

主なハイライト
10Mトークンのコンテキスト: ほとんどのモデルを大きく上回ります。
マルチモーダル対応: テキストと画像の両方を入力として処理します。
多言語対応: 12言語に対応し、グローバルなアプリケーションを実現します。
オープンソース: 無料で使用・カスタマイズ可能。
Novita AI のAPIで 無料トライアル を開始して、迅速・簡単・手間いらずの利便性を体験してください。
Llama 4 Scout は 1000万トークンのコンテキスト を誇り、限られたコンテキストウィンドウを持つほとんどのAIモデルとは一線を画します。この高い容量により、長文書分析、多言語合成、マルチモーダル入力処理などの大規模タスクに最適です。
Llama 4 Scout とは?
https://www.youtube.com/watch?v=MwHol73Cw\_I
Llama 4 Scout の概要
| **プロパティ ** | ** 値** |
|---|---|
| リリース日 | 2025年4月5日 |
| モデルサイズ | 109Bパラメータ(アクティブ17B/トークン) |
| オープンソース | オープン |
| アーキテクチャ | 16 Mixture-of-Experts(MoE) |
| コンテキスト | 10M(10000k) |
| 対応言語 | アラビア語、英語、フランス語、ドイツ語、ヒンディー語、インドネシア語、イタリア語、ポルトガル語、スペイン語、タガログ語、タイ語、ベトナム語 |
| マルチモーダル | 入力: 多言語テキストと画像 出力: 多言語テキストとコード |
| 学習データ | 約40兆トークン |
| 事前学習 | MetaP(アダプティブエキスパート構成+中間学習) |
| 事後学習 | SFT(Easy Data)→ RL(Hard Data)→ DPO |
| テンソルタイプ | BF16 |
Llama 4 Scout ベンチマーク
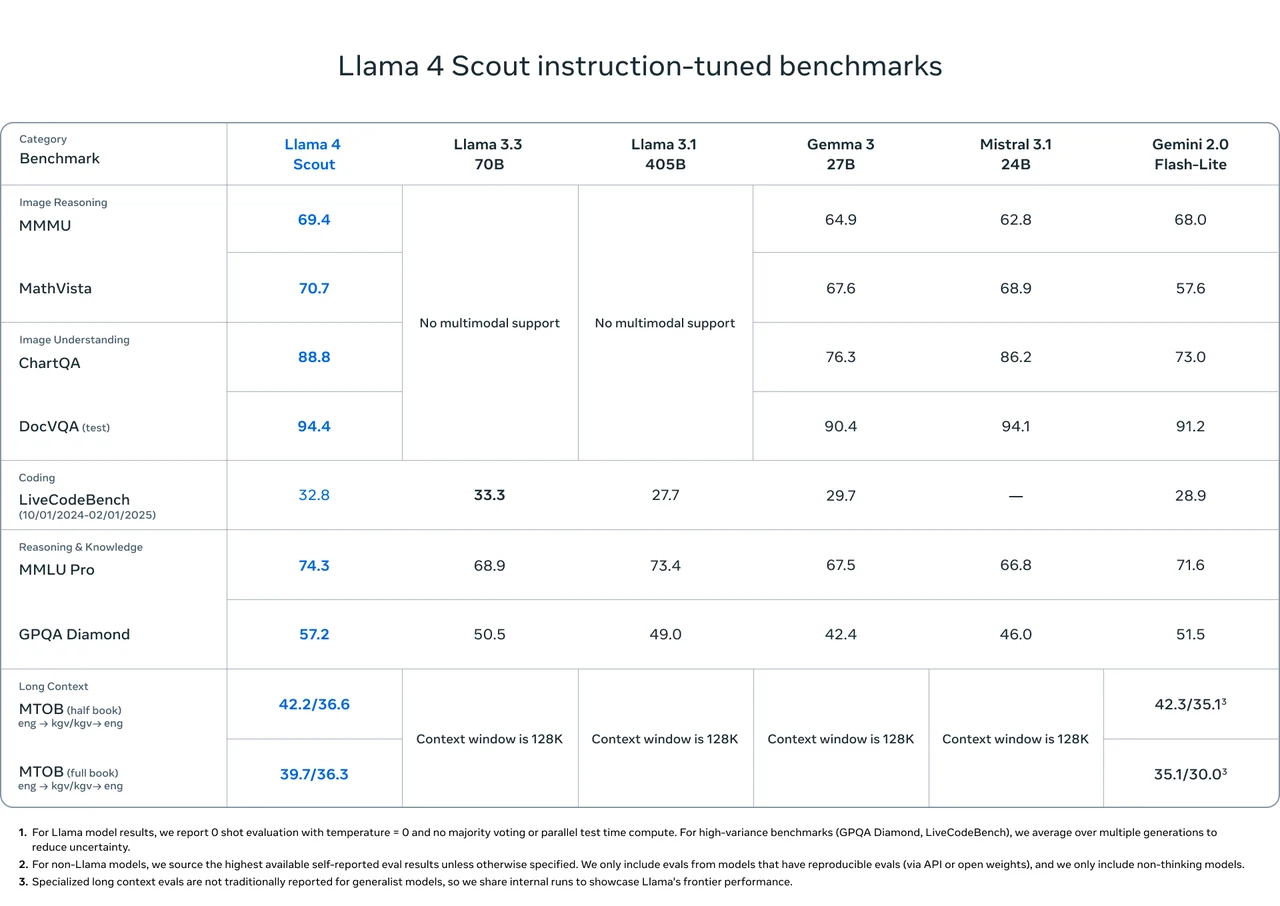
Meta より
ローカルで Llama 4 Scout にアクセスする方法
Llama 4 Scout のハードウェア要件
| **コンテキスト長 ** | Int4 VRAM | ** 必要なGPU(Int4)** | FP16 VRAM | ** 必要なGPU(FP16)** |
|---|---|---|---|---|
| 4Kトークン | ~99.5 GB / ~76.2 GB | 1×H100 | ~345 GB | 8×H100 |
| 128Kトークン | ~334 GB | 8×H100 | ~579 GB | 8×H100 |
| 10Mトークン | ~18.8 TB(KVキャッシュが大部分) | 240×H100 | Int4と同じ(KVキャッシュが支配的) | 240×H100 |
プロモーションではLLaMA 4 Scoutが単一のH100で実行可能とされていますが、これは量子化、短いコンテキスト長、小さいバッチサイズ、効率的な推論フレームワークを使用した場合に限ります。
Llama 4 Scout をローカルにインストールする
ステップ1: 環境を準備する
- Pythonのインストール: システムに適切なバージョンのPythonがインストールされていることを確認してください(Llama 4に必要)。
- GPUのセットアップ: モデルを実行できる強力なGPUがシステムにあることを確認してください。
- Python環境の作成:
condaやvenvなどのツールを使用して依存関係を管理します。
ステップ2: モデルを入手する
- ウェブサイトにアクセス: www.llama.com にアクセスします。
- **モデルを選択 **: Llama 4 Scout をダウンロードします。
ステップ3: 依存関係をインストールする
以下のコマンドを実行して、必要なPythonパッケージをインストールします。
pip install llama-stack
ステップ4: モデルを確認する
利用可能なすべてのモデルを一覧表示し、Llama 4 Scout のモデルIDを見つけます。
llama model list
ステップ5: モデルをダウンロードして実行する
- モデルIDを指定: 正しいモデルIDとダウンロードURLを入力します。
- URLの有効期限を確認: ダウンロードリンクは通常48時間のみ有効です。再ダウンロードが必要になる場合があります。
これらの手順が完了すると、Llama 4 Scout を実行する準備が整います!
Novita API 経由で Llama 4 Scout にアクセスする方法
ステップ1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ2: モデルを選択
利用可能なオプションからニーズに合ったモデルを選択します。

