ~76,2 ГБ | 1×H100 | ~345 ГБ | 8×H100 |
| 128K токено | ~334 ГБ | 8×H100 | ~579 ГБ | 8×H100 |
| 10M токенов | ~18,8 ТБ (в основном KV‑кэш) | 240×H100 | То же, что и INT4 (доминирует KV) | 240×H100 |
Хотя в рекламе утверждается, что LLaMA 4 Scout может работать на одном H100, это достижимо только при квантизации, коротких контекстах, малых размерах батча и эффективном фреймворке инференса.
Установка Llama 4 Scout локально
Шаг 1: Подготовка окружения
- Установите Python: убедитесь, что в системе установлена подходящая версия Python (необходима для Llama 4).
- Настройте GPU: проверьте, что в системе есть мощный GPU, способный запустить модель.
- Создайте Python‑окружение: используйте инструменты вроде
condaилиvenvдля управления зависимостями.
Шаг 2: Получение модели
- Перейдите на сайт: откройте www.llama.com.
- Выберите модель: скачайте Llama 4 Scout.
Шаг 3: Установка зависимостей
Выполните следующую команду для установки необходимых пакетов Python:
pip install llama-stack
Шаг 4: Проверка модели
Выведите список всех доступных моделей и найдите ID модели для Llama 4 Scout:
llama model list
Шаг 5: Скачивание и запуск модели
- Укажите ID модели: введите правильный ID модели и URL для скачивания.
- Проверьте срок действия ссылки: ссылка на скачивание обычно действительна только 48 часов; возможно, потребуется повторное скачивание.
После выполнения этих шагов вы будете готовы запустить Llama 4 Scout!
Как получить доступ к Llama 4 Scout через Novita API?
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Model Library (Библиотека моделей).

Попробовать Llama 4 Scout сейчас!
Шаг 2: Выберите модель
Просмотрите доступные варианты и выберите подходящую модель.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API‑ключ
Для аутентификации при работе с API мы предоставим вам новый API‑ключ. Перейдите на страницу «Settings» (Настройки) и скопируйте API‑ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.

После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API‑ключом, чтобы начать взаимодействие с Novita AI LLM. Ниже приведён пример использования chat completions API для Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Использование Llama 4 Scout через облачный GPU
Шаг 1: Зарегистрируйтесь
Если вы новичок в Novita AI, начните с создания аккаунта на нашем сайте. После регистрации перейдите на вкладку «GPUs», чтобы изучить доступные ресурсы и начать работу.

Шаг 2: Выберите шаблон и GPU‑сервер
Начните с выбора шаблона, соответствующего вашему проекту — например, PyTorch, TensorFlow или CUDA. Выберите подходящую версию, например PyTorch 2.2.1 или CUDA 11.8.0. Затем выберите конфигурацию GPU‑сервера A100, которая обеспечивает высокую производительность для ресурсоёмких задач с достаточным объёмом VRAM, RAM и дискового пространства.

Попробовать высокопроизводительные GPU Novita AI
Шаг 3: Настройте развёртывание
После выбора шаблона и GPU настройте параметры развёртывания: измените версию операционной системы (например, CUDA 11.8). Вы также можете настроить другие параметры, чтобы адаптировать окружение под конкретные требования вашего проекта.

Шаг 4: Запустите инстанс
Когда шаблон и параметры развёртывания готовы, нажмите «Launch Instance», чтобы запустить GPU‑инстанс. Это начнёт подготовку окружения, после чего вы сможете использовать ресурсы GPU для своих AI‑задач.

Беспрецедентная длина контекста и мультимодальные возможности Llama 4 Scout делают её революционным инструментом для длинных, многоязычных и масштабных задач. Масштабируемость и открытый исходный код обеспечивают гибкость для разработчиков и исследователей.
Часто задаваемые вопросы
Что делает Llama 4 Scout уникальной?
Контекст 10M токенов – значительно больше, чем у большинства моделей.
Мультимодальная поддержка – обрабатывает как текст, так и изображения на входе.
Многоязычность – поддерживает 12 языков, что позволяет использовать модель в глобальных приложениях.
Открытый исходный код – бесплатно для использования и кастомизации.
Могу ли я использовать Llama 4 Scout без дорогого GPU?
Да, но только для небольших контекстов (например, 4K токенов) при квантизации модели. Полный контекст в 10M токенов требует не менее 240×H100 GPU из‑за требований к памяти, особенно для KV‑кэша. Или вы можете выбрать Novita AI через API!
Какое оборудование рекомендуется для Llama 4 Scout?
Небольшие контексты (4K токенов): 1×H100 GPU
Большие контексты (128K токенов): 8×H100 GPU
Полный контекст (10M токенов): 240×H100 GPU
Novita AI — это облачная платформа AI, которая предоставляет разработчикам простой способ развёртывания AI‑моделей через наш простой API, а также доступный и надёжный облачный GPU для создания и масштабирования проектов.



