

- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Aufgabe
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Einführung
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Benchmark
- GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Nutzungskosten
- Welches visuelle Sprachmodell verwenden?
- Wie greife ich über die Novita API auf GLM 4.1V 9B Thinking und Qwen2.5 VL 72B zu?
Wichtige Highlights
GLM 4.1V 9B Thinking: Am besten für freundliche, interaktive Q&A und intelligente kundenorientierte Aufgaben.
Qwen2.5 VL 72B: Erste Wahl für tiefgehendes Dokumentenverständnis und KI-Bildunterstützung.
Sie fragen sich, ob GLM 4.1V 9B Thinking oder Qwen2.5 VL 72B das Richtige für Sie ist? Wir haben die schnellen Antworten! Vom intelligenten Dokumentenlesen über interaktive Q&A bis hin zur KI-Bildunterstützung – sehen Sie, welches Modell glänzt. Möchten Sie die Logik hinter unseren Entscheidungen erfahren? Scrollen Sie einfach weiter!
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Aufgabe
Eingabe:
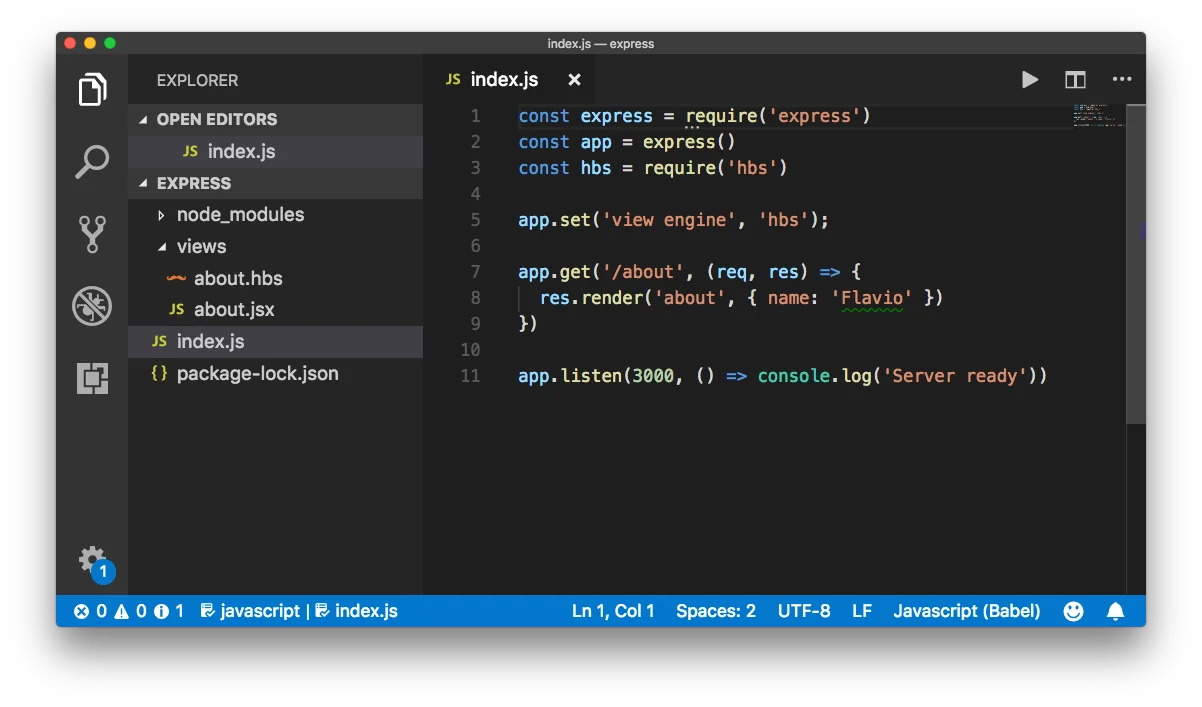
Ausgabe:

GLM 4.1V 9B Thinking

Qwen2.5 VL 72B
Bewertung von GLM 4.1V 9B Thinking und Qwen2.5 VL 72B:
GLM 4.1v 9B ist besser darin, die ersten beiden Fragen benutzerfreundlich zu beantworten, und stellt den Kontext als Tutorial dar, bei dem der Benutzer lernt oder mitmacht. Allerdings liefert keine der Antworten direkt umsetzbare nächste Schritte.
