

Entwickler, die GLM-5 nutzen möchten, stehen oft vor der großen Herausforderung, die praktischste Zugriffsmethode zu wählen. Mit agentischen Codierungs- und Schlussfolgerungsfähigkeiten auf Spitzenniveau bei 754B Parametern kann GLM-5 komplexe, mehrstufige Codierungsaufgaben und die Wahrnehmung von Projekten mit mehreren Dateien bewältigen. Die Optionen reichen von der offiziellen Z.AI-API und Codierungs-Abonnementplänen über Drittanbieter wie Novita AI bis hin zur lokalen Bereitstellung, die prohibitiv hohe Hardwareanforderungen stellt. Dieser Artikel geht auf die zentralen Pain Points von Entwicklern ein: Kosteneffizienz, Integrationskomplexität, Latenz und Hardware-Machbarkeit. Wir zerlegen den GLM-5-Zugriff aus drei Perspektiven: Offizielle API vs. Codierungsplan, OpenAI-kompatible Drittanbieter und Realitäten der lokalen Bereitstellung – und geben praxisnahe Empfehlungen für die Wahl der optimalen Konfiguration.
Was ist GLM-5?
GLM-5 ist ein 754B-Parameter-Mixture-of-Experts-Modell von Z.AI mit 40B aktiven Parametern pro Vorwärtsdurchlauf, das für komplexe Systementwicklung und langfristige agentische Aufgaben ausgelegt ist. Gegenüber GLM-4.5 mit 355B Parametern und 23T Trainings-Token wurde es auf 28,5T Token mit DeepSeek Sparse Attention (DSA) skaliert, erreicht ein Kontextfenster von 200K bei reduzierten Bereitstellungskosten. Die MoE-Architektur leitet jedes Token durch 8 von 256 Experten plus 1 gemeinsam genutzten Experten, was die Latenz bis zum ersten Token trotz 754B Gesamtparametern näher an die eines 30-70B-Dense-Modells bringt.
Von Huggingface
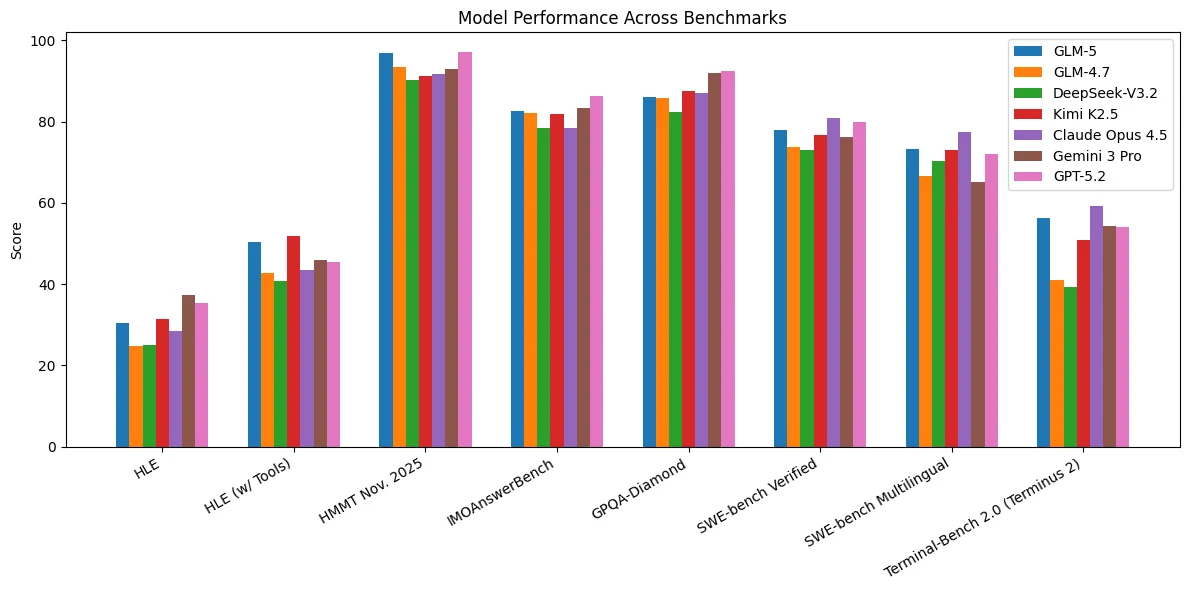
GLM-5 zeigt durchgängig starke Leistung in einer Vielzahl von Benchmarks zu Schlussfolgerung, Codierung und agentischen Aufgaben. Es gehört zu den Top-Modellen bei HLE, HLE (mit Tools) und HMMT Nov. 2025, was auf solide analytische Schlussfolgerungsfähigkeiten und effektive, tool-gestützte Problemlösung hindeutet.
