

- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Tâche
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Présentation de base
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Benchmarks
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Coût d’utilisation
- Quel modèle de langage visuel utiliser ?
- Comment accéder à GLM 4.1V 9B Thinking et Qwen2.5 VL 72B via l’API Novita ?
Points clés
GLM 4.1V 9B Thinking : Idéal pour les Q&A interactifs et conviviaux et les tâches destinées aux consommateurs.
Qwen2.5 VL 72B : Meilleur choix pour la compréhension approfondie des documents et l’aide à l’image par IA.
Vous vous demandez si GLM 4.1V 9B Thinking ou Qwen2.5 VL 72B est fait pour vous ? Voici les réponses rapides ! De la lecture intelligente de documents aux Q&A interactifs et au support d’image par IA, découvrez quel modèle brille. Vous voulez connaître la logique derrière nos choix ? Il suffit de faire défiler !
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Tâche
Entrée :
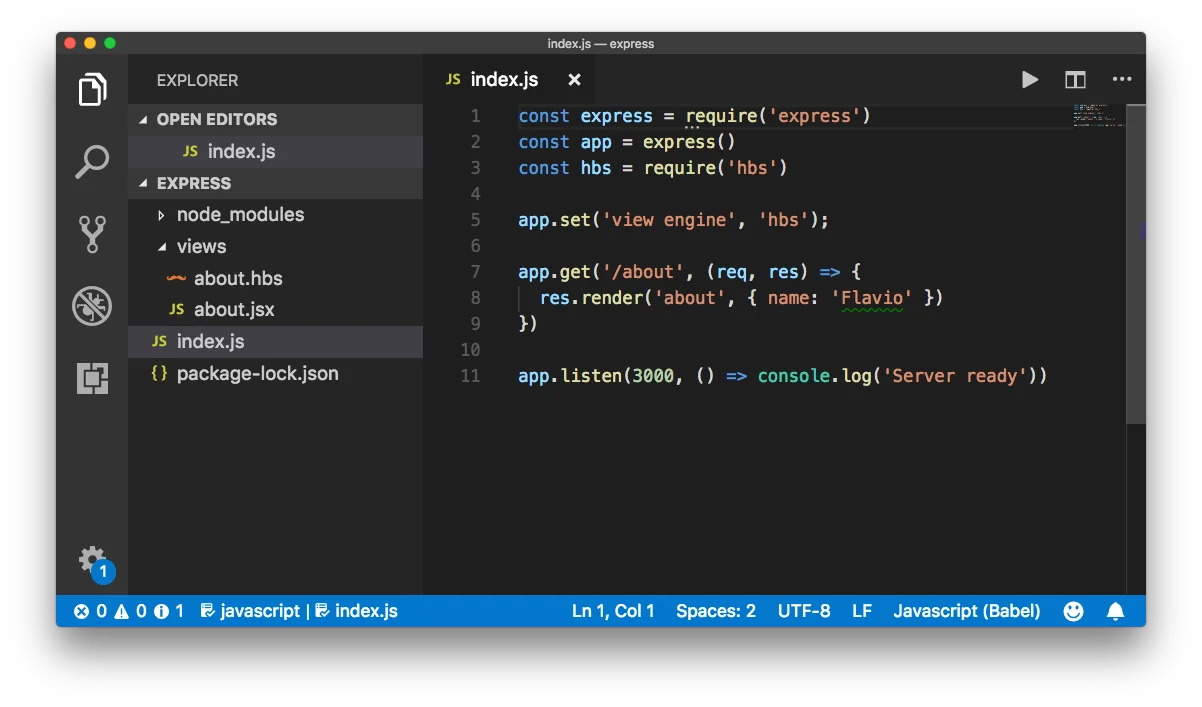
Sortie :

GLM 4.1V 9B Thinking

Qwen2.5 VL 72B
Évaluation de GLM 4.1V 9B Thinking et Qwen2.5 VL 72B :
GLM 4.1v 9B est meilleur pour répondre aux deux premières questions de manière conviviale, et il présente le contexte comme un tutoriel où l’utilisateur apprend ou suit. Cependant, aucune réponse ne fournit directement d’étapes actionnables.
