

Pour soutenir la communauté open source de l’IA et accélérer l’innovation dans le traitement du langage naturel, Novita AI a rendu cinq modèles puissants librement accessibles via API. Ces modèles incluent le compact mais performant Llama 3.2 1B Instruct, le polyvalent Qwen2.5-7B Instruct, les très performants GLM-4-9B-0414 et GLM-Z1-9B-0414, ainsi que le modèle d’embedding multilingue et multifonctionnel BGE-M3. En offrant un accès ouvert à ces modèles, Novita AI souhaite permettre aux développeurs, chercheurs et startups de créer, tester et déployer des applications d’IA plus efficacement, sans le fardeau de coûts d’infrastructure élevés.
Llama 3.2 1b instruct
Essayez Llama 3.2 1B maintenant !
- Taille du modèle : 1,23 milliard de paramètres
- Architecture : Transformer optimisé avec attention par groupes de requêtes (GQA), activation SwiGLU, embeddings positionnels rotatifs (RoPE) et RMSNorm
- Longueur du contexte : 128 000 jetons
- Multilingue : prend officiellement en charge l’anglais, l’allemand, le français, l’italien, le portugais, l’hindi, l’espagnol et le thaï ; entraîné sur un ensemble plus large de langues
- Modalité : Texte-à-texte (entrée et sortie)
- Données d’entraînement : entraîné sur jusqu’à 9 000 milliards de jetons provenant de données en ligne publiquement disponibles
- Open Source : ✅
- Benchmark : démontre des performances solides dans des tâches telles que le suivi d’instructions, le résumé, la réécriture de prompts et l’utilisation d’outils ; compétitif avec d’autres modèles de sa catégorie de paramètres
Qwen2.5-7b-instruct
Essayez Qwen 2.5 7B maintenant !
Qwen 2.5 7B est un modèle de transformeur open source multilingue avec de solides performances dans les tâches générales, mathématiques, de codage et multilingues. Il est conçu pour la polyvalence, un déploiement léger et une large prise en charge linguistique.
- Taille du modèle : 7,61 milliards de paramètres
- Architecture : Transformer avec RoPE, SwiGLU, RMSNorm et Attention QKV bias
- Longueur du contexte : 128 000 jetons
- Multilingue : prend en charge plus de 29 langues
- Modalité : Texte-à-texte
- Données d’entraînement : entraîné sur 18 000 milliards+ de jetons
- Open Source : ✅
- Benchmark : Qwen 2.5 7B se classe systématiquement #1 dans toutes les catégories de cette suite de benchmarks – tâches générales, STEM, codage et compréhension multilingue – malgré un nombre de paramètres relativement compact.
GLM-4-9b-0414 et GLM-Z1-9b-0414
Essayez GLM-4 9B-0414 maintenant !
GLM-4-9B-0414 et GLM-Z1-9B-0414 sont deux modèles de langage open source de 9 milliards de paramètres développés par THUDM, chacun optimisé pour des tâches distinctes.
- GLM-4-9B-0414 : conçu pour la génération de dialogue, ce modèle hérite de l’architecture de GLM-4-32B et excelle dans des tâches telles que les conversations à plusieurs tours, la traduction et le résumé. Il prend en charge une fenêtre de contexte de 32K et convient aux déploiements à ressources limitées nécessitant de robustes capacités de compréhension et de génération de langage.
- GLM-Z1-9B-0414 : axé sur le raisonnement mathématique et les tâches générales, ce modèle intègre des techniques telles que l’apprentissage par renforcement étendu et l’alignement par classement par paires. Il démontre de solides performances en mathématiques, en code et en logique, surpassant de nombreux modèles open source de sa catégorie de poids.
