

Wichtigste Highlights
Architekturunterschied: DeepSeek R1s Mixture-of-Experts (MoE)-Design optimiert die Leistung für logikintensive Aufgaben, während Claude 3.5s proprietäre Architektur auf Vielseitigkeit und mehrsprachige Fähigkeiten setzt.
Aufgaben-Spezialisierung: DeepSeek R1 glänzt bei Programmierung (96,3 % Codeforces) und Mathematik (79,8 % AIME), während Claude 3.5 im mehrsprachigen Verständnis, visuellem Denken und breiteren Gesprächskontexten überzeugt.
Kosteneffizienz vs. Geschwindigkeit: DeepSeek R1 ist wirtschaftlicher und Open Source, ideal für Entwickler, die Anpassung benötigen. Claude 3.5 liefert schnellere Ausgaben, jedoch zu höheren Kosten. Und Novita AI bringt eine Turbo-Version mit 3-fachem Durchsatz und einem zeitlich begrenzten Rabatt von 60 %!
Anthropics Claude 3.5 Sonnet und DeepSeek R1 haben sich als Schlüsselakteure im sich schnell entwickelnden Bereich der künstlichen Intelligenz etabliert. Beide Modelle, zu unterschiedlichen Zeiten veröffentlicht, demonstrieren fortschrittliche Fähigkeiten und haben aufgrund ihrer einzigartigen Merkmale und Leistungsattribute erhebliche Aufmerksamkeit erlangt.
DeepSeek R1 vs Claude 3.5: Grundlegende Einführung
| Merkmal | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|
| Veröffentlichungsdatum | 20. Januar 2025 | 22. Oktober 2024 |
| Modellgröße | 671 Milliarden Parameter (gesamt), 37 Milliarden pro Token aktiviert | Ca. 100 Milliarden Parameter |
| Unterstützte Sprachen | Hauptsächlich Chinesisch und Englisch | Mehrsprachig |
| Modellarchitektur | Mixture-of-Experts (MoE), trainiert durch groß angelegtes Reinforcement Learning mit minimalem überwachten Feintuning | Proprietär |
| Kontextfenster | 128k Token | 200k Token |
| Quantisierungspräzision | BF16, F8_E4M3, F32 (laut Hugging Face) | In Quellen nicht explizit angegeben |
| Open Source | Ja | Nein |
| Entwickler | DeepSeek | Anthropic |
| Multimodale Fähigkeit | Nur Text | Unterstützt Interpretation von Diagrammen und Grafiken |
Deepseek R1
- DeepSeek R1 wurde speziell für Aufgaben entwickelt, die fortgeschrittenes Denken und Programmierunterstützung erfordern. Es nutzt eine Mixture-of-Experts (MoE)-Architektur, die für jedes Token nur einen Teil seiner riesigen Parameter aktiviert und so die Recheneffizienz optimiert. Trainiert durch groß angelegtes Reinforcement Learning (RL) mit minimalem überwachten Feintuning (SFT), legt DeepSeek R1 einen starken Fokus auf Logik und Problemlösungsfähigkeiten.
Claude 3.5 Sonnet
- Claude 3.5 Sonnet, Anthropics fortschrittlichstes Modell, kombiniert außergewöhnliche Leistung mit verbesserter Geschwindigkeit. Es verfügt über ein großes Kontextfenster und zeichnet sich durch das Verständnis nuancierter und komplexer Anweisungen aus. Als Teil der Claude-3.5-Modellfamilie bietet es deutliche Verbesserungen gegenüber seinen Vorgängern, insbesondere in Bereichen wie Codierung und Werkzeugnutzung.
Sie können eine kostenlose Testversion auf Novita AI für die Deepseek R1-Serie starten!
DeepSeek R1 vs Claude 3.5: Benchmark
| Benchmark | Beschreibung | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|---|
| Codeforces (Perzentil) | Prozentrang bei Programmierproblemlösung. | 96,3 % | 20,3 % |
| Codeforces (Bewertung) | Bewertung des Programmierwettbewerbs. | 2029 | 717 |
| SWE Verified (Gelöst) | Gelöste Softwareentwicklungsprobleme. | 49,2 % | 50,8 % |
| LiveCodeBench (Pass@1-COT) | Codeerfolg mit Ketten-Denkprozess. | 65,9 % | 33,8 % |
| AIME 2024 (Pass@1) | Fortgeschrittene mathematische Problemlösung. | 79,8 % | 16,0 % |
| MMLU-Pro (EM) | Genauigkeit bei Aufgaben auf professionellem Niveau. | 84,0 % | 78,0 % |
| GPQA-Diamond (Pass@1) | Allgemeine Fragebeantwortung. | 71,5 % | 65,0 % |
| AlpacaEval2.0 (LC-winrate) | Sprachverständnis und Konversationsaufgaben. | 87,6 % | 52,0 % |
| ArenaHard (GPT-4-1106) | Schwierige Denkaufgaben vs. GPT-4. | 92,3 % | 85,2 % |
| Debugging-Genauigkeit | Identifizieren und Beheben von Code-Fehlern. | 90 % | 75 % |
Deepseek R1
DeepSeek R1 zeichnet sich in den Bereichen Programmierung, Debugging und fortgeschrittenem mathematischen Denken aus und ist daher ideal für technische und logikintensive Aufgaben. Seine starke Leistung in Benchmarks wie Codeforces, AIME und Debugging-Genauigkeit unterstreicht seine Fähigkeiten in diesen Bereichen.