Qwen 2.5 VL 72B
- Qu’est-ce que cette page ?
Elle explique le code et le contexte, mais ne décrit pas explicitement l’interface utilisateur ou ce que l’utilisateur voit sur la page (comme un tutoriel, un éditeur de code ou une capture d’écran de page web). - À quoi sert le code ?
Fournit une explication technique détaillée de l’objectif du code et de ce qu’il accomplit.
GLM 4.1v 9B
- Qu’est-ce que cette page ?
Explique directement que la page est un exemple de code, probablement dans le cadre d’un tutoriel, et décrit ce qui est affiché (un éditeur de code, des fichiers, etc.). - À quoi sert le code ?
Résume clairement l’objectif du code : configurer une route Express et rendre une page dynamique.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Présentation de base
| Fonctionnalité | GLM 4.1v 9B | Qwen 2.5 VL 72B |
|---|---|---|
| Taille du modèle | 9B | 73.4B |
| Open Source | Oui | Oui |
| Méthode d’entraînement | Basé sur GLM 4 9B 0414 | Peut-être basé sur Qwen 2 VL |
| Fenêtre de contexte | 64K et résolution d’image 4K | 64K (vidéos de plus d’1 heure) |
| Capacité multimodale | Entrées visuelles (images et vidéos) et textuelles, mais pas simultanées image et vidéo | Entrées visuelles (images et vidéos) et textuelles |
| Support linguistique | Prend en charge le chinois et l’anglais | En plusieurs langues |
| Raisonnement en chaîne de pensée | Fournit un raisonnement « chain-of-thought » (CoT) | Non |
| Traitement de documents | Excelle dans les STIM et les documents longs | Excellent OCR et extraction de documents |
GLM 4.1V 9B Thinking est entraîné sur GLM 4 9B 0414 et est conçu pour repousser les limites du raisonnement dans les modèles vision-langage. En introduisant un « paradigme de réflexion » et en utilisant l’apprentissage par renforcement, le modèle améliore considérablement ses capacités. En tant que premier modèle vision-langage à implémenter le raisonnement en chaîne de pensée (CoT), GLM 4.1V 9B Thinking établit une nouvelle référence en raisonnement multimodal.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Benchmarks
| Benchmark | GLM 4.1V‑9B | Qwen 2.5 VL 72B | Gagnant |
|---|---|---|---|
| MMMU (image) | 68.0 | 70.2 | Qwen 2.5 VL |
| MMMU‑Pro | 57.1 | 51.1 | GLM |
| VideoMMMU | 61.0 | 60.2 | GLM |
| mvBench (video) | 70.4 | 64.6 | GLM |
| AITZ_EM (agent) | 83.2 | 35.3* | GLM |
| Agent (OSWorld) | 14.9 | 8.8 | GLM |
| Agent (AndroidWorld) | 41.7 | 35.0 | GLM |
| Agent (WebVoyageSom) | 69.0 | 40.4 | GLM |
| Agent (Webquest‑SingleQA) | 72.1 | 60.5 | GLM |
| Agent (Webquest‑MultiQA) | 54.7 | 52.1 | GLM |
| Coding (Design2Code) | 64.7 | 41.9 | GLM |
| Coding (Flame‑VLM‑Code) | 72.5 | 46.3 | GLM |
| OCRBench | 84.2 | 85.1 | Qwen 2.5 VL |
| VideoMME (sans texte) | 68.2 | 73.3 | Qwen 2.5 VL |
| VideoMME (avec texte) | 73.6 | 79.1 | Qwen 2.5 VL |
| MMVU | 59.4 | 62.9 | Qwen 2.5 VL |
Choisissez GLM 4.1V‑Thinking si votre priorité est le raisonnement multimodal, les capacités d’agent, la résolution de problèmes STIM ou le codage.