Qwen 2.5 VL 72B
- Was ist diese Seite?
Sie erklärt den Code und den Kontext, beschreibt jedoch nicht explizit die Benutzeroberfläche oder das, was der Benutzer auf der Seite sieht (wie ein Tutorial, einen Code-Editor oder einen Screenshot einer Webseite). - Wozu dient der Code?
Liefert eine detaillierte technische Erklärung des Zwecks des Codes und was er erreicht.
GLM 4.1v 9B
- Was ist diese Seite?
Erklärt direkt, dass es sich um ein Codebeispiel handelt, wahrscheinlich Teil eines Tutorials, und beschreibt, was angezeigt wird (ein Code-Editor, Dateien usw.). - Wozu dient der Code?
Fasst den Zweck des Codes klar zusammen: eine Express-Route einzurichten und eine dynamische Seite zu rendern.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Einführung
| Merkmal | GLM 4.1v 9B | Qwen 2.5 VL 72B |
|---|---|---|
| Modellgröße | 9B | 73,4B |
| Open Source | Ja | Ja |
| Trainingsmethode | Basiert auf GLM 4 9B 0414 | Möglicherweise basiert auf Qwen 2 VL |
| Kontextfenster | 64K und 4K Bildauflösung | 64K (Videos über 1 Stunde) |
| Multimodale Fähigkeit | Visuelle (Bilder und Videos) & Textuelle Eingaben, aber nicht gleichzeitig Bild & Video | Visuelle (Bilder und Videos) & Textuelle Eingaben |
| Sprachunterstützung | Unterstützt Chinesisch und Englisch | In mehreren Sprachen |
| Chain-of-Thought Denken | Bietet „Chain-of-Thought“ (CoT) Denken | Nein |
| Dokumentenverarbeitung | Hervorragend in MINT & langen Dokumenten | Hervorragende OCR & Dokumentenextraktion |
GLM 4.1V 9B Thinking wird auf GLM 4 9B 0414 trainiert und soll die Grenzen des Denkens in Vision-Language-Modellen erweitern. Durch die Einführung eines „Denkparadigmas“ und den Einsatz von Reinforcement Learning werden die Fähigkeiten des Modells deutlich verbessert. Als erstes Vision-Language-Modell, das Chain-of-Thought (CoT) Denken implementiert, setzt GLM 4.1V 9B Thinking einen neuen Maßstab im multimodalen Denken.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Benchmark
| Benchmark | GLM 4.1V‑9B | Qwen 2.5 VL 72B | Gewinner |
|---|---|---|---|
| MMMU (Bild) | 68,0 | 70,2 | Qwen 2.5 VL |
| MMMU‑Pro | 57,1 | 51,1 | GLM |
| VideoMMMU | 61,0 | 60,2 | GLM |
| mvBench (Video) | 70,4 | 64,6 | GLM |
| AITZ_EM (Agent) | 83,2 | 35,3* | GLM |
| Agent (OSWorld) | 14,9 | 8,8 | GLM |
| Agent (AndroidWorld) | 41,7 | 35,0 | GLM |
| Agent (WebVoyageSom) | 69,0 | 40,4 | GLM |
| Agent (Webquest‑SingleQA) | 72,1 | 60,5 | GLM |
| Agent (Webquest‑MultiQA) | 54,7 | 52,1 | GLM |
| Coding (Design2Code) | 64,7 | 41,9 | GLM |
| Coding (Flame‑VLM‑Code) | 72,5 | 46,3 | GLM |
| OCRBench | 84,2 | 85,1 | Qwen 2.5 VL |
| VideoMME (ohne Text) | 68,2 | 73,3 | Qwen 2.5 VL |
| VideoMME (mit Text) | 73,6 | 79,1 | Qwen 2.5 VL |
| MMVU | 59,4 | 62,9 | Qwen 2.5 VL |
Wählen Sie GLM 4.1V‑Thinking, wenn Ihr Schwerpunkt auf multimodalem Denken, Agentenfähigkeiten, MINT-Problemlösung oder Codierung liegt.
Wählen Sie Qwen 2.5 VL 72B, wenn Sie sich auf das Verstehen von Dokumenten/Bildern/Videos konzentrieren – insbesondere OCR, strukturierte Extraktion und visuelle Wahrnehmung.
GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Nutzungskosten
Wenn Sie lokal darauf zugreifen möchten:
| Merkmal | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B |
|---|---|---|
| GPU-Modell | RTX 4090 | H100 |
| Verwendete GPUs | 1 GPU | 8 GPUs |
| Gesamter VRAM | 22 GB | ~640 GB |
| Gesamtpreis | ~2.935 $ von Amazon | ~ 25.000 $ pro GPU direkt von NVIDIA |
| Cloud-GPU-Preis (Novita AI) | 0,69 $/Std. | 20,48 $/Std. |
Wenn Sie eine API wie Novita AI nutzen möchten:
| Modell | Kontextfenster | Eingabepreis (/1M Tokens) | Ausgabepreis (/1M Tokens) |
|---|---|---|---|
| GLM 4.1V 9B-Thinking | 65.536 | 0,035 $ | 0,138 $ |
| Qwen2.5 VL 72B Instruct | 32.768 | 0,80 $ | 0,80 $ |
GLM 4.1V 9B-Thinking bietet eine deutlich bessere Zugänglichkeit und Kosteneffizienz sowohl für lokale als auch für API-Nutzung.
Qwen 2.5 VL 72B richtet sich an Benutzer mit sehr hohen Anforderungen und Ressourcen.
Welches visuelle Sprachmodell verwenden?
1. Für Dokumentenverständnis
Qwen2.5 VL 72B ist besser geeignet.
Grund: Qwen2.5 VL 72B zeichnet sich durch OCR, Dokumentenextraktion und die Verarbeitung komplexer, strukturierter Dokumente (einschließlich Texterkennung in natürlichen Szenen) aus. Es ist für hochpräzise Aufgaben des Dokumentenverständnisses konzipiert, insbesondere in mehrsprachigen Umgebungen.
2. Für kundenorientierte (B2C) multimodale Q&A
GLM 4.1V 9B Thinking ist besser geeignet.
Grund: GLM 4.1V 9B Thinking liefert benutzerfreundliche, tutorialartige Antworten, starkes Chain-of-Thought-Denken und ist effizient für interaktive, agentenbasierte Q&A. Dies macht es zu einer besseren Wahl für skalierbare, reaktionsschnelle Verbraucheranwendungen.
3. Für KI-generierte Bildassistenz (KI-Zeichnen/Gen-Image-Unterstützung)
Qwen2.5 VL 72B ist besser geeignet.
Grund: Qwen2.5 VL 72B verfügt über erweiterte multimodale Fähigkeiten, insbesondere in der visuellen Wahrnehmung, Bildverständnis und strukturierten Extraktion, was es besser für Szenarien geeignet macht, in denen KI Benutzern beim Generieren oder Verstehen von Bildern hilft.
Wie greife ich über die Novita API auf GLM 4.1V 9B Thinking und Qwen2.5 VL 72B zu?
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf, um den API-Schlüssel wie im Bild gezeigt zu kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Vervollständigungs-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM 4.1V 9B Thinking ist Ihre beste Wahl für freundliche, interaktive Q&A und Verbraucheranwendungen.
Qwen2.5 VL 72B zeichnet sich durch tiefgehendes Dokumentenverständnis und leistungsstarke KI-Bildunterstützung aus.
Wählen Sie das Modell, das Ihren Anforderungen entspricht – und wenn Sie neugierig sind, warum, scrollen Sie nach unten für die Details!
Häufig gestellte Fragen
Welches Modell sollte ich für das Dokumentenverständnis wählen?
Nehmen Sie Qwen2.5 VL 72B. Es ist hervorragend in OCR, Dokumentenextraktion und beim Lesen komplexer Dateien. Qwen2.5-VL-72B erreicht einen DocVQA-Score von 96,4.
Was ist mit kundenorientierten, interaktiven Q&A?
GLM 4.1V 9B Thinking ist genau dafür gemacht – erwarten Sie benutzerfreundliche, gesprächige und intelligente Antworten.
Welches Modell hilft mehr bei KI-generierten Bildern oder Bildunterstützung?
Qwen2.5 VL 72B ist stärker bei KI-Bildaufgaben, visueller Wahrnehmung und bildbasierter Assistenz.
*Novita AI *ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbauen und Skalieren bereitstellt.



