

Les développeurs souhaitant exploiter GLM-5 se heurtent souvent à une incertitude importante quant au choix de la méthode d’accès la plus pratique. Doté de capacités de codage et de raisonnement agentiques de pointe avec 754 milliards de paramètres, GLM-5 peut gérer des tâches de codage complexes, multi-étapes, et la prise en compte de projets multi-fichiers. Pourtant, les options vont de l’API officielle Z.AI et des abonnements de codage, aux fournisseurs tiers comme Novita AI, jusqu’au déploiement local qui nécessite un matériel prohibitif. Cet article répond aux points de douleur principaux des développeurs : rapport coût-efficacité, complexité d’intégration, latence et faisabilité matérielle. Nous allons décomposer l’accès à GLM-5 selon trois perspectives : API officielle vs abonnement de codage, fournisseurs tiers compatibles OpenAI, et réalités du déploiement local, en fournissant des conseils actionnables pour choisir la configuration optimale.
Qu’est-ce que GLM-5 ?
GLM-5 est un modèle mixture-of-experts (MoE) de Z.AI comptant 754 milliards de paramètres, avec 40 milliards de paramètres actifs par passage avant, ciblant l’ingénierie système complexe et les tâches agentiques à long horizon. Passant des 355 milliards de paramètres et 23 billions de tokens d’entraînement de GLM-4.5 à 28,5 billions de tokens grâce à l’attention éparse DeepSeek (DSA), il atteint une fenêtre de contexte de 200K tokens avec un coût de déploiement réduit. L’architecture MoE achemine chaque token à travers 8 des 256 experts plus 1 expert partagé, ce qui donne une latence du premier token proche de celle d’un modèle dense de 30 à 70 milliards de paramètres, malgré les 754 milliards de paramètres totaux.
Source : Huggingface
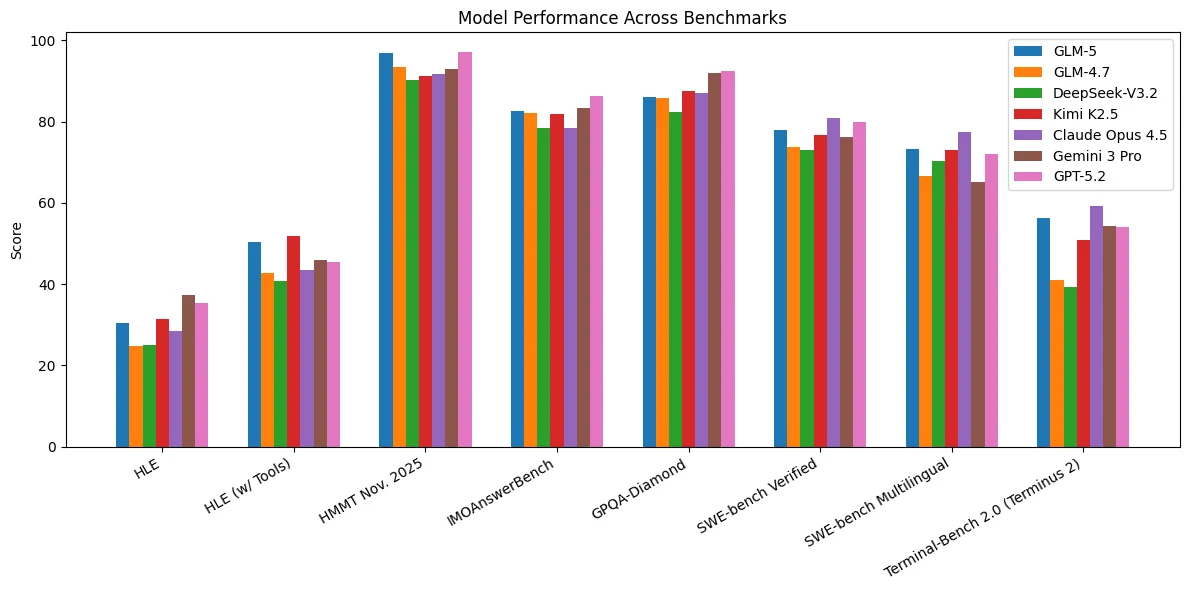
GLM-5 affiche des performances constamment solides sur une large gamme de benchmarks couvrant le raisonnement, le codage et les tâches orientées agent. Il se classe parmi les meilleurs modèles sur HLE, HLE (avec outils) et HMMT Nov. 2025, ce qui témoigne d’un solide raisonnement analytique et d’une résolution de problèmes augmentée par des outils efficace.
Essayez GLM-5 dès maintenant !
1. Accès API officiel (Z.ai)
Z.AI propose l’API officielle de GLM-5 via sa plateforme.
Étapes de configuration
- Créez un compte sur Z.ai et accédez aux paramètres de l’API
- Générez une clé API depuis le tableau de bord développeur
- Installez le client compatible OpenAI :
pip install openai
Exemple de code
from openai import OpenAI
client = OpenAI(
api_key="votre-clé-api-Z.AI",
base_url="https://api.z.ai/api/paas/v4/",
)
completion = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "You are a smart and creative novelist"},
{
"role": "user",
"content": "Please write a short fairy tale story as a fairy tale master",
},
],
)
print(completion.choices[0].message.content)
Tarification
Les tarifs de Z.ai sont regroupés via des abonnements. L’abonnement Codage à 10 $/mois donne accès à GLM-5 via leur interface OpenClaw, adapté aux développeurs individuels et aux petites équipes.
