

Aspectos destacados clave
Distinción arquitectónica: El diseño Mixture-of-Experts (MoE) de DeepSeek R1 optimiza el rendimiento para tareas de lógica intensiva, mientras que la arquitectura propietaria de Claude 3.5 prioriza la versatilidad y las capacidades multilingües.
Especialización de tareas: DeepSeek R1 sobresale en programación (96.3% en Codeforces) y matemáticas (79.8% AIME), mientras que Claude 3.5 destaca en comprensión multilingüe, razonamiento visual y contextos conversacionales más amplios.
Rentabilidad vs. Velocidad: DeepSeek R1 es más económico y de código abierto, ideal para desarrolladores que necesitan personalización. Claude 3.5 ofrece salidas más rápidas pero a un costo mayor. Y Novita AI lanza una versión Turbo con 3x el rendimiento y un descuento por tiempo limitado del 60%!
Claude 3.5 Sonnet de Anthropic y R1 de DeepSeek se han convertido en actores clave en el campo de la inteligencia artificial en rápida evolución. Lanzados en diferentes momentos, ambos modelos demuestran capacidades avanzadas y han ganado una atención significativa por sus características únicas y atributos de rendimiento.
DeepSeek R1 vs Claude 3.5: Introducción básica
| Característica | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|
| Fecha de lanzamiento | 20 de enero de 2025 | 22 de octubre de 2024 |
| Tamaño del modelo | 671 mil millones de parámetros (total), 37 mil millones activados por token | Aproximadamente 100 mil millones de parámetros |
| Idiomas compatibles | Principalmente chino e inglés | Multilingüe |
| Arquitectura del modelo | Mixture-of-Experts (MoE), entrenado mediante aprendizaje por refuerzo a gran escala con mínimo ajuste fino supervisado | Propietaria |
| Ventana de contexto | 128k tokens | 200k tokens |
| Precisión de cuantización | BF16, F8_E4M3, F32 (según Hugging Face) | No especificado explícitamente en las fuentes |
| Código abierto | Sí | No |
| Desarrollador | DeepSeek | Anthropic |
| Capacidad multimodal | Solo texto | Soporta interpretación de gráficos y diagramas |
Deepseek R1
- DeepSeek R1 está diseñado específicamente para tareas que requieren razonamiento avanzado y asistencia en programación. Aprovecha una arquitectura Mixture-of-Experts (MoE), activando solo un subconjunto de sus vastos parámetros por token, optimizando así la eficiencia computacional. Entrenado mediante aprendizaje por refuerzo (RL) a gran escala con un mínimo ajuste fino supervisado (SFT), DeepSeek R1 pone un fuerte énfasis en la lógica y las capacidades de resolución de problemas.
Claude 3.5 Sonnet
- Claude 3.5 Sonnet, el modelo más avanzado de Anthropic, combina un rendimiento excepcional con una velocidad mejorada. Cuenta con una gran ventana de contexto y destaca en la comprensión de instrucciones complejas y matizadas. Como parte de la familia de modelos Claude 3.5, ofrece mejoras significativas sobre sus predecesores, particularmente en áreas como codificación y uso de herramientas.
Puedes iniciar una prueba gratuita en Novita AI para la serie Deepseek R1.
DeepSeek R1 vs Claude 3.5: Benchmarks
| Benchmark | Descripción | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|---|
| Codeforces (Percentil) | Percentil de resolución de problemas de programación. | 96.3% | 20.3% |
| Codeforces (Puntuación) | Puntuación en concursos de programación. | 2029 | 717 |
| SWE Verificado (Resuelto) | Problemas de ingeniería de software resueltos. | 49.2% | 50.8% |
| LiveCodeBench (Pass@1-COT) | Éxito en codificación con razonamiento en cadena de pensamiento. | 65.9% | 33.8% |
| AIME 2024 (Pass@1) | Resolución de problemas matemáticos avanzados. | 79.8% | 16.0% |
| MMLU-Pro (EM) | Precisión en tareas a nivel profesional. | 84.0% | 78.0% |
| GPQA-Diamond (Pass@1) | Respuesta a preguntas de propósito general. | 71.5% | 65.0% |
| AlpacaEval2.0 (LC-winrate) | Tareas de comprensión y conversación en lenguaje. | 87.6% | 52.0% |
| ArenaHard (GPT-4-1106) | Tareas de razonamiento difícil vs. GPT-4. | 92.3% | 85.2% |
| Precisión de depuración | Identificación y corrección de errores de código. | 90% | 75% |
Deepseek R1
DeepSeek R1 sobresale en programación, depuración y razonamiento matemático avanzado, lo que lo hace ideal para tareas técnicas y de lógica intensiva. Su sólido rendimiento en benchmarks como Codeforces, AIME y precisión de depuración resalta sus capacidades en estas áreas.
