

Points clés
Différence architecturale : La conception Mixture-of-Experts (MoE) de DeepSeek R1 optimise les performances pour les tâches logiques lourdes, tandis que l’architecture propriétaire de Claude 3.5 privilégie la polyvalence et les capacités multilingues.
Spécialisation des tâches : DeepSeek R1 excelle en programmation (96,3 % Codeforces) et en mathématiques (79,8 % AIME), alors que Claude 3.5 brille en compréhension multilingue, en raisonnement visuel et dans des contextes conversationnels plus larges.
Rapport coût-efficacité vs rapidité : DeepSeek R1 est plus économique et open source, idéal pour les développeurs ayant besoin de personnalisation. Claude 3.5 fournit des sorties plus rapides mais à un coût plus élevé. Et Novita AI lance une version Turbo avec un débit 3x supérieur et une réduction de 60 % à durée limitée !
Claude 3.5 Sonnet d’Anthropic et DeepSeek R1 sont devenus des acteurs clés dans le domaine en évolution rapide de l’intelligence artificielle. Publiés à des moments différents, ces deux modèles démontrent des capacités avancées et ont attiré une attention considérable pour leurs fonctionnalités uniques et leurs attributs de performance.
DeepSeek R1 vs Claude 3.5 : Introduction de base
| Fonctionnalité | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|
| Date de sortie | 20 janvier 2025 | 22 octobre 2024 |
| Taille du modèle | 671 milliards de paramètres (total), 37 milliards activés par token | Environ 100 milliards de paramètres |
| Langues supportées | Principalement le chinois et l’anglais | Multilingue |
| Architecture du modèle | Mixture-of-Experts (MoE), entraîné par apprentissage par renforcement à grande échelle avec un minimum d’apprentissage supervisé fin | Propriétaire |
| Fenêtre de contexte | 128k tokens | 200k tokens |
| Précision de quantification | BF16, F8_E4M3, F32 (selon Hugging Face) | Non spécifié explicitement dans les sources |
| Open Source | Oui | Non |
| Développeur | DeepSeek | Anthropic |
| Capacité multimodale | Texte uniquement | Prend en charge l’interprétation de graphiques et d’illustrations |
Deepseek R1
- DeepSeek R1 est spécialement conçu pour les tâches qui exigent un raisonnement avancé et une assistance en programmation. Il utilise une architecture Mixture-of-Experts (MoE), n’activant qu’un sous-ensemble de ses vastes paramètres pour chaque token, optimisant ainsi l’efficacité computationnelle. Entraîné par apprentissage par renforcement à grande échelle (RL) avec un minimum d’apprentissage supervisé fin (SFT), DeepSeek R1 met fortement l’accent sur la logique et les capacités de résolution de problèmes.
Claude 3.5 Sonnet
- Claude 3.5 Sonnet, le modèle le plus avancé d’Anthropic, combine des performances exceptionnelles avec une vitesse accrue. Il dispose d’une grande fenêtre de contexte et excelle dans la compréhension d’instructions nuancées et complexes. Faisant partie de la famille de modèles Claude 3.5, il apporte des améliorations significatives par rapport à ses prédécesseurs, notamment dans des domaines tels que le codage et l’utilisation d’outils.
Vous pouvez démarrer un essai gratuit sur Novita AI pour la série Deepseek R1 !
DeepSeek R1 vs Claude 3.5 : Benchmark
| Benchmark | Description | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|---|
| Codeforces (Percentile) | Percentile de résolution de problèmes de programmation. | 96,3 % | 20,3 % |
| Codeforces (Rating) | Classement en concours de programmation. | 2029 | 717 |
| SWE Verified (Résolus) | Problèmes de génie logiciel résolus. | 49,2 % | 50,8 % |
| LiveCodeBench (Pass@1-COT) | Succès en codage avec raisonnement par chaîne de pensée. | 65,9 % | 33,8 % |
| AIME 2024 (Pass@1) | Résolution avancée de problèmes mathématiques. | 79,8 % | 16,0 % |
| MMLU-Pro (EM) | Précision sur des tâches de niveau professionnel. | 84,0 % | 78,0 % |
| GPQA-Diamond (Pass@1) | Réponse à des questions à usage général. | 71,5 % | 65,0 % |
| AlpacaEval2.0 (LC-winrate) | Tâches de compréhension linguistique et de conversation. | 87,6 % | 52,0 % |
| ArenaHard (GPT-4-1106) | Tâches de raisonnement difficile vs GPT-4. | 92,3 % | 85,2 % |
| Précision de débogage | Identification et correction de bugs dans le code. | 90 % | 75 % |
Deepseek R1
DeepSeek R1 excelle en programmation, débogage et raisonnement mathématique avancé, ce qui le rend idéal pour les tâches techniques et logiques lourdes. Ses performances solides dans les benchmarks comme Codeforces, AIME et la précision de débogage mettent en évidence ses capacités dans ces domaines.
