

Para apoiar a comunidade de IA de código aberto e acelerar a inovação em processamento de linguagem natural, a Novita AI disponibilizou gratuitamente cinco modelos poderosos via API. Eles incluem o compacto e capaz Llama 3.2 1B Instruct, o versátil Qwen2.5-7B Instruct, os de alto desempenho GLM-4-9B-0414 e GLM-Z1-9B-0414, além do modelo de embeddings multilíngue e multifuncional BGE-M3. Ao oferecer acesso aberto a esses modelos, a Novita AI busca capacitar desenvolvedores, pesquisadores e startups a construir, testar e escalar aplicações de IA de forma mais eficiente — sem o peso de altos custos de infraestrutura.
Llama 3.2 1b instruct
Experimente o Llama 3.2 1B agora!
- Tamanho do modelo: 1,23B parâmetros
- Arquitetura: Transformer otimizado com Grouped-Query Attention (GQA), ativação SwiGLU, Embeddings Posicionais Rotativos (RoPE) e RMSNorm
- Comprimento do contexto: 128 mil tokens
- Multilíngue: Suporta oficialmente inglês, alemão, francês, italiano, português, hindi, espanhol e tailandês; treinado em um conjunto mais amplo de idiomas
- Modalidade: Texto para texto (entrada e saída)
- Dados de treinamento: Treinado em até 9 trilhões de tokens de dados online publicamente disponíveis
- Código aberto: ✅
- Benchmark: Demonstra forte desempenho em tarefas como seguir instruções, sumarização, reescrita de prompts e uso de ferramentas; competitivo com outros modelos de sua classe de parâmetros
Qwen2.5-7b-instruct
Experimente o Qwen 2.5 7B agora!
Qwen 2.5 7B é um modelo transformer multilíngue de código aberto com forte desempenho em tarefas gerais, matemáticas, de codificação e multilíngues. Ele é construído para versatilidade, implantação leve e amplo suporte a idiomas.
- Tamanho do modelo: 7,61B parâmetros
- Arquitetura: Transformer com RoPE, SwiGLU, RMSNorm e Attention QKV bias
- Comprimento do contexto: 128 mil tokens
- Multilíngue: Suporta mais de 29 idiomas
- Modalidade: Texto para texto
- Dados de treinamento: Treinado em 18T+ tokens
- Código aberto: ✅
- Benchmark: Qwen 2.5 7B classifica-se consistentemente em #1 em todas as categorias neste conjunto de benchmarks — tarefas gerais, STEM, codificação e compreensão multilíngue — apesar de ter um número de parâmetros relativamente compacto.
GLM-4-9b-0414 e GLM-Z1-9b-0414
Experimente o GLM-4 9B-0414 agora!
O GLM-4-9B-0414 e o GLM-Z1-9B-0414 são dois modelos de linguagem de código aberto com 9 bilhões de parâmetros desenvolvidos pela THUDM, cada um otimizado para tarefas distintas.
- GLM-4-9B-0414: Projetado para geração de diálogo, este modelo herda a arquitetura do GLM-4-32B e se destaca em tarefas como conversas de múltiplas etapas, tradução e sumarização. Suporta uma janela de contexto de 32 mil tokens e é adequado para implantações com recursos limitados que exigem robustas capacidades de compreensão e geração de linguagem.
- GLM-Z1-9B-0414: Focado em raciocínio matemático e tarefas gerais, este modelo incorpora técnicas como aprendizado por reforço estendido e alinhamento de pares por classificação. Demonstra forte desempenho em matemática, código e tarefas de lógica, superando muitos modelos de código aberto em sua classe de peso.
