

Para apoyar a la comunidad de IA de código abierto y acelerar la innovación en el procesamiento del lenguaje natural, Novita AI ha puesto a disposición cinco modelos potentes de forma gratuita a través de API. Estos incluyen el compacto pero capaz Llama 3.2 1B Instruct, el versátil Qwen2.5-7B Instruct, los de alto rendimiento GLM-4-9B-0414 y GLM-Z1-9B-0414, así como el modelo de embeddings multilingüe y multifuncional BGE-M3. Al ofrecer acceso abierto a estos modelos, Novita AI busca empoderar a desarrolladores, investigadores y startups para construir, probar y escalar aplicaciones de IA de manera más eficiente, sin la carga de altos costos de infraestructura.
Llama 3.2 1b instruct
- Tamaño del modelo: 1.23B parámetros
- Arquitectura: Transformer optimizado con Grouped-Query Attention (GQA), activación SwiGLU, Rotary Positional Embeddings (RoPE) y RMSNorm
- Longitud de contexto: 128K tokens
- Multilingüe: Soporta oficialmente inglés, alemán, francés, italiano, portugués, hindi, español y tailandés; entrenado en un conjunto más amplio de idiomas
- Modalidad: Texto a texto (entrada y salida)
- Datos de entrenamiento: Entrenado con hasta 9 billones de tokens de datos públicos en línea
- Código abierto: ✅
- Benchmark: Muestra un rendimiento sólido en tareas como seguimiento de instrucciones, resumen, reescritura de prompts y uso de herramientas; competitivo con otros modelos de su clase de parámetros
Qwen2.5-7b-instruct
Qwen 2.5 7B es un modelo transformer multilingüe y de código abierto con un rendimiento sólido en tareas generales, matemáticas, codificación y multilingües. Está diseñado para versatilidad, despliegue ligero y amplio soporte de idiomas.
- Tamaño del modelo: 7.61B parámetros
- Arquitectura: Transformer con RoPE, SwiGLU, RMSNorm y Attention QKV bias
- Longitud de contexto: 128K tokens
- Multilingüe: Soporta más de 29 idiomas
- Modalidad: Texto a texto
- Datos de entrenamiento: Entrenado con 18T+ tokens
- Código abierto: ✅
- Benchmark: Qwen 2.5 7B ocupa consistentemente el #1 en todas las categorías en este conjunto de benchmarks —tareas generales, STEM, codificación y comprensión multilingüe— a pesar de tener un número de parámetros relativamente compacto.
GLM-4-9b-0414 y GLM-Z1-9b-0414
GLM-4-9B-0414 y GLM-Z1-9B-0414 son dos modelos de lenguaje de código abierto de 9 mil millones de parámetros desarrollados por THUDM, cada uno optimizado para tareas distintas.
- GLM-4-9B-0414: Diseñado para generación de diálogos, este modelo hereda la arquitectura de GLM-4-32B y destaca en tareas como conversaciones de múltiples turnos, traducción y resumen. Soporta una ventana de contexto de 32K y es adecuado para despliegues con recursos limitados que requieren capacidades sólidas de comprensión y generación de lenguaje.
- GLM-Z1-9B-0414: Enfocado en razonamiento matemático y tareas generales, este modelo incorpora técnicas como aprendizaje por refuerzo extendido y alineación por ranking de pares. Demuestra un rendimiento sólido en tareas de matemáticas, código y lógica, superando a muchos modelos de código abierto en su clase de peso.