Claude 3.5 Sonnet
Claude 3.5 Sonnet, bien que plus faible en programmation et en mathématiques, performe bien en compréhension linguistique et en tâches de connaissances générales, ce qui le rend mieux adapté aux applications multilingues et conversationnelles.
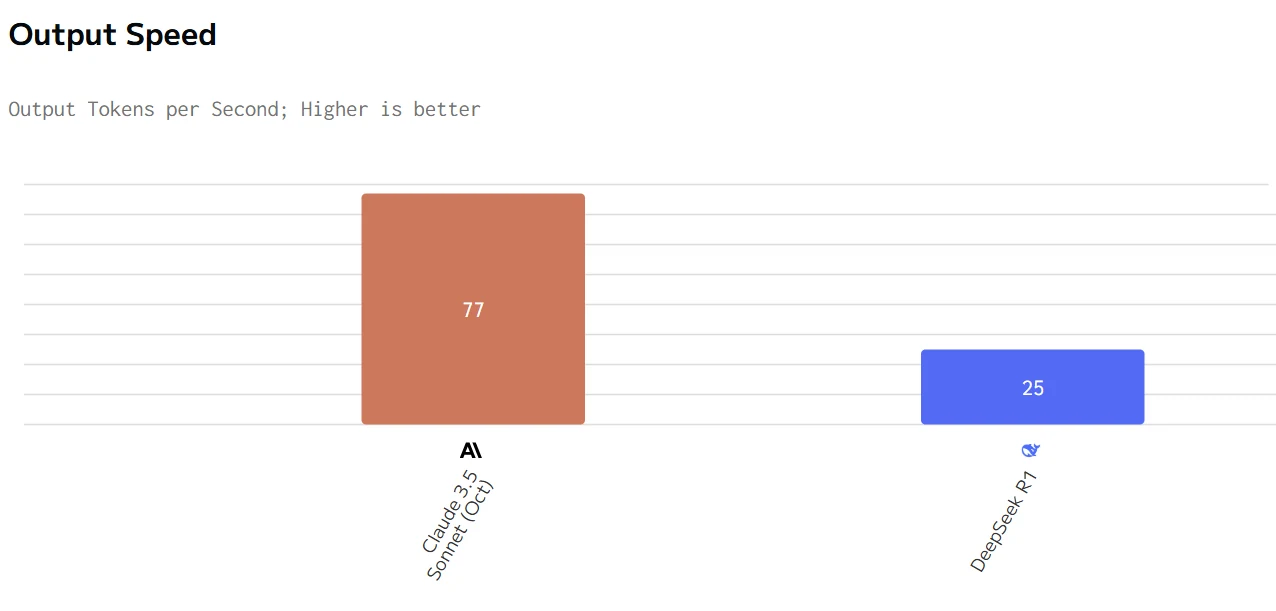
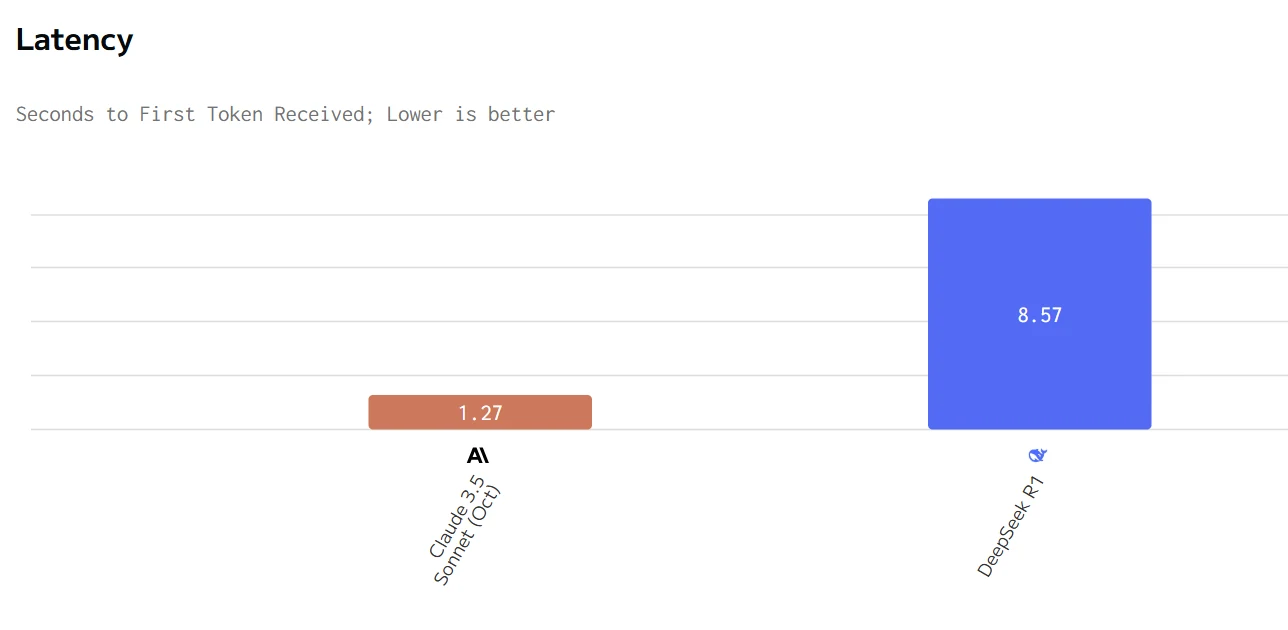