ステップ3: 無料トライアルを開始
選択したモデルの機能を試すために無料トライアルを開始します。
ステップ4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「Settings」ページに移動し、画像のようにAPIキーをコピーします。

ステップ5: APIをインストール
プログラミング言語に応じたパッケージマネージャーを使用してAPIをインストールします。

インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-scout-17b-16e-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
クラウドGPU経由でLlama 4 Scoutを使用する
ステップ1:アカウント登録
Novita AIが初めての方は、まずウェブサイトでアカウントを作成してください。登録後、「GPUs」タブに移動して利用可能なリソースを確認し、旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの確認
まず、プロジェクトのニーズに合ったテンプレート(PyTorch、TensorFlow、CUDAなど)を選択します。必要なバージョン(例:PyTorch 2.2.1、CUDA 11.8.0)を選びます。次に、A100 GPUサーバー構成を選択します。これは、十分なVRAM、RAM、ディスク容量で要求の厳しいワークロードに対応する強力なパフォーマンスを提供します。

ステップ3:デプロイメントをカスタマイズ
テンプレートとGPUを選択した後、オペレーティングシステムのバージョン(例:CUDA 11.8)などのパラメータを調整してデプロイメント設定をカスタマイズします。プロジェクトの特定の要件に合わせて環境を調整するために、他の設定も調整できます。

ステップ4:インスタンスを起動
テンプレートとデプロイメント設定を確定したら、「Launch Instance」をクリックしてGPUインスタンスをセットアップします。これにより環境のセットアップが開始され、AIタスクにGPUリソースを使い始めることができます。

Llama 4 Scoutの 比類のないコンテキスト長 とマルチモーダル機能は、長文、多言語、大規模タスクにおいて革新的なツールです。そのスケーラビリティとオープンソースの性質により、開発者や研究者に柔軟性を提供します。
よくある質問
Llama 4 Scoutの特長は何ですか?
10Mトークンのコンテキスト: ほとんどのモデルを大きく上回ります。
マルチモーダル対応: テキストと画像の両方を入力として処理します。
多言語対応: 12言語に対応し、グローバルなアプリケーションを実現します。
オープンソース: 無料で使用・カスタマイズ可能。
ハイエンドGPUなしでLlama 4 Scoutを使用できますか?
はい。ただし、モデルを量子化して小さいコンテキスト(例:4Kトークン)でのみ可能です。フル10Mトークンのコンテキストには、特にKVキャッシュのメモリ需要から、少なくとも 240×H100 GPU が必要です。または、API経由でNovita AIを選択することもできます!
Llama 4 Scoutにはどのようなハードウェアが推奨されますか?
小規模コンテキスト(4Kトークン): 1×H100 GPU
大規模コンテキスト(128Kトークン): 8×H100 GPU
フルコンテキスト(10Mトークン): 240×H100 GPU
Novita AIは、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に手頃な価格で信頼性の高いGPUクラウドを提供し、構築とスケーリングを支援します。



