

为了支持开源 AI 社区并加速自然语言处理领域的创新,Novita AI 已通过 API 免费开放了五款强大模型。其中包括轻巧但能力不弱的 Llama 3.2 1B Instruct、多功能的 Qwen2.5-7B Instruct、高性能的 GLM-4-9B-0414 和 GLM-Z1-9B-0414,以及多语言多功能的嵌入模型 BGE-M3。通过开放这些模型,Novita AI 旨在帮助开发者、研究人员和初创公司更高效地构建、测试和扩展 AI 应用——无需承担高昂的基础设施成本。
Llama 3.2 1b instruct
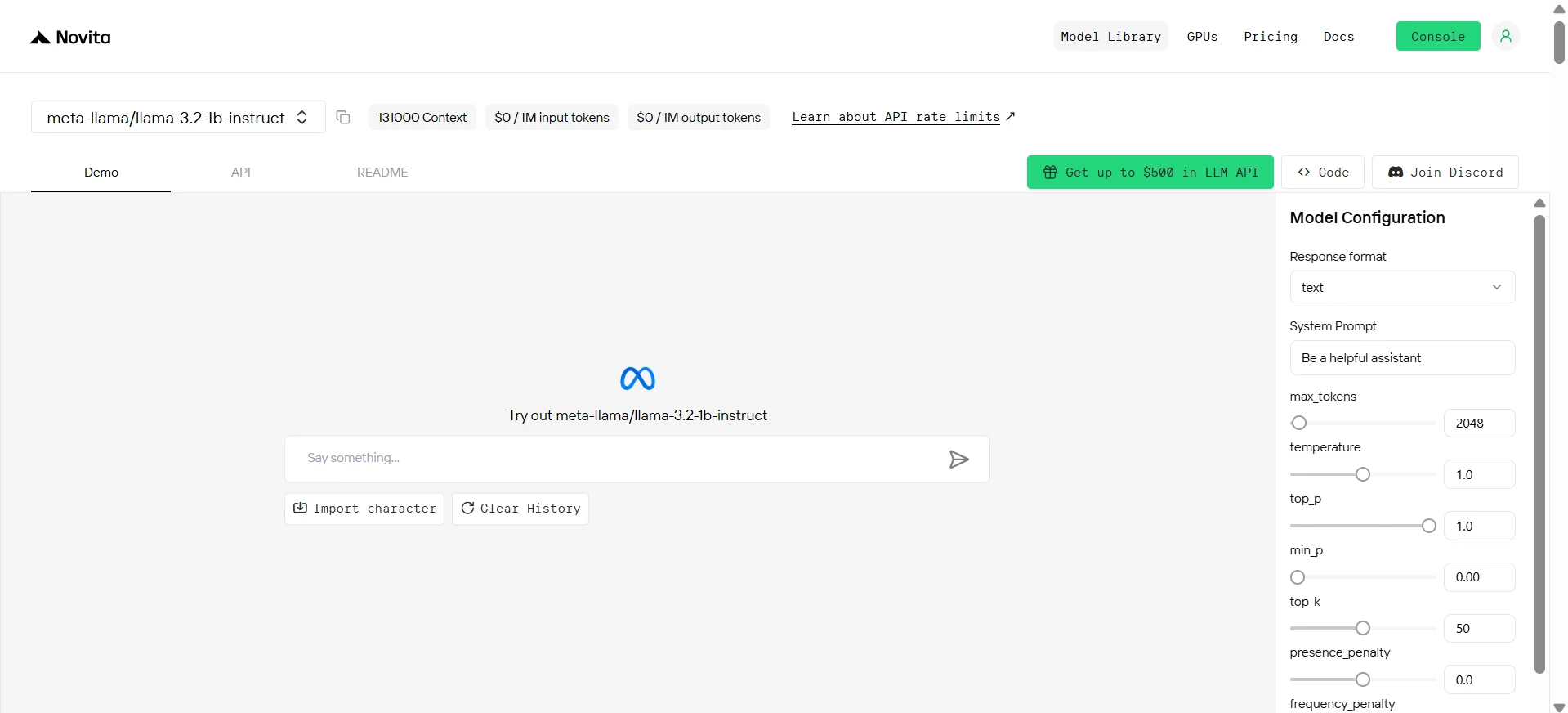
- 模型大小:1.23B 参数
- 架构:优化的 Transformer,采用分组查询注意力(GQA)、SwiGLU 激活、旋转位置嵌入(RoPE)和 RMSNorm
- 上下文长度:128K 词元
- 多语言:官方支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语;训练数据涵盖更广泛的语言集合
- 模态:文本到文本(输入和输出)
- 训练数据:基于公开在线数据,最多训练 9 万亿词元