Probieren Sie GLM-5 jetzt aus!
1. Offizieller API-Zugriff (Z.ai)
Z.AI bietet die offizielle GLM-5-API über seine Plattform an.
Einrichtungsschritte
- Erstellen Sie ein Konto auf Z.ai und navigieren Sie zu den API-Einstellungen
- Generieren Sie einen API-Schlüssel im Entwickler-Dashboard
- Installieren Sie den OpenAI-kompatiblen Client:
pip install openai
Codebeispiel
from openai import OpenAI
client = OpenAI(
api_key="your-Z.AI-api-key",
base_url="https://api.z.ai/api/paas/v4/",
)
completion = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "You are a smart and creative novelist"},
{
"role": "user",
"content": "Please write a short fairy tale story as a fairy tale master",
},
],
)
print(completion.choices[0].message.content)
Preise
Die Preise von Z.ai sind in Abonnementplänen gebündelt. Der 10 $/Monat-Codierungsplan bietet Zugriff auf GLM-5 über deren OpenClaw-Oberfläche, geeignet für einzelne Entwickler und kleine Teams.
| Aspekt | Z.AI API | Z.AI Codierungsplan |
|---|---|---|
| Zweck | Allgemeiner Modellzugriff über REST-API | Abonnementpaket, das auf Codierungs-/Code-Assistent-Anwendungsfälle spezialisiert ist |
| Abrechnungsmodell | Pay-per-Use (Tokens/Aufrufe) | Monatliches Abonnement mit Kontingentlimits |
| Nutzungsbereich | Kann für jede Anwendung genutzt werden (Chat, Textgenerierung, Schlussfolgerung) | Funktioniert nur innerhalb unterstützter Codierungstools/IDEs (z. B. Cline, Claude Code, OpenCode usw.) |
| Endpunkt | Allgemeiner API-Endpunkt (/api/paas/v4) (Z.ai) |
Spezieller Codierungsendpunkt (/api/coding/paas/v4) |
| Kontingent | Abrechnung pro Anfrage/Token ohne festes Prompt-Kontingent | Feste Prompt-Kontingente pro Zeitfenster (z. B. pro 5-Stunden-Zyklus) je nach Planstufe |
| Kostenvorhersagbarkeit | Zahlt genau für die Nutzung, kann schwanken | Feste monatliche Kosten mit vorhersagbaren Kontingentlimits |
| Integration | Wird direkt über SDK/REST aus Ihren eigenen Apps/Diensten aufgerufen | Nur in kompatiblen Codierungsumgebungen/-tools integriert |
| Ideal für | Allgemeine KI-Bedürfnisse (Chatbots, Assistenten, Workflows) | Hochfrequente Codierungsaufgaben: Codegenerierung, Vervollständigung, Debugging |
2. OpenAI-kompatible Drittanbieter-APIs
Mehrere Anbieter bieten GLM-5 über OpenAI-kompatible APIs an. Basierend auf Benchmarks der HuggingFace Inference Provider zeigen wir hier den Vergleich:

Novita AI (Am günstigsten für Entwickler)
Novita AI bietet wettbewerbsfähige Preise von 1,00 $/3,20 $ pro 1M Eingabe-/Ausgabe-Token mit einem Kontextfenster von 202.800 und einer Time-to-First-Token von 1,09 s. Die OpenAI-kompatible API eliminiert den Integrationsaufwand.
Warum Novita AI?