Choisissez Qwen 2.5 VL 72B si vous vous concentrez sur la compréhension de documents/images/vidéos – en particulier l’OCR, l’extraction structurée et la perception visuelle.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B : Coût d’utilisation
Si vous souhaitez un accès local :
| Fonctionnalité | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| Modèle GPU | RTX 4090 | H100 |
| GPUs utilisés | 1 GPU | 8 GPUs |
| VRAM total | 22 Go | ~640 Go |
| Prix total | ~2 935 $ sur Amazon | ~ 25 000 $ par GPU directement chez NVIDIA |
| Prix GPU cloud (Novita AI) | 0,69 $/h | 20,48 $/h |
Si vous souhaitez utiliser une API comme Novita AI :
| Modèle | Fenêtre de contexte | Prix d’entrée (/1M tokens) | Prix de sortie (/1M tokens) |
|---|---|---|---|
| GLM 4.1V 9B-Thinking | 65 536 | 0,035 $ | 0,138 $ |
| Qwen2.5 VL 72B Instruct | 32 768 | 0,80 $ | 0,80 $ |
GLM 4.1V 9B-Thinking offre une bien meilleure accessibilité et rentabilité pour une utilisation locale et via API.
Qwen 2.5 VL 72B est destiné aux utilisateurs ayant des besoins et des ressources très haut de gamme.
Quel modèle de langage visuel utiliser ?
1. Pour la compréhension de documents
Qwen2.5 VL 72B est plus adapté.
Raison : Qwen2.5 VL 72B excelle en OCR, extraction de documents et traitement de documents complexes et structurés (y compris la reconnaissance de texte en environnement naturel). Il est conçu pour des tâches de compréhension de documents de haute précision, notamment dans des contextes multilingues.
2. Pour les Q&A multimodaux grand public (To-C)
GLM 4.1V 9B Thinking est plus adapté.
Raison : GLM 4.1V 9B Thinking fournit des réponses conviviales, de style tutoriel, un raisonnement en chaîne de pensée solide et est efficace pour les Q&A interactifs de type agent. Cela en fait un meilleur choix pour les applications grand public évolutives et réactives.
3. Pour l’assistance d’images générées par IA (support dessin/génération d’images par IA)
Qwen2.5 VL 72B est plus adapté.
Raison : Qwen2.5 VL 72B possède des capacités multimodales avancées, notamment en perception visuelle, compréhension d’images et extraction structurée, ce qui le rend meilleur pour les scénarios où l’IA aide les utilisateurs à générer ou comprendre des images.
Comment accéder à GLM 4.1V 9B Thinking et Qwen2.5 VL 72B via l’API Novita ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page “Settings“, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking est votre meilleur choix pour les Q&A interactifs et conviviaux et les applications grand public.
Qwen2.5 VL 72B se distingue pour la compréhension approfondie des documents et le puissant support d’images par IA.
Choisissez le modèle qui correspond à vos besoins – et si vous êtes curieux de savoir pourquoi, faites défiler pour les détails !
Questions fréquentes
Quel modèle choisir pour la compréhension de documents ?
Optez pour Qwen2.5 VL 72B. Il est excellent en OCR, extraction de documents et lecture de fichiers complexes. Qwen2.5-VL-72B, avec un score DocVQA de 96,4.
Et pour les Q&A interactifs grand public ?
GLM 4.1V 9B Thinking est conçu pour cela – attendez-vous à des réponses conviviales, conversationnelles et intelligentes.
Quel modèle aide le plus avec les images générées par IA ou le support d’images ?
Qwen2.5 VL 72B est plus fort pour les tâches d’image par IA, la perception visuelle et l’assistance basée sur l’image.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.



