

Чтобы поддержать сообщество открытого ИИ и ускорить инновации в обработке естественного языка, Novita AI сделала пять мощных моделей свободно доступными через API. Среди них компактная, но способная Llama 3.2 1B Instruct, универсальная Qwen2.5-7B Instruct, высокопроизводительные GLM-4-9B-0414 и GLM-Z1-9B-0414, а также многоязычная и многофункциональная модель эмбеддингов BGE-M3. Предоставляя открытый доступ к этим моделям, Novita AI стремится дать разработчикам, исследователям и стартапам возможность создавать, тестировать и масштабировать AI-приложения более эффективно — без бремени высоких инфраструктурных затрат.
Llama 3.2 1b instruct
Попробовать Llama 3.2 1B сейчас!
- Размер модели: 1.23B параметров
- Архитектура: Оптимизированный Transformer с Grouped-Query Attention (GQA), активацией SwiGLU, ротационными позиционными эмбеддингами (RoPE) и RMSNorm
- Длина контекста: 128K токенов
- Многоязычность: Официально поддерживает английский, немецкий, французский, итальянский, португальский, хинди, испанский и тайский; обучена на более широком наборе языков
- Модальность: Текст-текст (ввод и вывод)
- Обучающие данные: Обучена на до 9 триллионов токенов из общедоступных онлайн-данных
- Открытый исходный код: ✅
- Бенчмарк: Демонстрирует высокую производительность в задачах следования инструкциям, суммаризации, переписывания подсказок и использования инструментов; конкурентоспособна с другими моделями своего класса по параметрам
Qwen2.5-7b-instruct
Попробовать Qwen 2.5 7B сейчас!
Qwen 2.5 7B — это многоязычная модель трансформера с открытым исходным кодом, показывающая высокую производительность в общих, математических, программных и многоязычных задачах. Она создана для универсальности, легкого развертывания и широкой языковой поддержки.
- Размер модели: 7.61B параметров
- Архитектура: Transformer с RoPE, SwiGLU, RMSNorm и смещением Attention QKV
- Длина контекста: 128K токенов
- Многоязычность: Поддерживает более 29 языков
- Модальность: Текст-текст
- Обучающие данные: Обучена на 18T+ токенов
- Открытый исходный код: ✅
- Бенчмарк: Qwen 2.5 7B стабильно занимает #1 место во всех категориях в этом наборе бенчмарков — общие задачи, STEM, программирование и многоязычное понимание — несмотря на относительно компактное количество параметров.
GLM-4-9b-0414 и GLM-Z1-9b-0414
Попробовать GLM-4 9B-0414 сейчас!
GLM-4-9B-0414 и GLM-Z1-9B-0414 — это две модели с открытым исходным кодом на 9 миллиардов параметров, разработанные THUDM, каждая оптимизирована для различных задач.
- GLM-4-9B-0414: Предназначена для генерации диалогов, наследует архитектуру GLM-4-32B и превосходно справляется с задачами многопоточных разговоров, перевода и суммаризации. Поддерживает окно контекста в 32K токенов и подходит для развертывания в условиях ограниченных ресурсов, требующих надежного понимания и генерации языка.
- GLM-Z1-9B-0414: Сосредоточена на математических рассуждениях и общих задачах, использует такие техники, как расширенное обучение с подкреплением и парное ранжирование. Демонстрирует высокую производительность в математике, коде и логических задачах, превосходя многие открытые модели своего класса.
| Характеристика | Значение |
|---|---|
| Размер модели | 9B параметров |
