

- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Tarea
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Introducción básica
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Puntos de referencia (Benchmark)
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Costo de uso
- ¿Qué modelo de lenguaje visual usar?
- ¿Cómo acceder a GLM 4.1V 9B Thinking y Qwen2.5 VL 72B a través de la API de Novita?
Aspectos destacados
GLM 4.1V 9B Thinking: Ideal para preguntas y respuestas interactivas amigables y tareas orientadas al consumidor.
Qwen2.5 VL 72B: La mejor opción para comprensión profunda de documentos y asistencia con imágenes de IA.
¿Te preguntas si GLM 4.1V 9B Thinking o Qwen2.5 VL 72B es el adecuado para ti? ¡Tenemos las respuestas rápidas! Desde lectura inteligente de documentos hasta preguntas y respuestas interactivas y soporte de imágenes con IA, descubre qué modelo destaca. ¿Quieres saber la lógica detrás de nuestras elecciones? ¡Desliza hacia abajo!
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Tarea
Entrada:
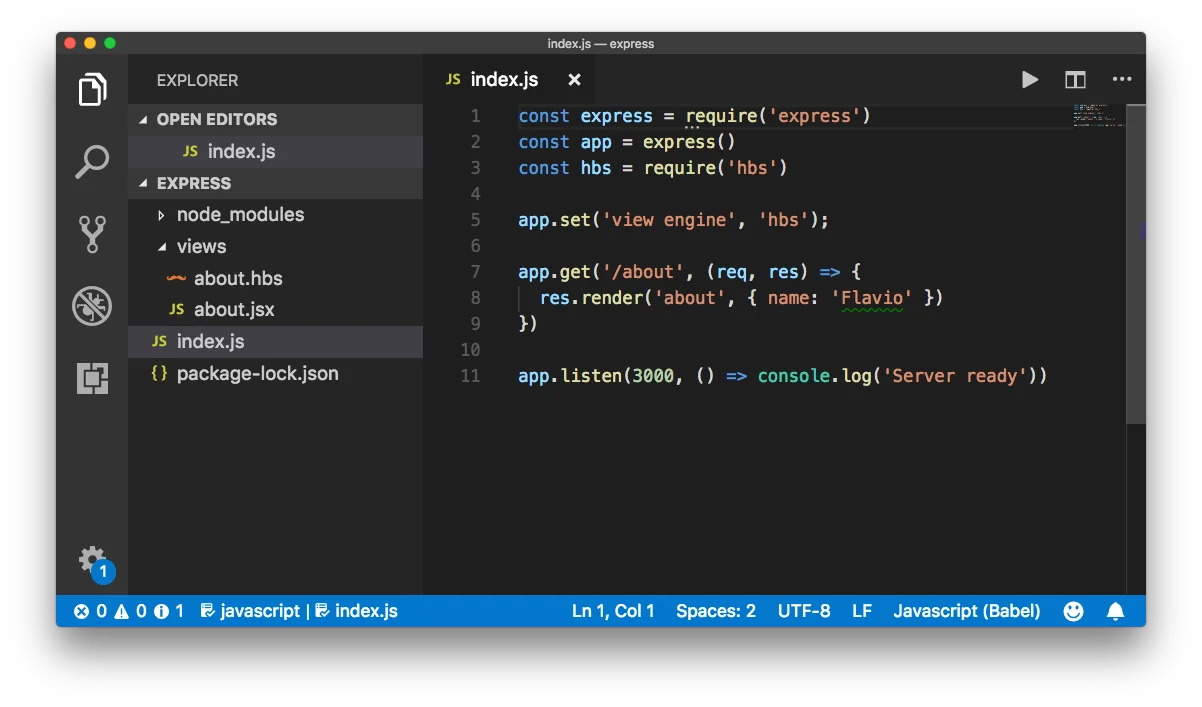
Salida:

GLM 4.1V 9B Thinking

Qwen2.5 VL 72B
Evaluación de GLM 4.1V 9B Thinking y Qwen2.5 VL 72B:
GLM 4.1v 9B es mejor respondiendo las dos primeras preguntas de manera amigable, y enmarca el contexto como un tutorial donde el usuario está aprendiendo o siguiendo los pasos. Sin embargo, ninguna de las respuestas proporciona directamente pasos accionables.
