

Los desarrolladores que buscan aprovechar GLM-5 a menudo se enfrentan a una gran incertidumbre al elegir el método de acceso más práctico. Con capacidades de codificación y razonamiento agéntico de vanguardia y 754B parámetros, GLM-5 puede manejar tareas complejas de codificación en múltiples pasos y tener conciencia de proyectos de múltiples archivos. Sin embargo, las opciones van desde la API oficial de Z.AI y los planes de suscripción de codificación, pasando por proveedores externos como Novita AI, hasta el despliegue local que requiere hardware prohibitivamente caro. Este artículo aborda los puntos débiles principales de los desarrolladores: rentabilidad, complejidad de integración, latencia y viabilidad del hardware. Analizaremos el acceso a GLM-5 desde tres perspectivas: API oficial vs. plan de codificación, proveedores externos compatibles con OpenAI y la realidad del despliegue local, proporcionando una guía práctica para elegir la configuración óptima.
¿Qué es GLM-5?
GLM-5 es el modelo de mezcla de expertos de 754B parámetros de Z.AI, con 40B parámetros activos por paso hacia adelante, orientado a la ingeniería de sistemas complejos y tareas agénticas de largo alcance. Escalando desde los 355B parámetros y 23T tokens de entrenamiento de GLM-4.5 hasta 28.5T tokens con DeepSeek Sparse Attention (DSA), logra una ventana de contexto de 200K con un costo de despliegue reducido. La arquitectura MoE enruta cada token a través de 8 de 256 expertos más 1 experto compartido, lo que proporciona una latencia del primer token más cercana a un modelo denso de 30-70B a pesar de tener 754B parámetros totales.
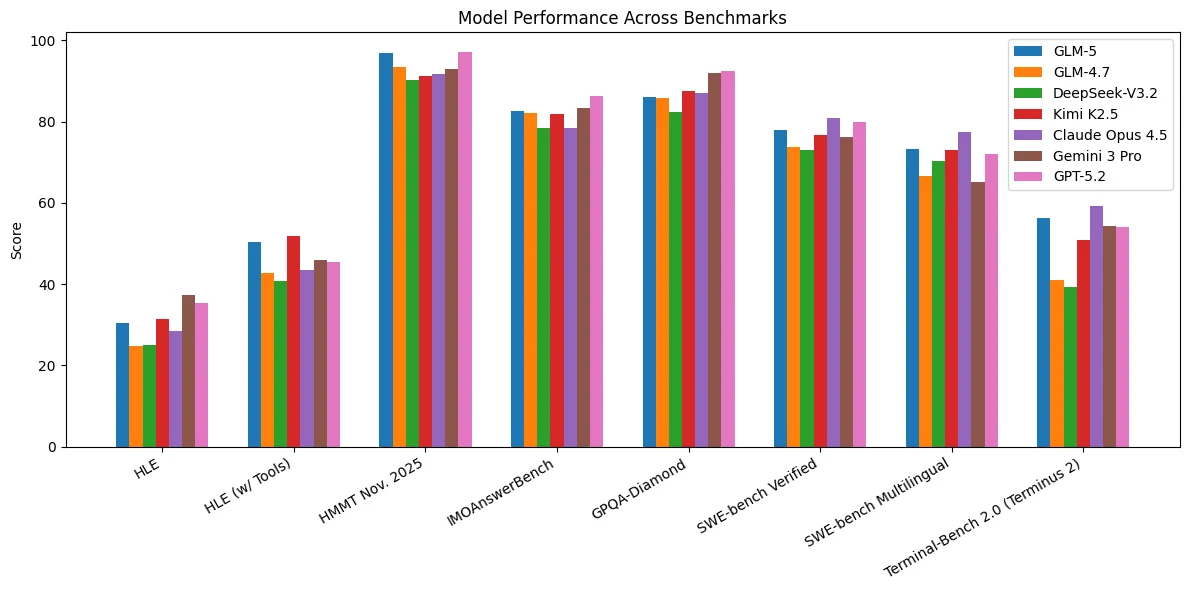
De Huggingface
GLM-5 muestra un rendimiento consistentemente sólido en una amplia gama de pruebas que cubren razonamiento, codificación y tareas orientadas a agentes. Se ubica entre los mejores modelos en HLE, HLE (con herramientas) y HMMT Nov. 2025, lo que indica un razonamiento analítico sólido y una resolución de problemas eficaz aumentada con herramientas.
1. Acceso Oficial a la API (Z.ai)
Z.AI ofrece la API oficial de GLM-5 a través de su plataforma.