- 开源:✅
- 基准测试:在指令遵循、摘要、提示重写和工具使用等任务中表现出色;与同类参数规模的模型相比具有竞争力
Qwen2.5-7b-instruct
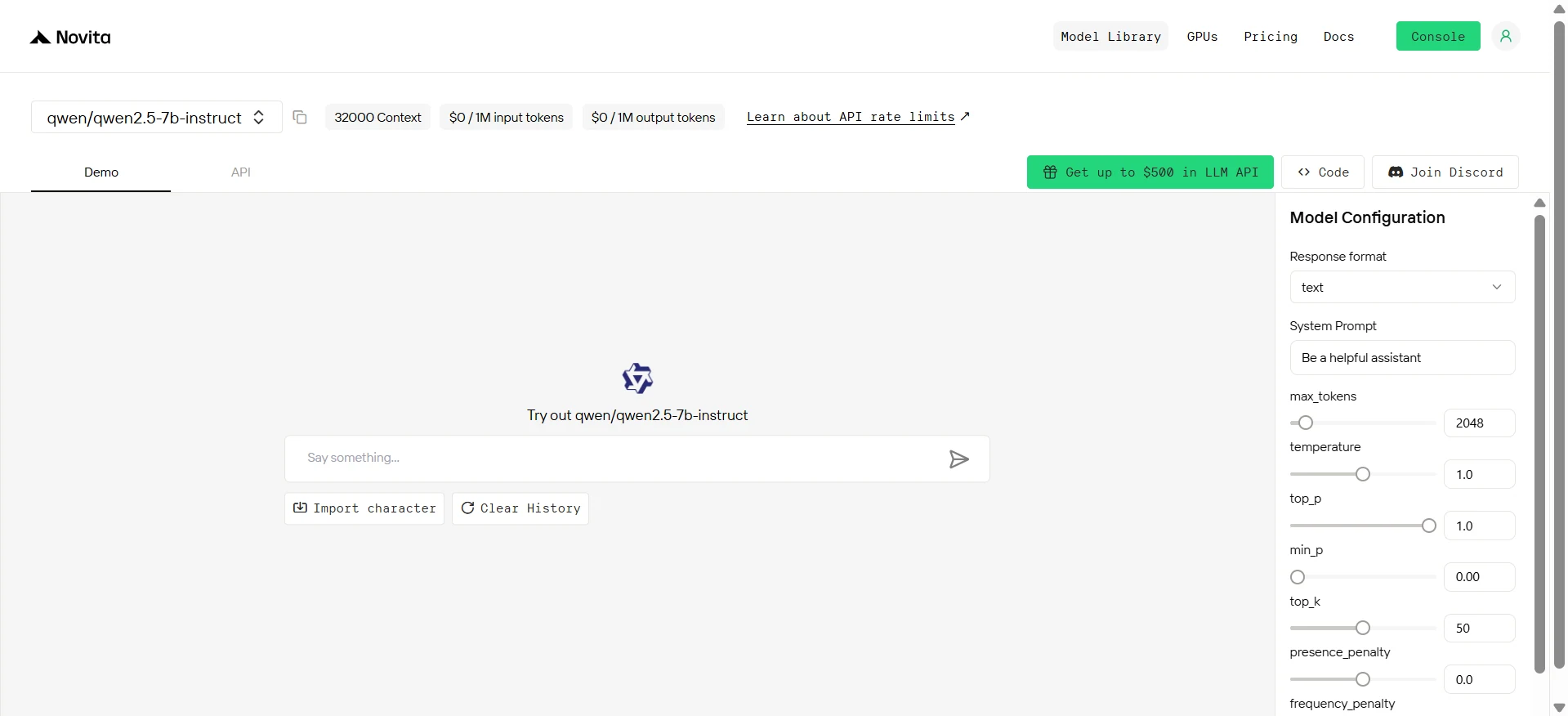
Qwen 2.5 7B 是一款多语言开源 Transformer 模型,在通用、数学、编程和多语言任务中表现强劲。它专为多功能、轻量级部署和广泛语言支持而构建。
- 模型大小:7.61B 参数
- 架构:Transformer,采用 RoPE、SwiGLU、RMSNorm 和 Attention QKV 偏置
- 上下文长度:128K 词元
- 多语言:支持超过 29 种语言
- 模态:文本到文本
- 训练数据:基于 18T+ 词元训练
- 开源:✅
- 基准测试:Qwen 2.5 7B 在该基准测试套件的 ** 所有类别(通用任务、STEM、编程和多语言理解)中持续排名第一**,尽管参数数量相对紧凑。
GLM-4-9b-0414 和 GLM-Z1-9b-0414
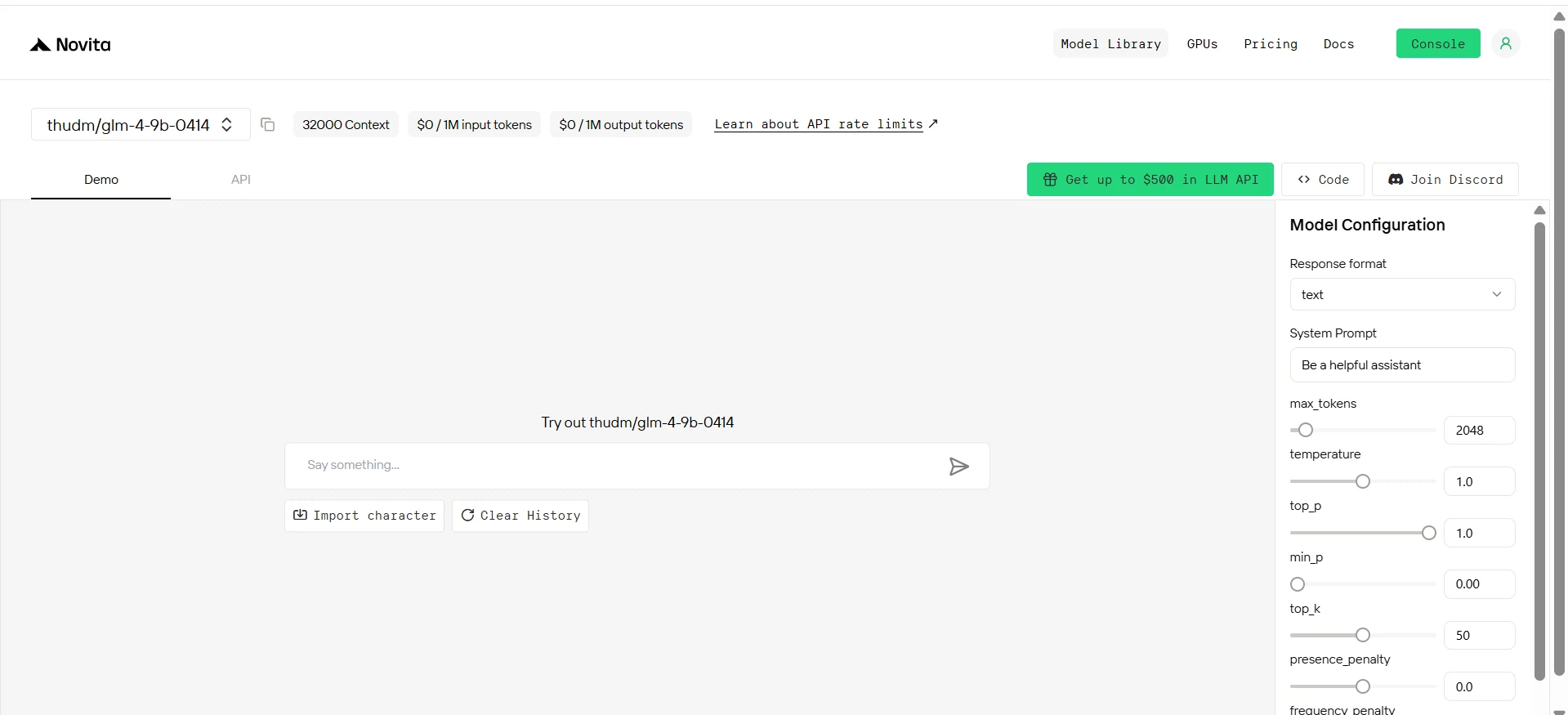
GLM-4-9B-0414 和 GLM-Z1-9B-0414 是 THUDM 开发的两款 90 亿参数的开源语言模型,分别针对不同任务进行了优化。