Qwen 2.5 VL 72B
- ¿Qué es esta página?
Explica el código y el contexto, pero no describe explícitamente la interfaz de usuario ni lo que el usuario está viendo en la página (como un tutorial, editor de código o captura de pantalla de una página web). - ¿Para qué sirve el código?
Proporciona una explicación técnica detallada del propósito del código y lo que logra.
GLM 4.1v 9B
- ¿Qué es esta página?
Explica directamente que la página es un ejemplo de código, probablemente parte de un tutorial, y describe lo que se muestra (un editor de código, archivos, etc.). - ¿Para qué sirve el código?
Resume claramente el propósito del código: configurar una ruta de Express y renderizar una página dinámica.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Introducción básica
| Característica | GLM 4.1v 9B | Qwen 2.5 VL 72B |
|---|---|---|
| Tamaño del modelo | 9B | 73.4B |
| Código abierto | Sí | Sí |
| Método de entrenamiento | Basado en GLM 4 9B 0414 | Posiblemente basado en Qwen 2 VL |
| Ventana de contexto | 64K y resolución de imagen 4K | 64K (videos de más de 1 hora) |
| Capacidad multimodal | Entrada visual (imágenes y videos) y textual, pero no simultáneamente imagen y video | Entrada visual (imágenes y videos) y textual |
| Soporte de idiomas | Chino e inglés | Múltiples idiomas |
| Razonamiento en cadena de pensamiento | Proporciona razonamiento “chain-of-thought” (CoT) | No |
| Procesamiento de documentos | Destaca en STEM y documentos largos | Excelente OCR y extracción de documentos |
GLM 4.1V 9B Thinking está entrenado en GLM 4 9B 0414 y está diseñado para ampliar los límites del razonamiento en modelos de lenguaje visual. Al introducir un “paradigma de pensamiento” y aprovechar el aprendizaje por refuerzo, el modelo mejora significativamente sus capacidades. Como el primer modelo de lenguaje visual en implementar razonamiento en cadena de pensamiento (CoT), GLM 4.1V 9B Thinking establece un nuevo punto de referencia en razonamiento multimodal.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Puntos de referencia (Benchmark)
| Benchmark | GLM 4.1V‑9B | Qwen 2.5 VL 72B | Ganador |
|---|---|---|---|
| MMMU (imagen) | 68.0 | 70.2 | Qwen 2.5 VL |
| MMMU‑Pro | 57.1 | 51.1 | GLM |
| VideoMMMU | 61.0 | 60.2 | GLM |
| mvBench (video) | 70.4 | 64.6 | GLM |
| AITZ_EM (agente) | 83.2 | 35.3* | GLM |
| Agente (OSWorld) | 14.9 | 8.8 | GLM |
| Agente (AndroidWorld) | 41.7 | 35.0 | GLM |
| Agente (WebVoyageSom) | 69.0 | 40.4 | GLM |
| Agente (Webquest‑SingleQA) | 72.1 | 60.5 | GLM |
| Agente (Webquest‑MultiQA) | 54.7 | 52.1 | GLM |
| Codificación (Design2Code) | 64.7 | 41.9 | GLM |
| Codificación (Flame‑VLM‑Code) | 72.5 | 46.3 | GLM |
| OCRBench | 84.2 | 85.1 | Qwen 2.5 VL |
| VideoMME (sin texto) | 68.2 | 73.3 | Qwen 2.5 VL |
| VideoMME (con texto) | 73.6 | 79.1 | Qwen 2.5 VL |
| MMVU | 59.4 | 62.9 | Qwen 2.5 VL |
Elige GLM 4.1V‑Thinking si tu prioridad es el razonamiento multimodal, las capacidades de agente, la resolución de problemas STEM o la codificación.