Pasos de Configuración
- Crea una cuenta en Z.ai y navega a la configuración de la API
- Genera una clave de API desde el panel de desarrollador
- Instala el cliente compatible con OpenAI:
pip install openai
Ejemplo de Código
from openai import OpenAI
client = OpenAI(
api_key="tu-clave-API-Z.AI",
base_url="https://api.z.ai/api/paas/v4/",
)
completion = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Eres un novelista inteligente y creativo"},
{
"role": "user",
"content": "Por favor, escribe un cuento de hadas corto como un maestro de cuentos de hadas",
},
],
)
print(completion.choices[0].message.content)
Precios
Los precios de Z.ai se agrupan en planes de suscripción. El plan de codificación de $10/mes proporciona acceso a GLM-5 a través de su interfaz OpenClaw, adecuado para desarrolladores individuales y equipos pequeños.
| Aspecto | API de Z.AI | Plan de Codificación de Z.AI |
|---|---|---|
| Propósito | Acceso al modelo de propósito general a través de REST API | Paquete de suscripción centrado en casos de uso de codificación/asistente de código |
| Modelo de Facturación | Pago por uso (tokens/llamadas) | Suscripción mensual con límites de cuota |
| Alcance de Uso | Se puede usar para cualquier aplicación (chat, generación de texto, razonamiento) | Solo funciona dentro de herramientas/IDEs de codificación compatibles (ej. Cline, Claude Code, OpenCode, etc.) |
| Endpoint | Endpoint de API general (/api/paas/v4) (Z.ai) |
Endpoint de codificación dedicado (/api/coding/paas/v4) |
| Cuota | Se factura por solicitud/token sin cuota fija de solicitudes | Cuotas fijas de solicitudes por ventana de tiempo (ej. cada 5 horas) según el nivel del plan |
| Predectibilidad de Costos | Pagas exactamente por el uso, puede fluctuar | Costo mensual fijo con límites de cuota predecibles |
| Integración | Se llama directamente desde tus propias aplicaciones/servicios mediante SDK/REST | Se integra solo en entornos/herramientas de codificación compatibles |
| Mejor Para | Necesidades generales de IA (chatbots, asistentes, flujos de trabajo) | Tareas de codificación de alta frecuencia: generación, finalización y depuración de código |
2. Proveedores de API de Terceros
Múltiples proveedores ofrecen GLM-5 a través de APIs compatibles con OpenAI. Basándose en las pruebas de proveedores de inferencia de HuggingFace, así se comparan:

Novita AI (El Más Asequible para Desarrolladores)
Novita AI ofrece precios competitivos a $1.00/$3.20 por 1M de tokens de entrada/salida con una ventana de contexto de 202,800 y un tiempo hasta el primer token de 1.09s. La API compatible con OpenAI elimina el esfuerzo de integración.
Por Qué Novita AI
- Reemplazo directo de OpenAI: Sin cambios de código si migras desde el SDK de OpenAI
- Precios transparentes: Sin tarifas ocultas ni límites de tasa en planes estándar
- Soporte para llamadas de funciones: Integración nativa de herramientas para flujos de trabajo agénticos
- Catálogo amplio de modelos: Accede a más de 100 modelos a través de una API unificada
Pasos de Configuración
Paso 1: Inicia Sesión y Accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