Claude 3.5 Sonnet
Claude 3.5 Sonnet, aunque más débil en programación y matemáticas, tiene un buen rendimiento en comprensión del lenguaje y tareas de conocimiento general, lo que lo hace más adecuado para aplicaciones multilingües y conversacionales.
DeepSeek R1 vs Claude 3.5: Velocidad y costo
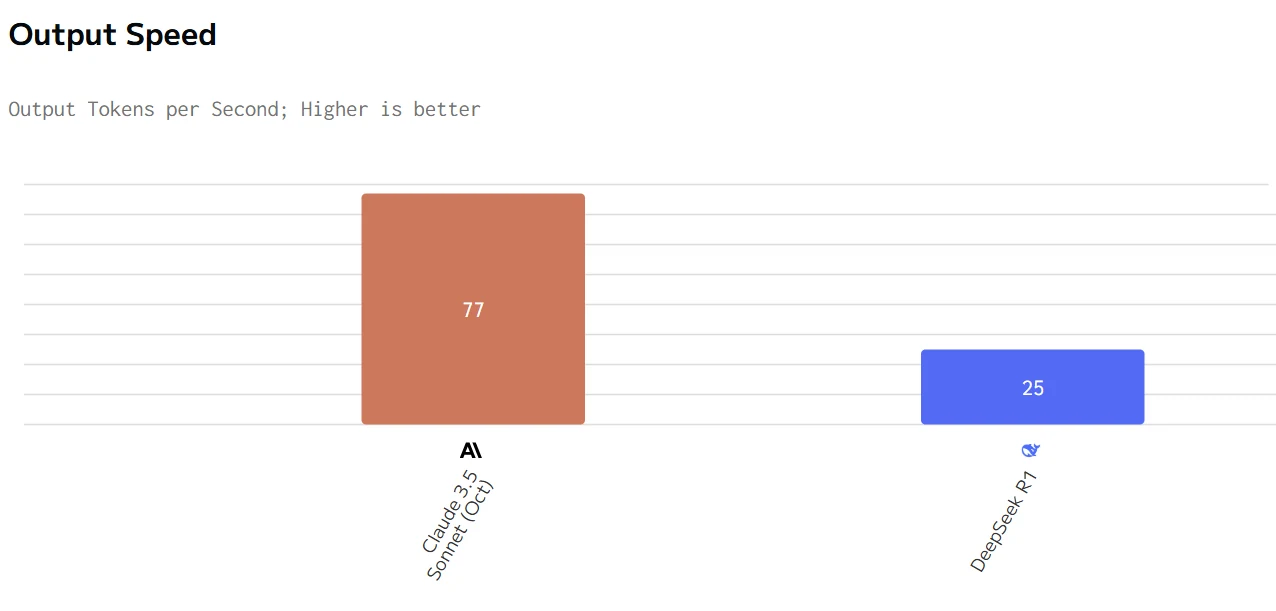
Comparación de velocidad de Deepseek R1 y Claude 3.5
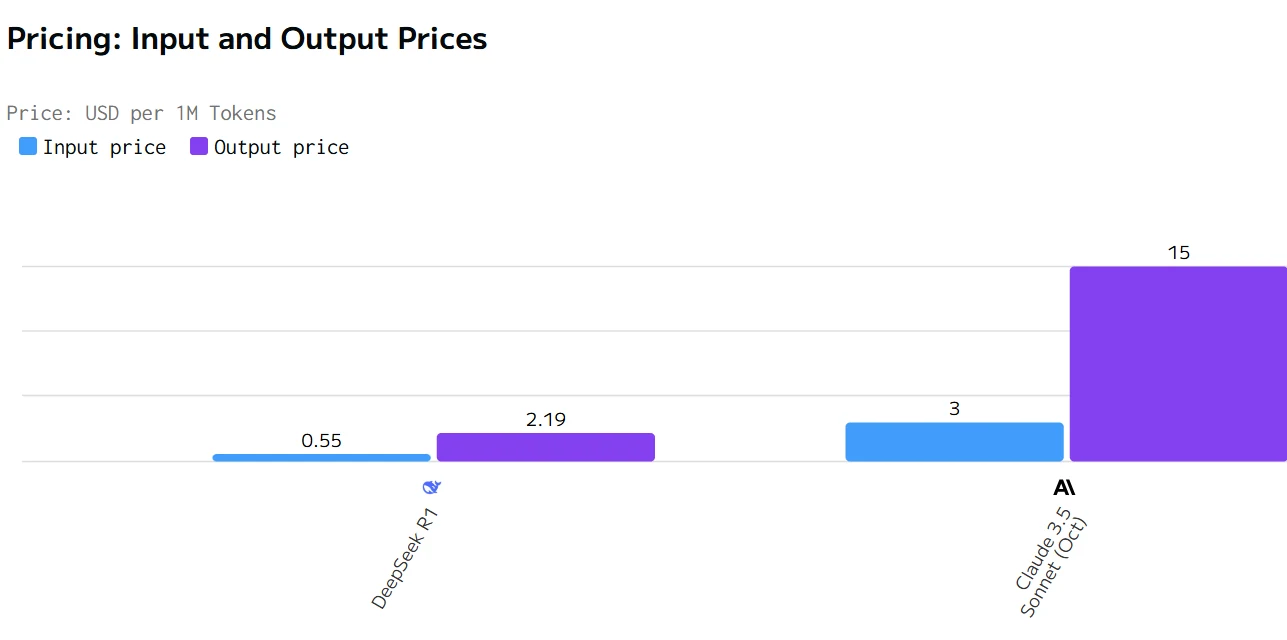
Comparación de costos de Deepseek R1 y Claude 3.5