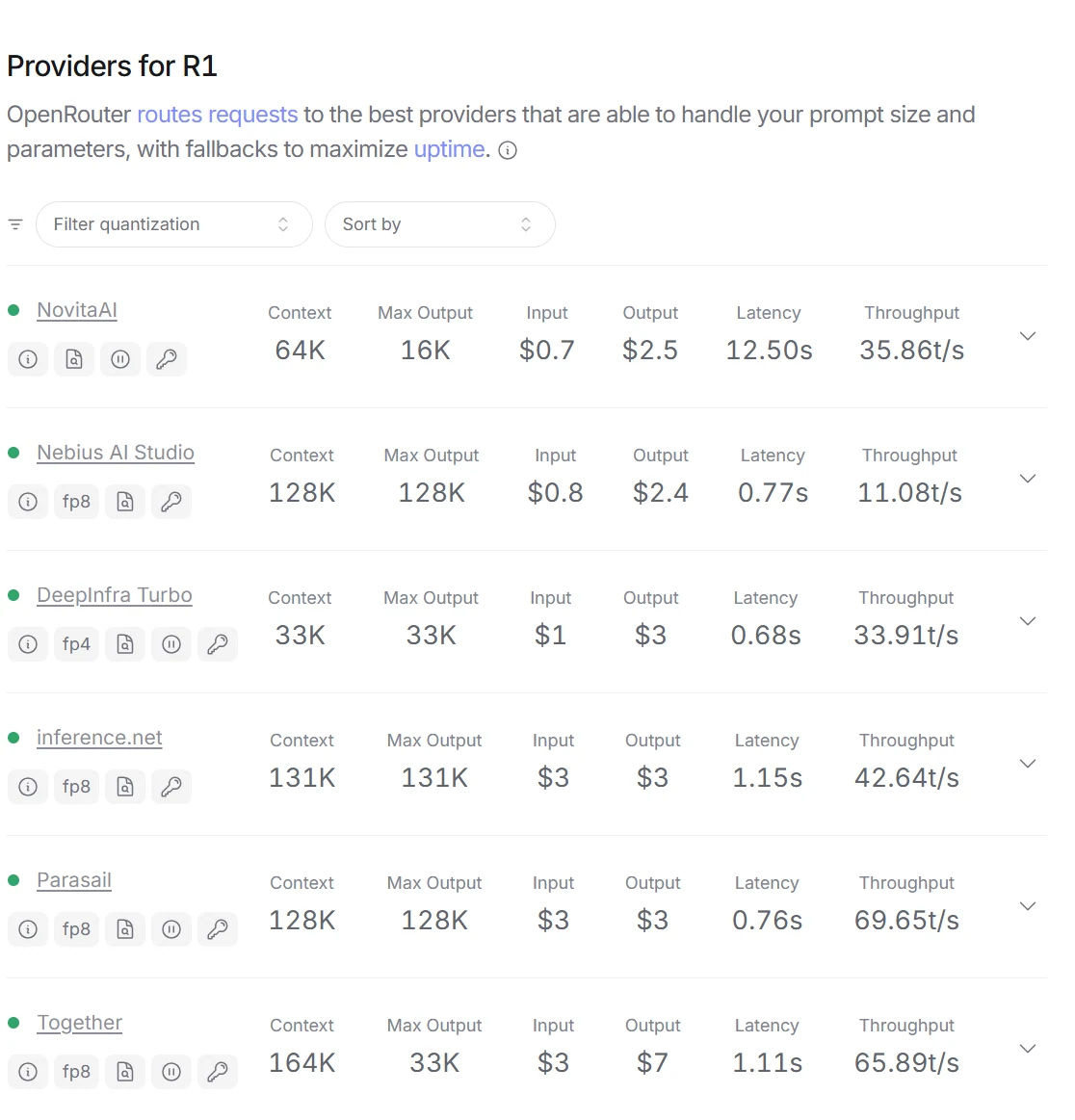
DeepSeek R1 vs Claude 3.5 : Vitesse et coût
Comparaison de vitesse entre Deepseek R1 et Claude 3.5
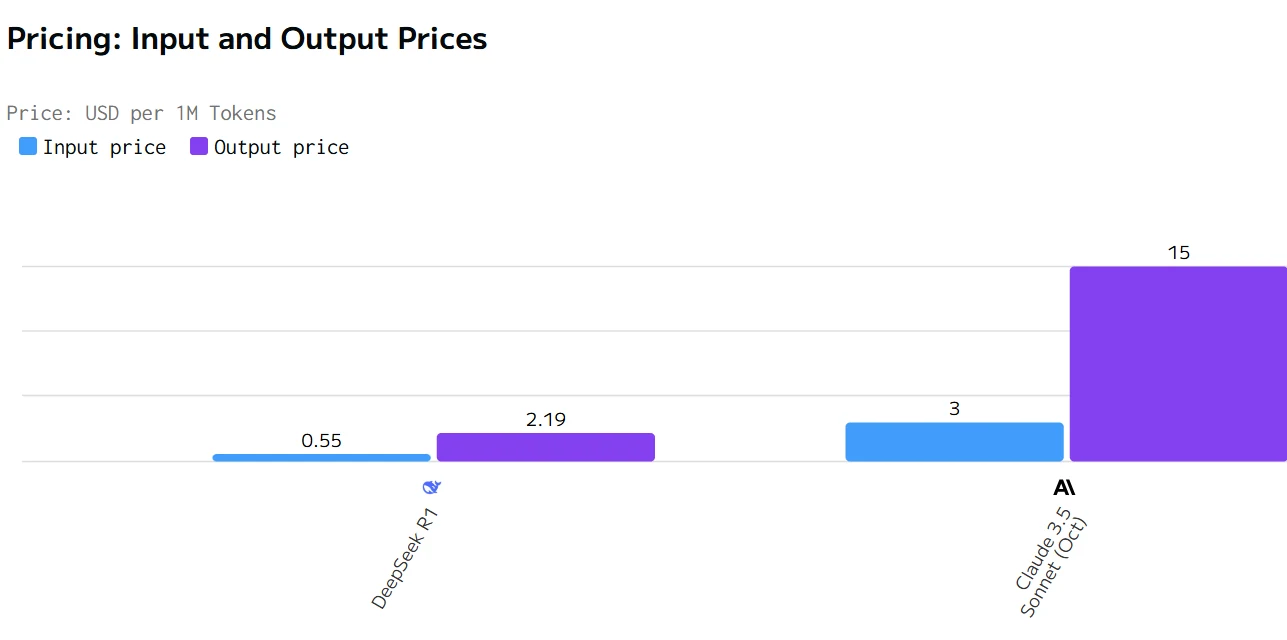
Comparaison des coûts entre Deepseek R1 et Claude 3.5
Les données ci-dessus proviennent de artificial analysis
Claude offre des métriques de performance supérieures (vitesse de sortie plus rapide et latence plus faible) mais à un prix considérablement plus élevé. DeepSeek R1 est plus économique mais plus lent en réponse et en génération. Le choix entre eux dépend de si la vitesse et la réactivité ou le rapport coût-efficacité sont la priorité la plus élevée pour un cas d’utilisation spécifique.