- Drop-in-OpenAI-Ersatz: Keine Codeänderungen bei der Migration vom OpenAI-SDK
- Transparente Preisgestaltung: Keine versteckten Gebühren oder Ratenlimits bei Standardplänen
- Unterstützung für Funktionsaufrufe: Native Tool-Integration für agentische Workflows
- Breiter Modellkatalog: Zugriff auf über 100 Modelle über eine einheitliche API
Einrichtungsschritte
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Loggen Sie sich in Ihrem Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Probieren Sie GLM-5 jetzt aus!
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Wenn Sie die Seite „Einstellungen“ aufrufen, können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Verbinden Sie Novita AI einfach mit Partnerplattformen wie Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow und OpenClaw mithilfe von API-Integrationen und Schritt-für-Schritt-Einrichtungsanleitungen.
3. Realitätscheck zur lokalen Bereitstellung
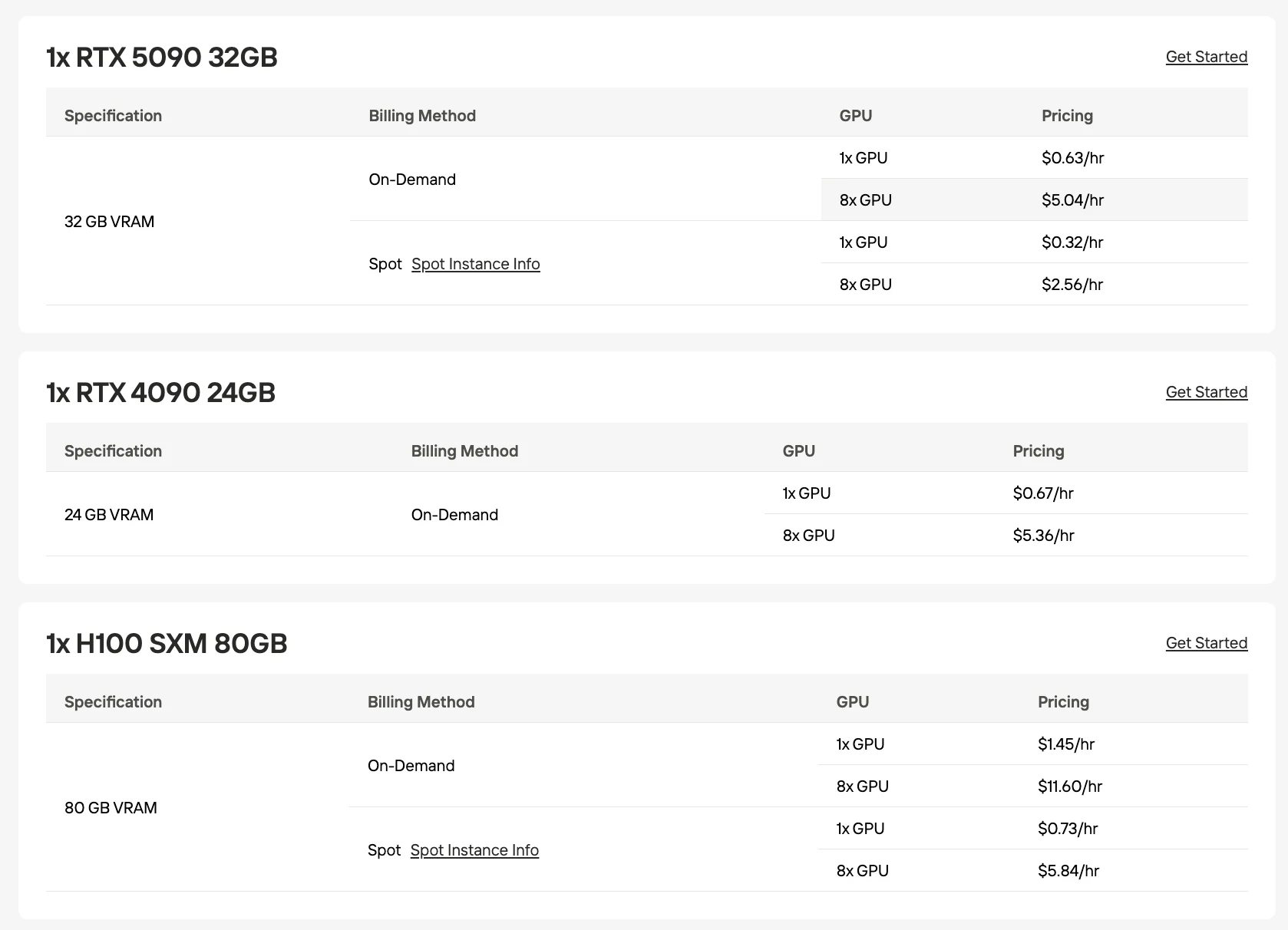
Die lokale Bereitstellung von GLM-5 steht vor erheblichen Hardware-Hürden. Das Modell benötigt 1508 GB VRAM bei BF16-Präzision, was bei UD-IQ2_XXS-Quantisierung auf 241 GB sinkt. Selbst die aggressivste Quantisierung übersteigt den VRAM jeder einzelnen Consumer- oder Prosumer-GPU.