Los datos anteriores provienen de artificial analysis
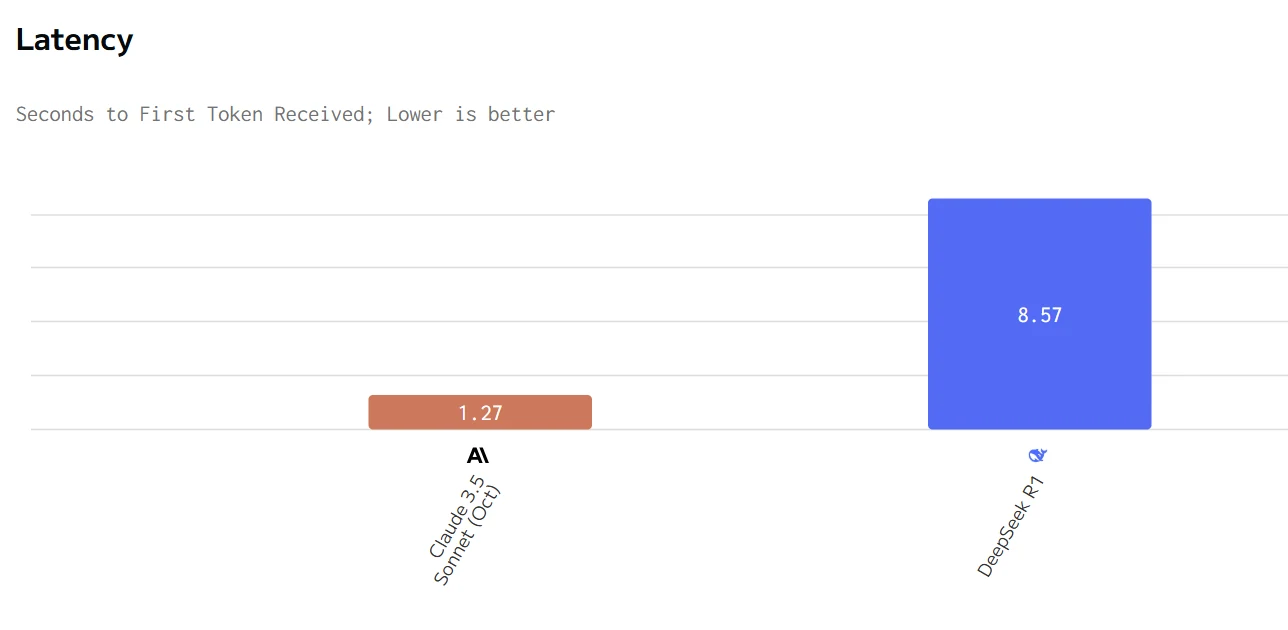
Claude ofrece métricas de rendimiento superiores (mayor velocidad de salida y menor latencia) pero a un precio considerablemente más alto. DeepSeek R1 es más económico pero más lento en respuesta y generación. La elección entre ellos dependerá de si la velocidad y la capacidad de respuesta o la eficiencia de costos es la prioridad más alta para un caso de uso específico.