| Caractéristique | Z.AI API | Z.AI Coding Plan |
|---|---|---|
| Objectif | Accès général au modèle via API REST | Forfait d’abonnement axé sur les cas d’usage de codage/assistant de code |
| Modèle de facturation | Paiement à l’usage (tokens/appels) | Abonnement mensuel avec limites de quota |
| Portée d’utilisation | Peut être utilisé pour toute application (chat, génération de texte, raisonnement) | Fonctionne uniquement dans les outils/IDE de codage pris en charge (ex: Cline, Claude Code, OpenCode, etc.) |
| Point d’accès | Point d’accès API général (/api/paas/v4) (Z.ai) |
Point d’accès dédié au codage (/api/coding/paas/v4) |
| Quota | Facturé par demande/token sans quota de prompt fixe | Quotas de prompts fixes par fenêtre temporelle (ex: par cycle de 5 heures) selon le niveau d’abonnement |
| Prévisibilité des coûts | Vous payez exactement pour l’usage, les coûts peuvent fluctuer | Coût mensuel fixe avec des limites de quota prévisibles |
| Intégration | Appelé directement depuis vos propres applications/services via SDK/REST | Intégré uniquement dans les environnements/outils de codage compatibles |
| Idéal pour | Besoins IA généraux (chatbots, assistants, workflows) | Tâches de codage à haute fréquence : génération de code, complétion, débogage |
2. Fournisseurs d’API tiers
Plusieurs fournisseurs proposent GLM-5 via des API compatibles OpenAI. Sur la base des benchmarks des fournisseurs d’inférence HuggingFace, voici comment ils se comparent :

Novita AI (Le plus abordable pour les développeurs)
Novita AI propose des tarifs compétitifs de 1,00 $ / 3,20 $ par million de tokens d’entrée/sortie, avec une fenêtre de contexte de 202 800 tokens et un temps jusqu’au premier token de 1,09 seconde. L’API compatible OpenAI élimine les efforts d’intégration.
Pourquoi choisir Novita AI
- Remplacement plug-and-play d’OpenAI : Aucune modification de code nécessaire si vous migrez depuis le SDK OpenAI
- Tarifs transparents : Pas de frais cachés ni de limites de débit sur les forfaits standard
- Prise en charge de l’appel de fonctions : Intégration native d’outils pour les workflows agentiques
- Catalogue de modèles étendu : Accédez à plus de 100 modèles via une API unifiée
Étapes de configuration
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle adapté à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez GLM-5 dès maintenant !
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Votre clé API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Connectez facilement Novita AI à des plateformes partenaires comme Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow et OpenClaw grâce à des intégrations API et des guides de configuration étape par étape.
3. Vérification des réalités du déploiement local
Le déploiement local de GLM-5 se heurte à des barrières matérielles importantes. Le modèle nécessite 1508 Go de VRAM en précision BF16, ce qui descend à 241 Go avec la quantification UD-IQ2_XXS. Même la quantification la plus agressive dépasse la capacité de tout GPU grand public ou prosumer individuel.
Exigences en VRAM par quantification
| Quantification | VRAM requise | Configuration GPU |
|---|---|---|
| BF16 (complète) | 1508 Go | 19×H100 80Go |
| Q8_0 | 801 Go | 11×H100 80Go |
| Q6_K | 619 Go | 8×H100 80Go |
| Q4_K_M | 456 Go | 6×H100 80Go |
| Q3_K_M | 360 Go | 5×H100 80Go |
| Q2_K | 276 Go | 4×H100 80Go |
| UD-IQ2_XXS | 241 Go | 3×H100 80Go |
Bien que cette tâche nécessite un grand nombre de GPUs, vous pouvez essayer de l’exécuter en utilisant les ressources GPU stables et rentables fournies par Novita. Novita prend également en charge le déploiement parallèle sur 8 GPUs, ce qui répond aux charges de travail nécessitant une puissance de calcul plus élevée.
Essayez des GPU rentables dès maintenant !
GLM-5 offre des performances inégalées en codage agentique et en raisonnement, mais la stratégie d’accès est critique. Pour la plupart des développeurs, l’API Novita AI offre la voie la plus rapide et la plus rentable grâce à une intégration compatible OpenAI, tandis que l’abonnement Codage officiel de Z.AI convient aux petites équipes recherchant des quotas mensuels prévisibles. Le déploiement local reste impraticable pour la plupart en raison des exigences extrêmes en VRAM. Comprendre ces compromis permet aux développeurs d’exploiter GLM-5 efficacement sans sur-allouer de ressources.
Foire aux questions
Qu’est-ce que GLM-5, et qu’est-ce qui le rend adapté aux tâches de codage ?
GLM-5 est un modèle mixture-of-experts de Z.AI comptant 754 milliards de paramètres, avec 40 milliards de paramètres actifs par passage. Il excelle dans la planification de code autonome, la prise en compte du contexte multi-fichiers et la décomposition de demandes complexes en étapes exécutables, ce qui le rend idéal pour les tâches de codage à long horizon.
Quels sont les avantages de l’utilisation de l’abonnement Codage Z.AI pour GLM-5 ?
L’abonnement Codage Z.AI propose un forfait avec des quotas de prompts fixes et un point d’accès dédié au codage. Il est optimisé pour les tâches de codage à haute fréquence telles que la génération de code, la complétion et le débogage dans les IDE pris en charge comme OpenCode ou Cline.
Le déploiement local de GLM-5 est-il réalisable pour la plupart des équipes ?
Le déploiement local de GLM-5 nécessite une VRAM massive (jusqu’à 1508 Go en BF16), ce qui le rend impraticable pour presque toutes les configurations individuelles ou de petites équipes. Même une quantification agressive nécessite des centaines de gigaoctets de VRAM, limitant l’accessibilité.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle vos projets.
Lectures recommandées