VRAM-Anforderungen nach Quantisierung
| Quantisierung | Erforderlicher VRAM | GPU-Konfiguration |
|---|---|---|
| BF16 (voll) | 1508 GB | 19×H100 80GB |
| Q8_0 | 801 GB | 11×H100 80GB |
| Q6_K | 619 GB | 8×H100 80GB |
| Q4_K_M | 456 GB | 6×H100 80GB |
| Q3_K_M | 360 GB | 5×H100 80GB |
| Q2_K | 276 GB | 4×H100 80GB |
| UD-IQ2_XXS | 241 GB | 3×H100 80GB |
Obwohl für diese Aufgabe eine große Anzahl von GPUs erforderlich ist, können Sie den Betrieb mit den stabilen und kostengünstigen GPU-Ressourcen von Novita testen. Novita unterstützt zudem die 8-GPU-Parallelbereitstellung, die Workloads mit höherem Rechenbedarf abdeckt.
Testen Sie jetzt kostengünstige GPUs!
GLM-5 bietet unübertroffene Leistung bei agentischer Codierung und Schlussfolgerung, aber die Zugriffsstrategie ist entscheidend. Für die meisten Entwickler ist die Novita AI API die schnellste, kostengünstigste Möglichkeit mit OpenAI-kompatibler Integration, während der offizielle Codierungsplan von Z.AI für kleine Teams geeignet ist, die vorhersagbare monatliche Kontingente suchen. Die lokale Bereitstellung bleibt für die meisten aufgrund der extremen VRAM-Anforderungen unpraktikabel. Das Verständnis dieser Trade-offs ermöglicht es Entwicklern, GLM-5 effizient zu nutzen, ohne übermäßig Ressourcen zu binden.
Häufig gestellte Fragen
Was ist GLM-5 und was macht es für Codierungsaufgaben geeignet?
GLM-5 ist ein 754B-Parameter-Mixture-of-Experts-Modell von Z.AI mit 40B aktiven Parametern pro Durchlauf. Es zeichnet sich durch autonome Code-Planung, Wahrnehmung von Kontexten mit mehreren Dateien und die Aufteilung komplexer Anfragen in ausführbare Schritte aus, was es ideal für langfristige Codierungsaufgaben macht.
Welche Vorteile bietet der Z.AI Codierungsplan für GLM-5?
Der Z.AI Codierungsplan bietet ein Abonnementpaket mit festen Prompt-Kontingenten und einem speziellen Codierungsendpunkt. Er ist optimiert für hochfrequente Codierungsaufgaben wie Codegenerierung, Vervollständigung und Debugging in unterstützten IDEs wie OpenCode oder Cline.
Ist die lokale Bereitstellung von GLM-5 für die meisten Teams machbar?
Die lokale Bereitstellung von GLM-5 erfordert massiven VRAM (bis zu 1508 GB bei BF16), was sie für fast alle Einzel- oder Kleinteam-Setups unpraktikabel macht. Selbst aggressive Quantisierung erfordert Hunderte von Gigabyte VRAM, was die Zugänglichkeit einschränkt.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine kostengünstige und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.
Empfohlene Lektüre