Cependant, Novita AI lance une version Turbo avec un débit 3x supérieur et une réduction de 60 % à durée limitée !
DeepSeek R1 Vs Claude 3.5 : Tâches
Tâche 1 : Raisonnement logique
Prompt : « Vous entrez dans une pièce et voyez un lit. Sur le lit, il y a deux chiens, quatre chats, une girafe, cinq vaches et un canard. Il y a aussi trois chaises et une table. Combien de jambes sont sur le sol ? »
Résultat Deepseek R1

Résultat Claude 3.5

Analyse :
- Profondeur de raisonnement : DeepSeek R1 démontre un processus de raisonnement plus profond et plus minutieux, prenant en compte tous les aspects du problème.
- Précision : DeepSeek R1 arrive finalement à la bonne réponse (22), tandis que Claude 3.5 conclut incorrectement à 20.
- Capacité d’auto-vérification : DeepSeek R1 examine et vérifie continuellement son raisonnement, alors que Claude 3.5 manque de ce mécanisme d’auto-vérification.
- Gestion des ambiguïtés : DeepSeek R1 parvient à traiter les ambiguïtés du problème (comme si le lit a des pieds), tandis que Claude 3.5 fait des hypothèses simples sans explication.
- Transparence de la pensée : Le processus de réflexion de DeepSeek R1 est plus transparent, permettant de comprendre son cheminement de raisonnement.
Tâche 2 : Raisonnement scientifique
Prompt : « Vous avez un laser puissant et un miroir parfaitement réfléchissant. Comment pouvez-vous viser le laser sur le miroir de telle sorte que le faisceau réfléchi ne revienne jamais vers vous ? »
Résultat Deepseek R1

Résultat Claude 3.5

Analyse :
- DeepSeek R1 démontre un raisonnement scientifique nettement plus fort :
- Précision physique : La réponse de DeepSeek R1 est physiquement correcte et suit les principes optiques établis, tandis que la réponse de Claude 3.5 contient des idées fondamentalement erronées.
- Cohérence logique : DeepSeek R1 maintient une cohérence logique tout au long de son explication, tandis que la réponse de Claude 3.5 contient des contradictions internes.
- Résolution de problèmes : DeepSeek R1 résout correctement le problème en fournissant une gamme valide de solutions, tandis que Claude 3.5 propose une solution impossible.
- Culture scientifique : DeepSeek R1 démontre une compréhension correcte de la loi de la réflexion, tandis que Claude 3.5 semble confondre des concepts optiques de base.
Tâche 3 : Compétences en résolution de problèmes
Prompt : « Écrivez un programme capable de résoudre un puzzle Sudoku »
Résultat Deepseek R1
def find_empty(grid):
for row in range(9):
for col in range(9):
if grid[row][col] == 0:
return (row, col) # Return empty cell position
return None # No empty cells left
def is_valid(grid, num, pos):
row, col = pos
# Check row
for i in range(9):
if grid[row][i] == num and i != col:
return False
# Check column
for i in range(9):
if grid[i][col] == num and i != row:
return False
# Check 3x3 subgrid
start_row = (row // 3) * 3
start_col = (col // 3) * 3
for i in range(start_row, start_row + 3):
for j in range(start_col, start_col + 3):
if grid[i][j] == num and (i, j) != pos:
return False
return True
def solve(grid):
empty = find_empty(grid)
if not empty:
return True # Puzzle solved
row, col = empty
for num in range(1, 10):
if is_valid(grid, num, (row, col)):
grid[row][col] = num # Place number
if solve(grid):
return True # Continue solving
grid[row][col] = 0 # Backtrack if invalid
return False # Trigger backtracking
def print_grid(grid):
for row in grid:
print(row)
# Example Sudoku puzzle (0 represents empty cells)
grid = [
[5,3,0,0,7,0,0,0,0],
[6,0,0,1,9,5,0,0,0],
[0,9,8,0,0,0,0,6,0],
[8,0,0,0,6,0,0,0,3],
[4,0,0,8,0,3,0,0,1],
[7,0,0,0,2,0,0,0,6],
[0,6,0,0,0,0,2,8,0],
[0,0,0,4,1,9,0,0,5],
[0,0,0,0,8,0,0,7,9]
]
if solve(grid):
print("Solved Sudoku:")
print_grid(grid)
else:
print("No solution exists")
Résultat Claude 3.5
def print_board(board):
for i in range(9):
if i % 3 == 0 and i != 0:
print("- - - - - - - - - - - -")
for j in range(9):
if j % 3 == 0 and j != 0:
print("|", end=" ")
if j == 8:
print(board[i][j])
else:
print(str(board[i][j]) + " ", end="")
def find_empty(board):
for i in range(9):
for j in range(9):
if board[i][j] == 0:
return (i, j)
return None
def valid(board, num, pos):
# Check row
for j in range(9):
if board[pos[0]][j] == num and pos[1] != j:
return False
# Check column
for i in range(9):
if board[i][pos[1]] == num and pos[0] != i:
return False
# Check box
box_x = pos[1] // 3
box_y = pos[0] // 3
for i in range(box_y * 3, box_y * 3 + 3):
for j in range(box_x * 3, box_x * 3 + 3):
if board[i][j] == num and (i, j) != pos:
return False
return True
def solve(board):
empty = find_empty(board)
if not empty:
return True
row, col = empty
for num in range(1, 10):
if valid(board, num, (row, col)):
board[row][col] = num
if solve(board):
return True
board[row][col] = 0
return False
# Example puzzle (0 represents empty cells)
board = [
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
]
print("Original Sudoku:")
print_board(board)
print("\
Solving...\
")
if solve(board):
print("Solved Sudoku:")
print_board(board)
else:
print("No solution exists")
Analyse :
- Implémentation de l’algorithme : Les deux sont au même niveau, implémentant correctement l’algorithme de résolution du Sudoku.
- Lisibilité du code : Le code généré par Claude 3.5 est légèrement meilleur, notamment avec une fonctionnalité d’affichage plus conviviale.
- Expérience utilisateur : Claude 3.5 offre une expérience utilisateur plus complète, incluant des retours sur les étapes de traitement.
- Style de code : Les deux maintiennent un bon style de codage Python cohérent.
- Pratique : Le code généré par Claude 3.5 peut avoir un léger avantage en utilisation pratique grâce à son format de sortie plus clair.
Comment accéder à DeepSeek R1 via l’API ?
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen facile de déployer des modèles d’IA via notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez la démo DeepSeek R1 maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Settings », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 et Claude 3.5 Sonnet ont chacun des forces uniques. DeepSeek R1 excelle en mathématiques, codage et résolution logique de problèmes, offrant un bon rapport coût-efficacité et une personnalisation en tant que modèle open source—idéal pour les développeurs, chercheurs ou organisations soucieuses de leur budget.
Claude 3.5 Sonnet brille dans les tâches multilingues, la génération de code, le raisonnement visuel et la gestion de grandes fenêtres de contexte. Son intégration transparente via les API le rend polyvalent pour la recherche, la création de contenu et les chatbots avancés.
Le choix dépend des exigences de la tâche et des priorités de l’utilisateur, telles que le coût, l’expertise du domaine ou la facilité d’utilisation.
Questions fréquemment posées
Quel modèle est le plus rentable ?
DeepSeek R1 est nettement plus abordable que Claude 3.5 Sonnet, surtout pour les tokens d’entrée et de sortie. Par ailleurs, Novita AI propose DeepSeek R1 Turbo, une version optimisée de DeepSeek R1, offrant un débit 3x supérieur, un support complet des appels de fonction, et une réduction de 60 % à durée limitée !
Quelle est la taille de la fenêtre de contexte pour chaque modèle ?
DeepSeek R1 a une fenêtre de contexte de 128k tokens, tandis que Claude 3.5 Sonnet offre une fenêtre de contexte plus grande de 200k tokens.
DeepSeek R1 est-il open source ?
Oui, DeepSeek R1 est entièrement open source, permettant un hébergement local et une personnalisation.
Novita AI est la plateforme cloud tout-en-un qui propulse vos ambitions IA. API intégrées, sans serveur, Instance GPU—les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement, et faites de votre vision IA une réalité.