Sin embargo, Novita AI lanza una versión Turbo con 3x el rendimiento y un descuento por tiempo limitado del 60%!
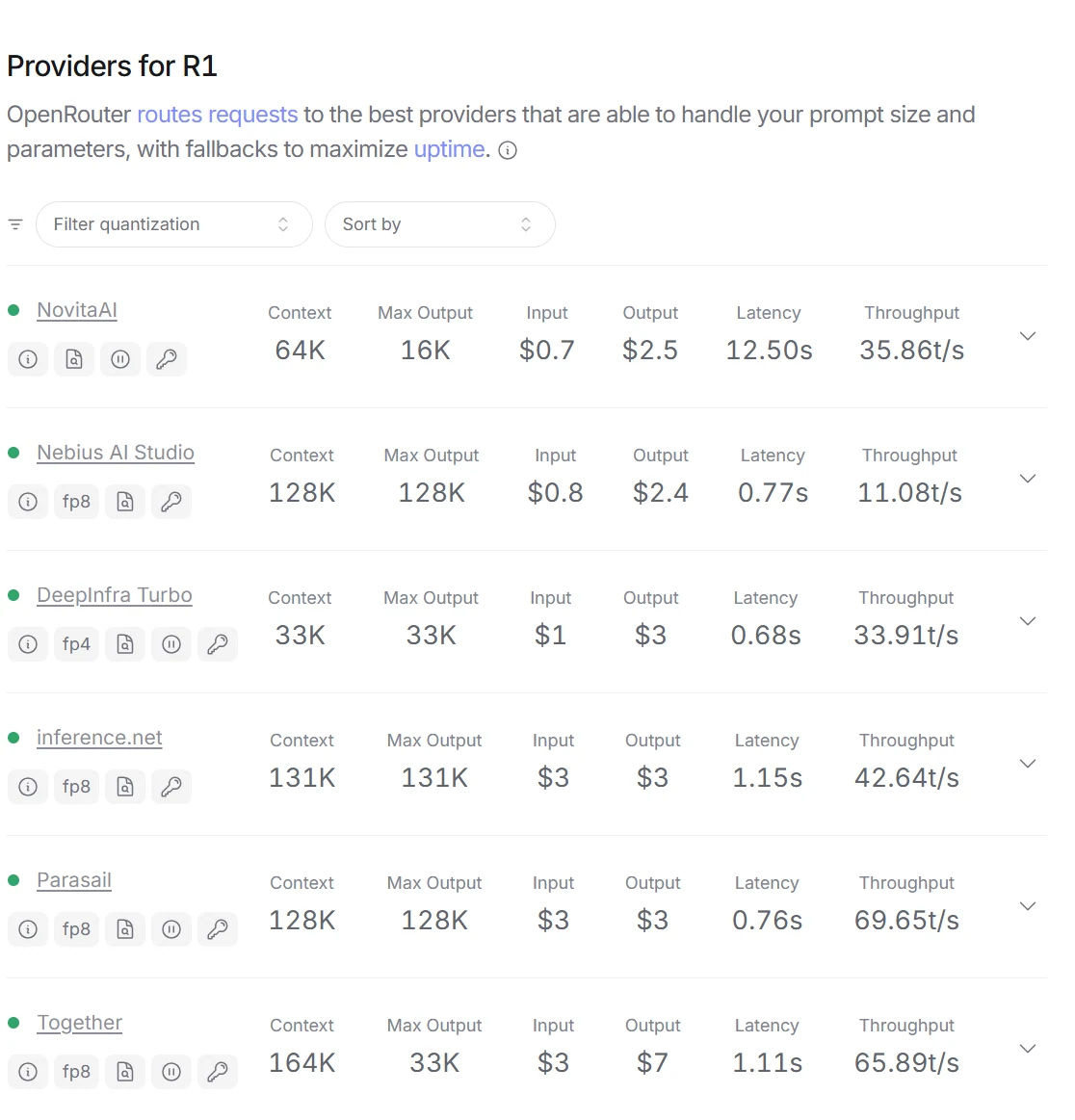
DeepSeek R1 vs Claude 3.5: Tareas
Tarea 1: Razonamiento lógico
Prompt: “Entras a una habitación y ves una cama. En la cama hay dos perros, cuatro gatos, una jirafa, cinco vacas y un pato. También hay tres sillas y una mesa. ¿Cuántas patas hay en el suelo?”