| Caractéristique | Valeur |
|---|---|
| Taille du modèle | 9 milliards de paramètres |
| Points forts | - GLM-4-9B-0414 : excellent rapport performance/taille, excelle en mathématiques et raisonnement - GLM-Z1-9B-0414 : bonnes performances en mathématiques et tâches générales |
| Orientation des tâches | - GLM-4-9B-0414 : orienté conversation - GLM-Z1-9B-0414 : axé sur le raisonnement |
| Modalités | Texte-à-texte avec prise en charge de la visualisation HTML/SVG |
| Fenêtre de contexte | 32K jetons |
| Entraînement et alignement | Distillé depuis GLM-4-32B. Le modèle de base a été pré-entraîné sur 15 000 milliards de jetons de données de haute qualité (en particulier des données de raisonnement synthétiques) et aligné via un réglage des préférences humaines pour les tâches de dialogue. |
bge-m3
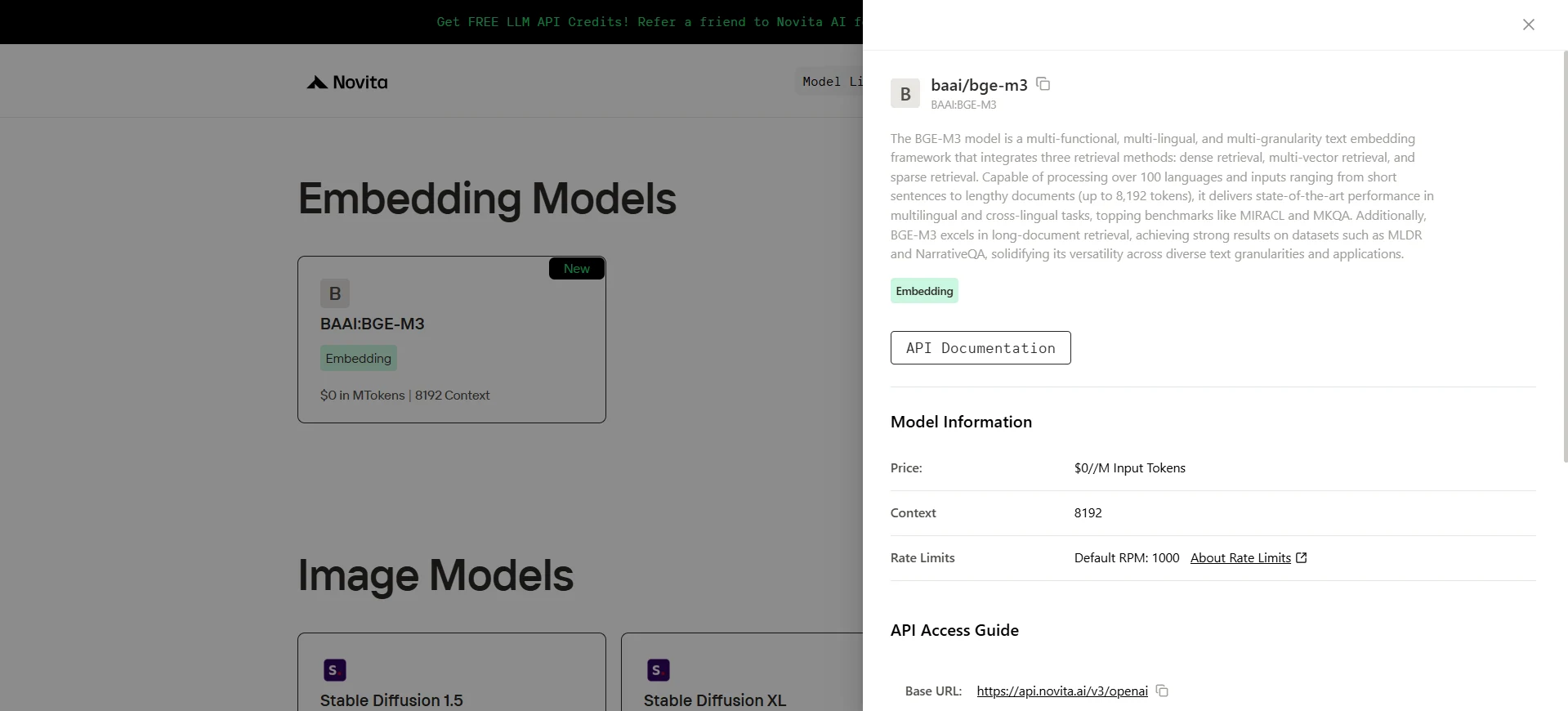
BGE-M3 est un modèle d’embedding textuel de pointe développé par l’Académie d’intelligence artificielle de Pékin (BAAI). Il est conçu pour une polyvalence exceptionnelle, offrant de solides performances sur trois dimensions clés : fonctionnalité, support linguistique et granularité d’entrée. BGE-M3 atteint des résultats de pointe sur plusieurs benchmarks, notamment MKQA et MLDR, surpassant systématiquement les modèles concurrents dans les scénarios de recherche monolingue et cross-lingue.
- Multi-fonctionnalité : BGE-M3 intègre de manière transparente trois stratégies de recherche dans une architecture unifiée :
- Recherche dense – génère une représentation vectorielle unique par entrée, idéale pour la correspondance sémantique générale.
- Recherche sparse – met l’accent sur l’importance au niveau des jetons, similaire à la correspondance lexicale traditionnelle.
- Recherche multi-vecteurs – produit plusieurs vecteurs par entrée pour capturer une sémantique fine et améliorer la précision de la recherche.
- Multilinguisme : prend en charge plus de 100 langues, permettant des capacités de recherche multilingue et cross-lingue.
- Multi-granularité : conçu pour traiter une large gamme de longueurs d’entrée – des courtes phrases aux longs documents – prenant en charge jusqu’à 8192 jetons par entrée.
Comment accéder aux modèles gratuits sur Novita AI ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Rendez-vous dans la page « Paramètres » et copiez la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "model name"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Que vous construisiez un chatbot intelligent, un moteur de recherche sémantique ou un système de recommandation multilingue, l’accès gratuit aux modèles de Novita AI vous offre tout ce dont vous avez besoin pour démarrer rapidement. Avec des performances de classe mondiale et une intégration API facile, ces modèles rendent l’IA évolutive plus accessible que jamais.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