Elige Qwen 2.5 VL 72B si te enfocas en la comprensión de documentos/imágenes/video—especialmente OCR, extracción estructurada y percepción visual.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Costo de uso
Si deseas acceso local:
| Característica | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| Modelo de GPU | RTX 4090 | H100 |
| GPUs utilizadas | 1 GPU | 8 GPUs |
| VRAM total | 22 GB | ~640 GB |
| Precio total | ~$2,935 en Amazon | ~ $25,000 por GPU directo de NVIDIA |
| Precio de GPU en la nube (Novita AI) | $0.69/hora | $20.48/hora |
Si deseas usar API como Novita AI:
| Modelo | Ventana de contexto | Precio de entrada (/1M tokens) | Precio de salida (/1M tokens) |
|---|---|---|---|
| GLM 4.1V 9B-Thinking | 65,536 | $0.035 | $0.138 |
| Qwen2.5 VL 72B Instruct | 32,768 | $0.80 | $0.80 |
GLM 4.1V 9B-Thinking ofrece una accesibilidad y eficiencia de costos mucho mejores tanto para uso local como para API.
Qwen 2.5 VL 72B está dirigido a usuarios con requisitos y recursos de muy alto nivel.
¿Qué modelo de lenguaje visual usar?
- Para comprensión de documentos
Qwen2.5 VL 72B es más adecuado.
Razón: Qwen2.5 VL 72B destaca en OCR, extracción de documentos y procesamiento de documentos complejos y estructurados (incluyendo reconocimiento de texto en escenas naturales). Está diseñado para tareas de comprensión de documentos de alta precisión, especialmente en entornos multilingües.
- Para preguntas y respuestas multimodales orientadas al consumidor (To-C)
GLM 4.1V 9B Thinking es más adecuado.
Razón: GLM 4.1V 9B Thinking proporciona respuestas amigables, estilo tutorial, razonamiento sólido en cadena de pensamiento y es eficiente para preguntas y respuestas interactivas estilo agente. Esto lo convierte en una mejor opción para aplicaciones de consumo escalables y receptivas.
- Para asistencia con imágenes generadas por IA (AI Drawing/Gen-Image Support)
Qwen2.5 VL 72B es más adecuado.
Razón: Qwen2.5 VL 72B tiene capacidades multimodales avanzadas, particularmente en percepción visual, comprensión de imágenes y extracción estructurada, lo que lo hace mejor para escenarios donde la IA ayuda a los usuarios a generar o comprender imágenes.
¿Cómo acceder a GLM 4.1V 9B Thinking y Qwen2.5 VL 72B a través de la API de Novita?
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página Settings y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el administrador de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking es tu mejor opción para preguntas y respuestas interactivas amigables y aplicaciones de consumo.
Qwen2.5 VL 72B destaca en comprensión profunda de documentos y potente soporte de imágenes con IA.
Elige el modelo que se adapte a tus necesidades—y si tienes curiosidad sobre por qué, ¡desplázate hacia abajo para los detalles!
Preguntas frecuentes
¿Qué modelo debo elegir para la comprensión de documentos?
Opta por Qwen2.5 VL 72B. Es excelente en OCR, extracción de documentos y lectura de archivos complejos. Qwen2.5-VL-72B obtiene una puntuación de 96.4 en DocVQA.
¿Y para preguntas y respuestas interactivas orientadas al consumidor?
GLM 4.1V 9B Thinking está diseñado para eso: espera respuestas amigables, conversacionales e inteligentes.
¿Qué modelo ayuda más con imágenes generadas por IA o soporte de imágenes?
Qwen2.5 VL 72B es más fuerte en tareas de imágenes con IA, percepción visual y asistencia basada en imágenes.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera fácil de implementar modelos de IA utilizando nuestra simple API, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.