Paso 2: Elige tu Modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu Prueba Gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu Clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página de Configuración y copia la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave de API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Conecta fácilmente Novita AI con plataformas asociadas como Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow, y OpenClaw mediante integraciones de API y guías de configuración paso a paso.
3. Verificación de la Realidad del Despliegue Local
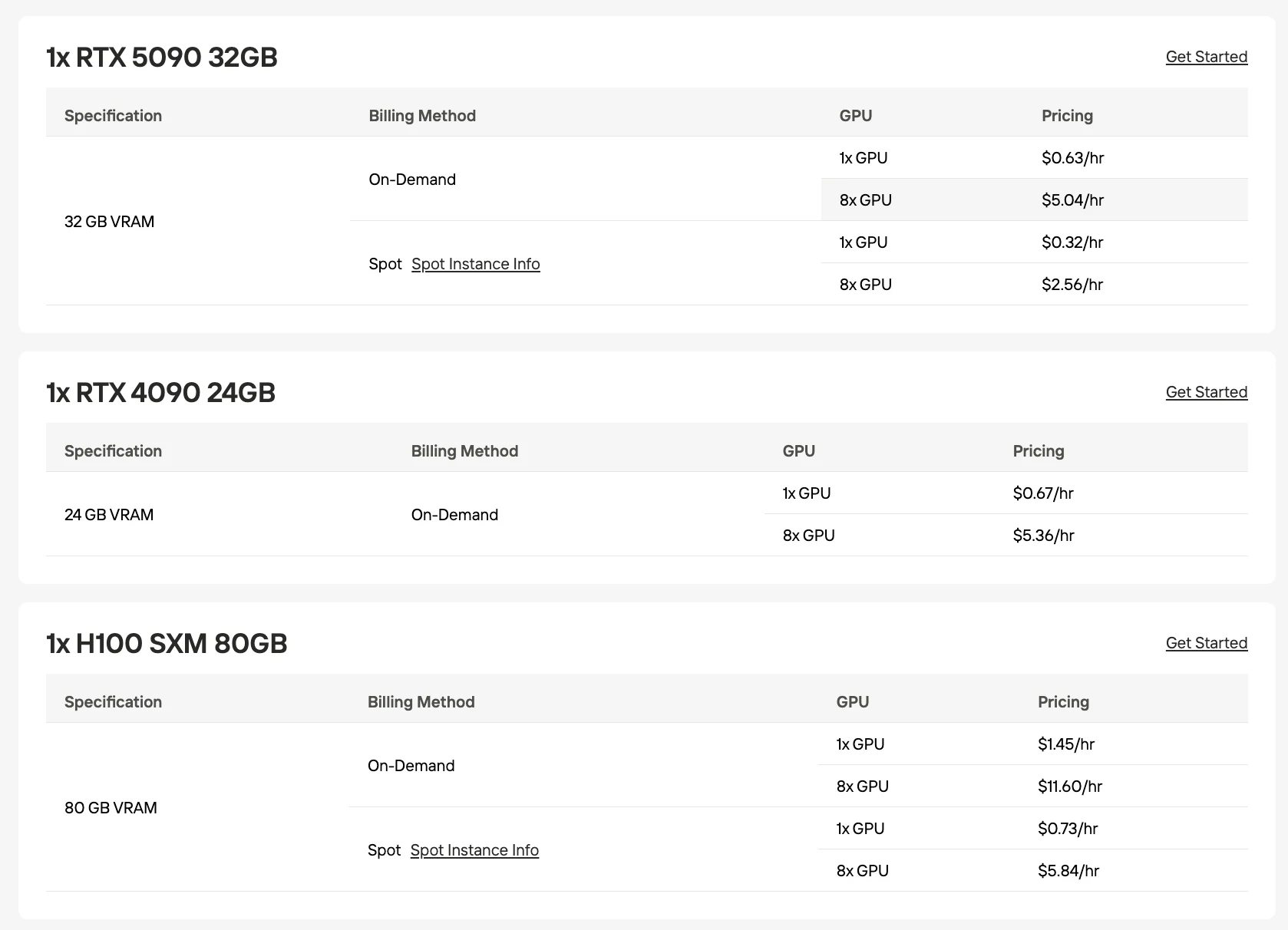
El despliegue local de GLM-5 enfrenta barreras de hardware significativas. El modelo requiere 1508 GB de VRAM en precisión BF16, reduciéndose a 241 GB con cuantización UD-IQ2_XXS. Incluso la cuantización más agresiva supera cualquier GPU de consumo o prosumidor individual.
Requisitos de VRAM por Cuantización
| Cuantización | VRAM Requerida | Configuración de GPU |
|---|---|---|
| BF16 (completo) | 1508 GB | 19×H100 80GB |
| Q8_0 | 801 GB | 11×H100 80GB |
| Q6_K | 619 GB | 8×H100 80GB |
| Q4_K_M | 456 GB | 6×H100 80GB |
| Q3_K_M | 360 GB | 5×H100 80GB |
| Q2_K | 276 GB | 4×H100 80GB |
| UD-IQ2_XXS | 241 GB | 3×H100 80GB |
Aunque la tarea requiere una gran cantidad de GPUs, puedes intentar ejecutarlo utilizando los recursos de GPU estables y rentables que proporciona Novita. Novita también admite el despliegue paralelo de 8 GPUs, que puede manejar cargas de trabajo con mayores demandas computacionales.
GLM-5 ofrece un rendimiento inigualable en codificación agéntica y razonamiento, pero la estrategia de acceso es crítica. Para la mayoría de los desarrolladores, la API de Novita AI ofrece la ruta más rápida y rentable con integración compatible con OpenAI, mientras que el Plan de Codificación oficial de Z.AI es adecuado para equipos pequeños que buscan cuotas mensuales predecibles. El despliegue local sigue siendo poco práctico para la mayoría debido a los requisitos extremos de VRAM. Comprender estos compromisos permite a los desarrolladores aprovechar GLM-5 de manera eficiente sin comprometer demasiados recursos.
Preguntas Frecuentes
¿Qué es GLM-5 y qué lo hace adecuado para tareas de codificación?
GLM-5 es el modelo de mezcla de expertos de 754B parámetros de Z.AI con 40B parámetros activos por paso. Destaca en la planificación autónoma de código, la conciencia de contexto de múltiples archivos y la descomposición de solicitudes complejas en pasos ejecutables, lo que lo hace ideal para tareas de codificación de largo alcance.
¿Cuáles son los beneficios de usar el Plan de Codificación de Z.AI para GLM-5?
El Plan de Codificación de Z.AI ofrece un paquete de suscripción con cuotas fijas de solicitudes y un endpoint de codificación dedicado. Está optimizado para tareas de codificación de alta frecuencia como generación, finalización y depuración de código en IDEs compatibles como OpenCode o Cline.
¿Es factible el despliegue local de GLM-5 para la mayoría de los equipos?
El despliegue local de GLM-5 requiere una enorme cantidad de VRAM (hasta 1508 GB en BF16), lo que lo hace poco práctico para casi todas las configuraciones individuales o de equipos pequeños. Incluso la cuantización agresiva requiere cientos de gigabytes de VRAM, lo que limita la accesibilidad.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.
Lectura Recomendada