Resultado de Deepseek R1

Resultado de Claude 3.5

Revisión:
- Profundidad de razonamiento: DeepSeek R1 demuestra un proceso de razonamiento más profundo y exhaustivo, considerando todos los aspectos del problema.
- Precisión: DeepSeek R1 llega a la respuesta correcta (22), mientras que Claude 3.5 concluye incorrectamente con 20.
- Capacidad de autoverificación: DeepSeek R1 revisa y verifica continuamente su razonamiento, mientras que Claude 3.5 carece de este mecanismo de autoverificación.
- Manejo de ambigüedades: DeepSeek R1 puede abordar ambigüedades en el problema (como si la cama tiene patas), mientras que Claude 3.5 hace suposiciones simples sin explicación.
- Transparencia del pensamiento: El proceso de pensamiento de DeepSeek R1 es más transparente, lo que permite a las personas entender su camino de razonamiento.
Tarea 2: Razonamiento científico
Prompt: “Tienes un láser potente y un espejo perfectamente reflectante. ¿Cómo puedes apuntar el láser al espejo de tal manera que el haz reflejado nunca regrese a ti?”
Resultado de Deepseek R1

Resultado de Claude 3.5

Revisión:
- DeepSeek R1 demuestra un razonamiento científico significativamente más sólido:
- Precisión física: La respuesta de DeepSeek R1 es físicamente correcta y sigue principios ópticos establecidos, mientras que la respuesta de Claude 3.5 contiene conceptos erróneos fundamentales.
- Consistencia lógica: DeepSeek R1 mantiene consistencia lógica a lo largo de su explicación, mientras que la respuesta de Claude 3.5 contiene contradicciones internas.
- Resolución de problemas: DeepSeek R1 resuelve correctamente el problema proporcionando un rango válido de soluciones, mientras que Claude 3.5 propone una solución imposible.
- Conocimiento científico: DeepSeek R1 demuestra una comprensión adecuada de la ley de reflexión, mientras que Claude 3.5 parece confundir conceptos ópticos básicos.
Tarea 3: Habilidades de resolución de problemas
Prompt: “Escribe un programa que pueda resolver un rompecabezas Sudoku”
Resultado de Deepseek R1
def find_empty(grid):
for row in range(9):
for col in range(9):
if grid[row][col] == 0:
return (row, col) # Return empty cell position
return None # No empty cells left
def is_valid(grid, num, pos):
row, col = pos
# Check row
for i in range(9):
if grid[row][i] == num and i != col:
return False
# Check column
for i in range(9):
if grid[i][col] == num and i != row:
return False
# Check 3x3 subgrid
start_row = (row // 3) * 3
start_col = (col // 3) * 3
for i in range(start_row, start_row + 3):
for j in range(start_col, start_col + 3):
if grid[i][j] == num and (i, j) != pos:
return False
return True
def solve(grid):
empty = find_empty(grid)
if not empty:
return True # Puzzle solved
row, col = empty
for num in range(1, 10):
if is_valid(grid, num, (row, col)):
grid[row][col] = num # Place number
if solve(grid):
return True # Continue solving
grid[row][col] = 0 # Backtrack if invalid
return False # Trigger backtracking
def print_grid(grid):
for row in grid:
print(row)
# Example Sudoku puzzle (0 represents empty cells)
grid = [
[5,3,0,0,7,0,0,0,0],
[6,0,0,1,9,5,0,0,0],
[0,9,8,0,0,0,0,6,0],
[8,0,0,0,6,0,0,0,3],
[4,0,0,8,0,3,0,0,1],
[7,0,0,0,2,0,0,0,6],
[0,6,0,0,0,0,2,8,0],
[0,0,0,4,1,9,0,0,5],
[0,0,0,0,8,0,0,7,9]
]
if solve(grid):
print("Solved Sudoku:")
print_grid(grid)
else:
print("No solution exists")
Resultado de Claude 3.5
def print_board(board):
for i in range(9):
if i % 3 == 0 and i != 0:
print("- - - - - - - - - - - -")
for j in range(9):
if j % 3 == 0 and j != 0:
print("|", end=" ")
if j == 8:
print(board[i][j])
else:
print(str(board[i][j]) + " ", end="")
def find_empty(board):
for i in range(9):
for j in range(9):
if board[i][j] == 0:
return (i, j)
return None
def valid(board, num, pos):
# Check row
for j in range(9):
if board[pos[0]][j] == num and pos[1] != j:
return False
# Check column
for i in range(9):
if board[i][pos[1]] == num and pos[0] != i:
return False
# Check box
box_x = pos[1] // 3
box_y = pos[0] // 3
for i in range(box_y * 3, box_y * 3 + 3):
for j in range(box_x * 3, box_x * 3 + 3):
if board[i][j] == num and (i, j) != pos:
return False
return True
def solve(board):
empty = find_empty(board)
if not empty:
return True
row, col = empty
for num in range(1, 10):
if valid(board, num, (row, col)):
board[row][col] = num
if solve(board):
return True
board[row][col] = 0
return False
# Example puzzle (0 represents empty cells)
board = [
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
]
print("Original Sudoku:")
print_board(board)
print("\
Solving...\
")
if solve(board):
print("Solved Sudoku:")
print_board(board)
else:
print("No solution exists")
Revisión:
- Implementación del algoritmo: Ambos están a la par, implementando correctamente el algoritmo de resolución de Sudoku.
- Legibilidad del código: El código generado por Claude 3.5 es ligeramente mejor, particularmente con una funcionalidad de impresión más amigable para el usuario.
- Experiencia de usuario: Claude 3.5 proporciona una experiencia de usuario más completa, incluyendo retroalimentación sobre las etapas de procesamiento.
- Estilo de código: Ambos mantienen un buen estilo de codificación Python consistente.
- Practicidad: El código generado por Claude 3.5 puede tener una ligera ventaja en uso práctico debido a su formato de salida más claro.
Cómo acceder a DeepSeek R1 mediante API?
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

¡Prueba DeepSeek R1 Demo ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Configuración” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 y Claude 3.5 Sonnet tienen cada uno sus fortalezas únicas. DeepSeek R1 sobresale en matemáticas, codificación y resolución lógica de problemas, ofreciendo eficiencia de costos y personalización como modelo de código abierto, ideal para desarrolladores, investigadores u organizaciones con presupuesto limitado.
Claude 3.5 Sonnet destaca en tareas multilingües, generación de código, razonamiento visual y manejo de grandes ventanas de contexto. Su integración fluida mediante APIs lo hace versátil para investigación, creación de contenido y chatbots avanzados.
La elección depende de los requisitos de la tarea y las prioridades del usuario, como el costo, la experiencia en el dominio o la facilidad de uso.
Preguntas frecuentes
¿Qué modelo es más rentable?
DeepSeek R1 es significativamente más asequible que Claude 3.5 Sonnet, especialmente para tokens de entrada y salida. Mientras tanto, Novita AI ofrece DeepSeek R1 Turbo, una versión optimizada de DeepSeek R1 que ofrece 3x el rendimiento, soporte completo para llamadas a funciones y un descuento por tiempo limitado del 60%!
¿Cuál es el tamaño de la ventana de contexto para cada modelo?
DeepSeek R1 tiene una ventana de contexto de 128k tokens, mientras que Claude 3.5 Sonnet ofrece una ventana de contexto más grande de 200k tokens.
¿DeepSeek R1 es de código abierto?
Sí, DeepSeek R1 es completamente de código abierto, lo que permite alojamiento local y personalización.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancia de GPU: las herramientas rentables que necesitas. Elimina infraestructura, comienza gratis y haz realidad tu visión de IA.