| Característica | Valor |
|---|---|
| Tamanho do modelo | 9B parâmetros |
| Pontos fortes | - GLM-4-9B-0414: Alta relação desempenho-tamanho, destaca-se em Matemática e Raciocínio - GLM-Z1-9B-0414: Forte desempenho em Matemática e Tarefas Gerais |
| Orientação de tarefa | - GLM-4-9B-0414: Orientado a chat - GLM-Z1-9B-0414: Focado em raciocínio |
| Modalidades | Texto para texto com suporte a visualização HTML/SVG |
| Janela de contexto | 32 mil tokens |
| Treinamento e alinhamento | Destilado do GLM-4-32B. O modelo base foi pré-treinado em 15 trilhões de tokens de dados de alta qualidade (especialmente dados de raciocínio sintético) e alinhado por meio de ajuste de preferência humana para tarefas de diálogo. |
bge-m3
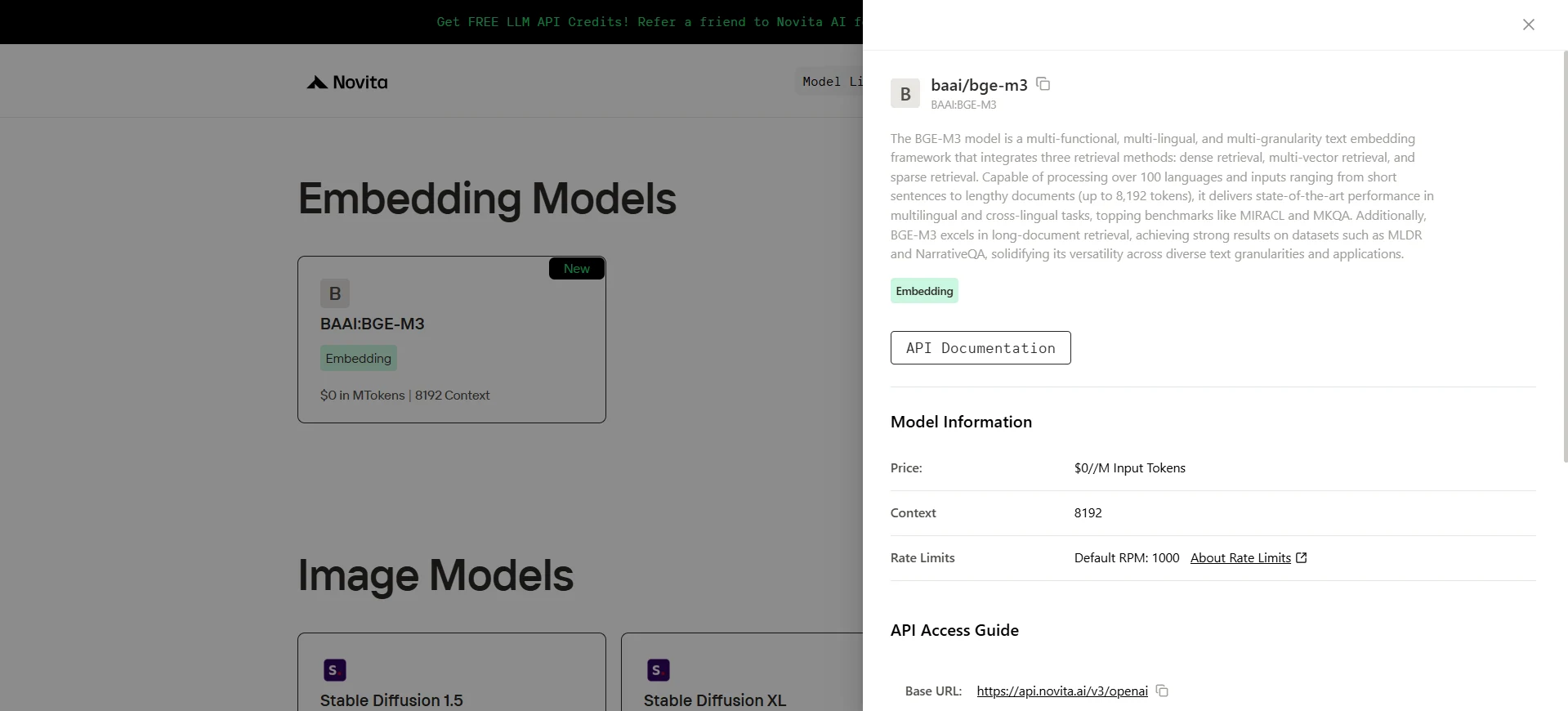
BGE-M3 é um modelo de embeddings de texto de ponta desenvolvido pela Academia de Inteligência Artificial de Pequim (BAAI). Ele é projetado para versatilidade excepcional, oferecendo forte desempenho em três dimensões principais: funcionalidade, suporte a idiomas e granularidade de entrada. O BGE-M3 alcança resultados de ponta em vários benchmarks, incluindo MKQA e MLDR, superando consistentemente modelos concorrentes em cenários de recuperação monolíngue e cross-lingual.
- Multifuncionalidade: O BGE-M3 integra perfeitamente três estratégias de recuperação em uma arquitetura unificada:
- Recuperação densa – Gera uma única representação vetorial por entrada, ideal para correspondência semântica geral.
- Recuperação esparsa – Enfatiza a importância no nível do token, semelhante à correspondência lexical tradicional.
- Recuperação multi-vetor – Produz múltiplos vetores por entrada para capturar semântica refinada e aumentar a precisão da recuperação.
- Multilinguismo: Suporta mais de 100 idiomas, permitindo capacidades de recuperação multilíngue e cross-lingual.
- Multigranularidade: Projetado para lidar com uma ampla gama de comprimentos de entrada — desde frases curtas até documentos longos — suportando até 8192 tokens por entrada.
Como acessar modelos gratuitos na Novita AI?
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu teste gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "model name"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Esteja você construindo um chatbot inteligente, um mecanismo de busca semântica ou um sistema de recomendação multilíngue, o acesso gratuito aos modelos da Novita AI oferece tudo o que você precisa para começar rapidamente. Com desempenho de classe mundial e fácil integração via API, esses modelos tornam a IA escalável mais acessível do que nunca.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer GPU em nuvem acessível e confiável para construir e escalar.