| Característica | Valor |
|---|---|
| Tamaño del modelo | 9B parámetros |
| Fortalezas | - GLM-4-9B-0414: Alta relación rendimiento-tamaño, destaca en Matemáticas y Razonamiento - GLM-Z1-9B-0414: Rendimiento sólido en Matemáticas y Tareas Generales |
| Orientación de tareas | - GLM-4-9B-0414: Orientado a chat - GLM-Z1-9B-0414: Enfocado en razonamiento |
| Modalidades | Texto a texto con soporte de visualización HTML/SVG |
| Ventana de contexto | 32K tokens |
| Entrenamiento y alineación | Destilado de GLM-4-32B. El modelo base fue preentrenado con 15 billones de tokens de datos de alta calidad (especialmente datos sintéticos de razonamiento) y alineado mediante ajuste de preferencias humanas para tareas de diálogo. |
bge-m3
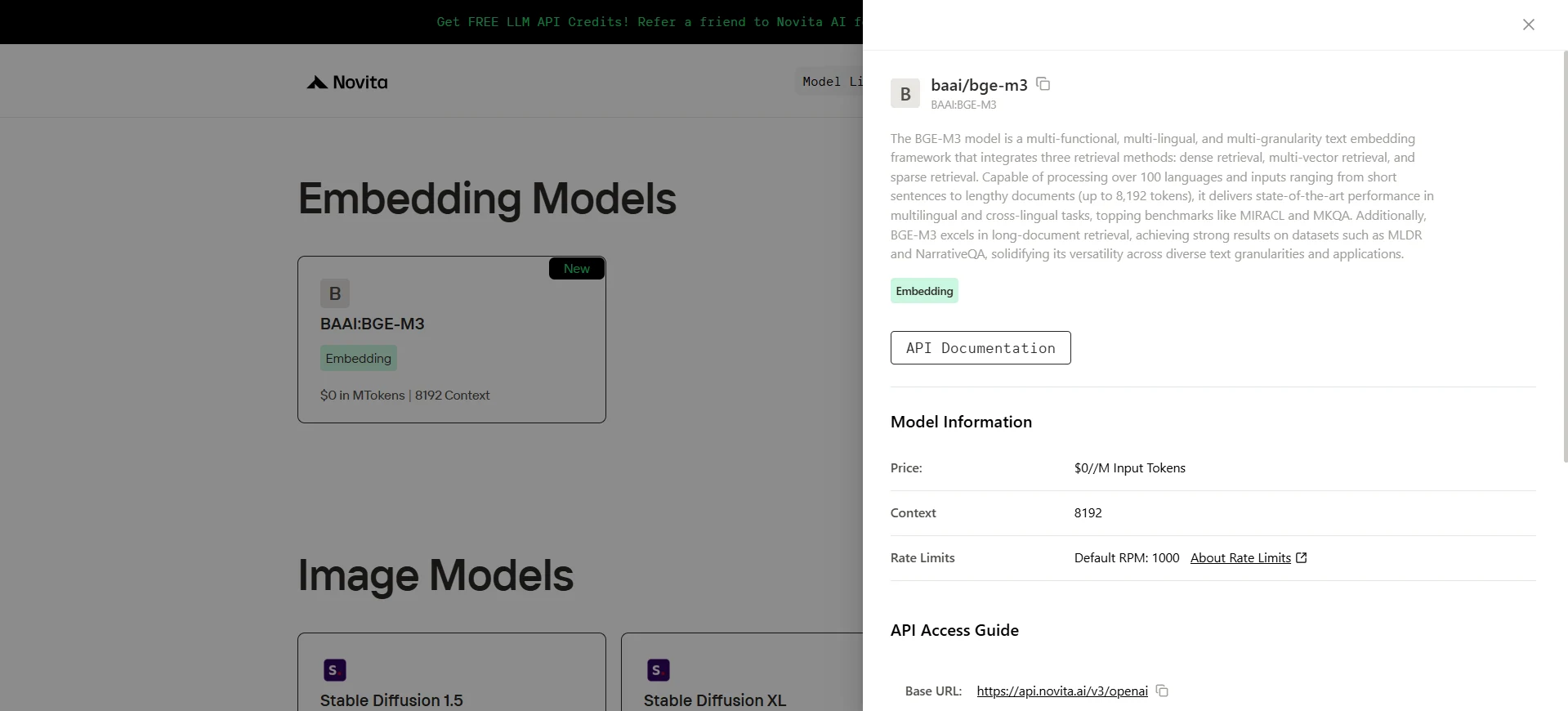
BGE-M3 es un modelo de embeddings de texto de última generación desarrollado por la Academia de Inteligencia Artificial de Pekín (BAAI). Está diseñado para una versatilidad excepcional, ofreciendo un rendimiento sólido en tres dimensiones clave: funcionalidad, soporte de idiomas y granularidad de entrada. BGE-M3 logra resultados de vanguardia en múltiples benchmarks, incluyendo MKQA y MLDR, superando consistentemente a modelos competidores tanto en escenarios de recuperación monolingüe como multilingüe.
- Multi-funcionalidad: BGE-M3 integra sin problemas tres estrategias de recuperación dentro de una arquitectura unificada:
- Recuperación densa – Genera una representación vectorial única por entrada, ideal para emparejamiento semántico general.
- Recuperación dispersa – Enfatiza la importancia a nivel de token, similar al emparejamiento léxico tradicional.
- Recuperación multi-vector – Produce múltiples vectores por entrada para capturar semántica fina y aumentar la precisión de recuperación.
- Multilingüe: Soporta más de 100 idiomas, permitiendo capacidades de recuperación tanto multilingüe como interlingüe.
- Multi-granularidad: Diseñado para manejar una amplia gama de longitudes de entrada —desde frases cortas hasta documentos extensos— soportando hasta 8192 tokens por entrada.
Cómo acceder a los modelos gratuitos en Novita AI
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Settings”, donde podrás copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API utilizando el administrador de paquetes específico para tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "model name"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Ya sea que estés construyendo un chatbot inteligente, un motor de búsqueda semántico o un sistema de recomendación multilingüe, el acceso gratuito a los modelos de Novita AI te ofrece todo lo que necesitas para empezar rápidamente. Con un rendimiento de clase mundial y una fácil integración API, estos modelos hacen que la IA escalable sea más accesible que nunca.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