- GLM-4-9B-0414:专为对话生成而设计,继承了 GLM-4-32B 的架构,在多轮对话、翻译和摘要等任务中表现出色。支持 32K 上下文窗口,适合资源受限部署中需要强大语言理解和生成能力的场景。
- GLM-Z1-9B-0414:专注于数学推理和通用任务,采用了扩展强化学习和成对排序对齐等技术。在数学、代码和逻辑任务中表现强劲,超越了许多同重量级的开源模型。
| 特性 | 值 |
|---|---|
| 模型大小 | 9B 参数 |
| **优势 ** | - GLM-4-9B-0414:性能/大小比高,擅长数学与推理 - GLM-Z1-9B-0414:在数学和通用任务中表现强劲 |
| **任务导向 ** | - GLM-4-9B-0414:对话导向 - GLM-Z1-9B-0414:推理导向 |
| 模态 | 文本到文本,支持 HTML/SVG 可视化 |
| 上下文窗口 | 32K 词元 |
| 训练与对齐 | 从 GLM-4-32B 蒸馏而来。基础模型在 15 万亿词元的高质量数据(尤其是合成推理数据)上进行预训练,并通过人类偏好调优进行对话任务对齐。 |
bge-m3
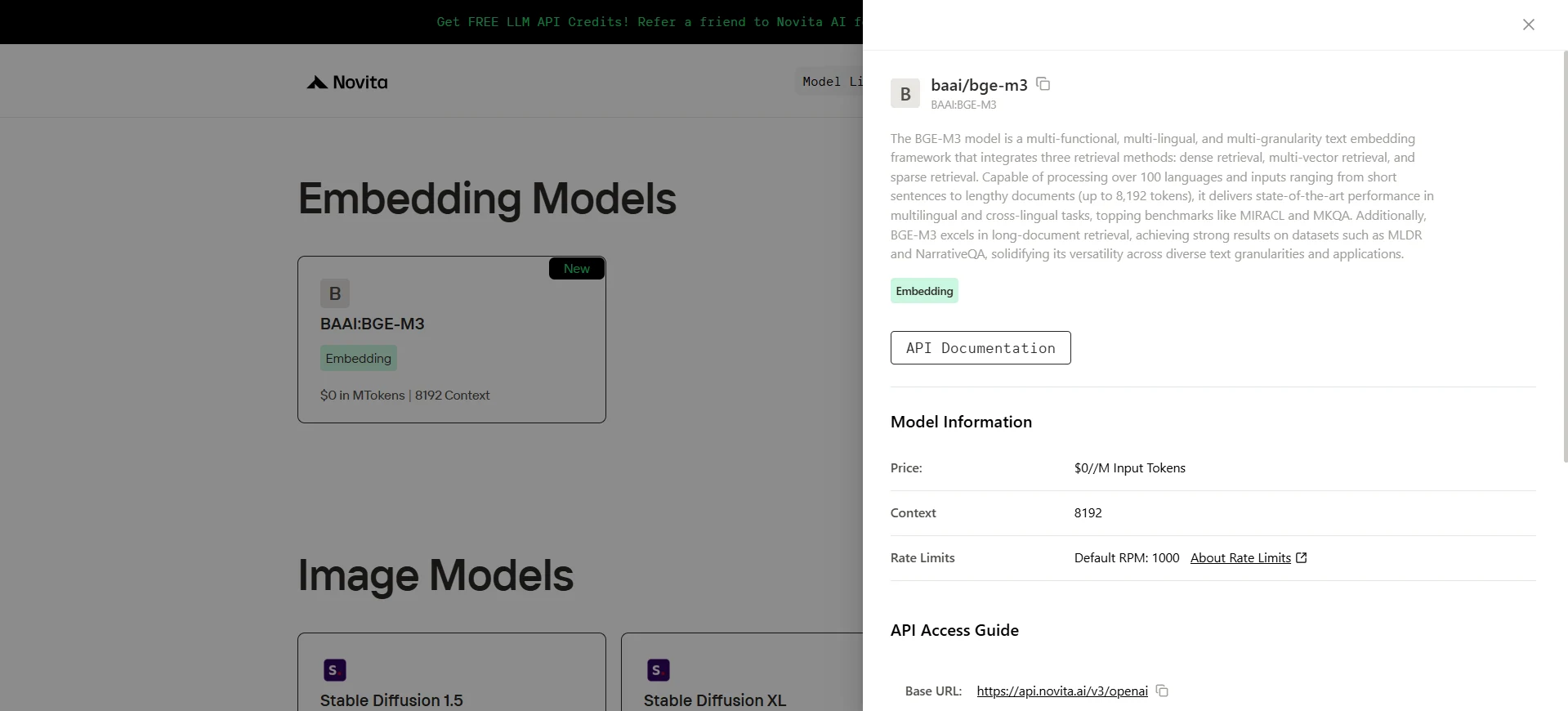
BGE-M3 是由 ** 北京智源人工智能研究院(BAAI)** 开发的一款前沿文本嵌入模型。它专为卓越的多功能性而设计,在 ** 功能**、** 语言支持 和 输入粒度 三个核心维度上表现出色。BGE-M3 在 MKQA 和 MLDR 等多个基准测试中达到了 ** 最先进水平,在 ** 单语和 ** 跨语言检索场景中持续优于竞争模型。
- 多功能:BGE-M3 在统一架构中无缝集成了三种检索策略:
- 稠密检索 – 为每个输入生成单个向量表示,适用于通用语义匹配。
- 稀疏检索 – 强调词元级别的重要性,类似于传统的词法匹配。
- 多向量检索 – 为每个输入生成多个向量,以捕获细粒度语义并提高检索精度。
- **多语言 **:支持超过 100 种语言,具备多语言和跨语言检索能力。
- **多粒度 **:设计用于处理从短短语到长文档的多种输入长度,每个输入最多支持 8192 个词元。
如何在 Novita AI 上访问免费模型?
第 1 步:登录并访问模型库
登录您的账户,点击 模型库 按钮。

第 2 步:选择您的模型
浏览可用选项,选择适合您需求的模型。

第 3 步:开始免费试用
开始免费试用,探索所选模型的功能。
第 4 步:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新 API 密钥。进入“设置”页面,您可以按照图片所示复制 API 密钥。

第 5 步:安装 API
使用您编程语言对应的包管理器安装 API。
安装后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是为 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "model name"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
无论您是在构建智能聊天机器人、语义搜索引擎还是多语言推荐系统,免费访问 Novita AI 的模型 都能为您提供快速上手所需的一切。凭借世界一流的性能和简单的 API 集成,这些模型使可扩展的 AI 比以往任何时候都更容易获得。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时还提供经济实惠且可靠的 GPU 云用于构建和扩展。