| Сильные стороны | - GLM-4-9B-0414: Высокое соотношение производительности к размеру, превосходна в математике и рассуждениях - GLM-Z1-9B-0414: Высокая производительность в математике и общих задачах |
| Направленность задач | - GLM-4-9B-0414: Ориентирована на чат - GLM-Z1-9B-0414: Ориентирована на рассуждения |
| Модальности | Текст-текст с поддержкой визуализации HTML/SVG |
| Окно контекста | 32K токенов |
| Обучение и выравнивание | Дистиллирована из GLM-4-32B. Базовая модель предварительно обучена на 15 триллионах токенов высококачественных данных (особенно синтетических данных для рассуждений) и выровнена с помощью настройки предпочтений человека для диалоговых задач. |
bge-m3
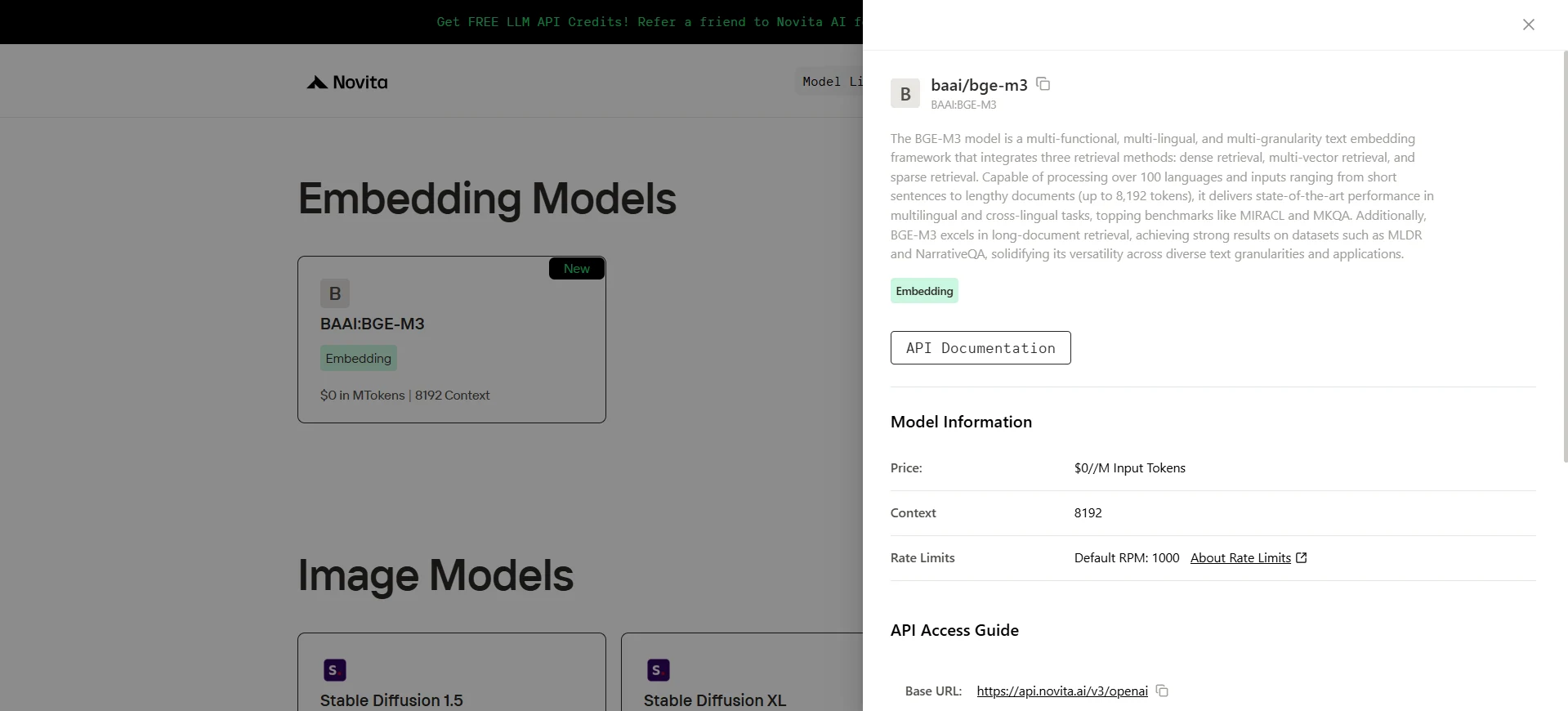
BGE-M3 — это передовая модель текстовых эмбеддингов, разработанная Пекинской академией искусственного интеллекта (BAAI). Она создана для исключительной универсальности, обеспечивая высокую производительность по трем основным направлениям: функциональность, языковая поддержка и гранулярность ввода. BGE-M3 достигает передовых результатов на нескольких бенчмарках, включая MKQA и MLDR, стабильно превосходя конкурирующие модели как в одноязычных, так и в кросс-языковых сценариях поиска.
- Многофункциональность: BGE-M3 бесшовно интегрирует три стратегии поиска в единой архитектуре:
- Плотный поиск (Dense Retrieval) – генерирует одно векторное представление на ввод, идеально подходит для общего семантического сопоставления.
- Разреженный поиск (Sparse Retrieval) – подчеркивает важность на уровне токенов, аналогично традиционному лексическому сопоставлению.
- Многовекторный поиск (Multi-Vector Retrieval) – создает несколько векторов на ввод для захвата мелкозернистой семантики и повышения точности поиска.
- Многоязычность: Поддерживает более 100 языков, обеспечивая как многоязычный, так и кросс-языковой поиск.
- Мультигранулярность: Предназначена для работы с широким диапазоном длины входных данных — от коротких фраз до длинных документов, поддерживая до 8192 токенов на ввод.
Как получить доступ к бесплатной модели на Novita AI?
Шаг 1: Войдите в систему и откройте библиотеку моделей
Войдите в свою учетную запись и нажмите кнопку Model Library.

Шаг 2: Выберите свою модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Шаг 3: Начните бесплатную пробную версию
Начните бесплатную пробную версию, чтобы изучить возможности выбранной модели.
Шаг 4: Получите свой API-ключ
Для аутентификации с помощью API мы предоставим вам новый API-ключ. Перейдите на страницу «Настройки», где вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с помощью вашего API-ключа, чтобы начать взаимодействие с Novita AI LLM. Это пример использования chat completions API для пользователей Python.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "model name"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Создаете ли вы интеллектуальный чат-бот, систему семантического поиска или многоязычную рекомендательную систему, бесплатный доступ к моделям Novita AI предоставляет все необходимое для быстрого старта. Благодаря производительности мирового уровня и простой интеграции API, эти модели делают масштабируемый ИИ более доступным, чем когда-либо.
Novita AI — это облачная платформа ИИ, которая предоставляет разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предлагает доступный и надежный облачный GPU для создания и масштабирования.