Claude 3.5 Sonnet
Claude 3.5 Sonnet ist zwar schwächer in Programmierung und Mathematik, schneidet jedoch gut beim Sprachverständnis und allgemeinen Wissensaufgaben ab und eignet sich daher besser für mehrsprachige und konversationelle Anwendungen.
DeepSeek R1 vs Claude 3.5: Geschwindigkeit und Kosten
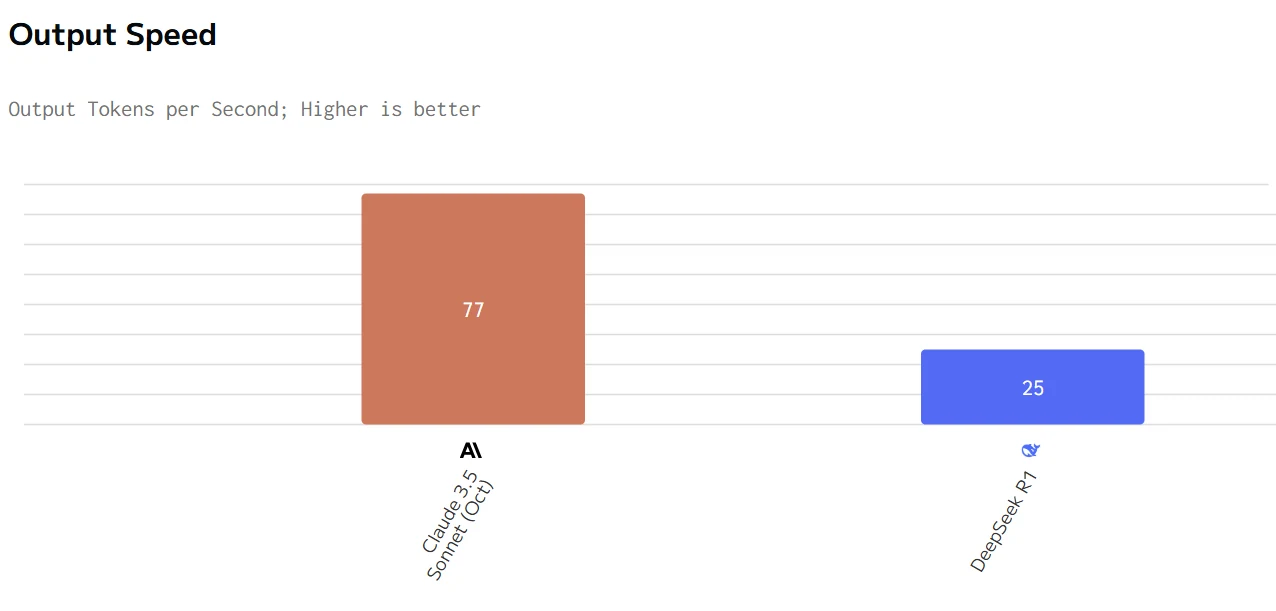
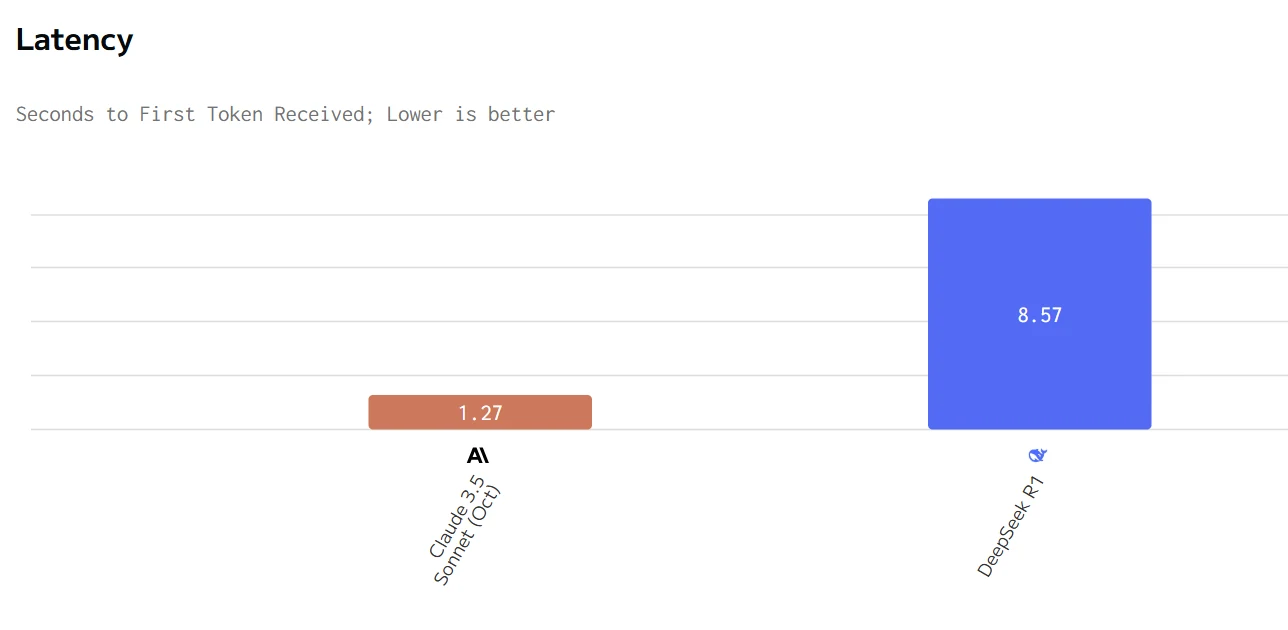
Geschwindigkeitsvergleich von Deepseek R1 und Claude 3.5
Kostenvergleich von Deepseek R1 und Claude 3.5
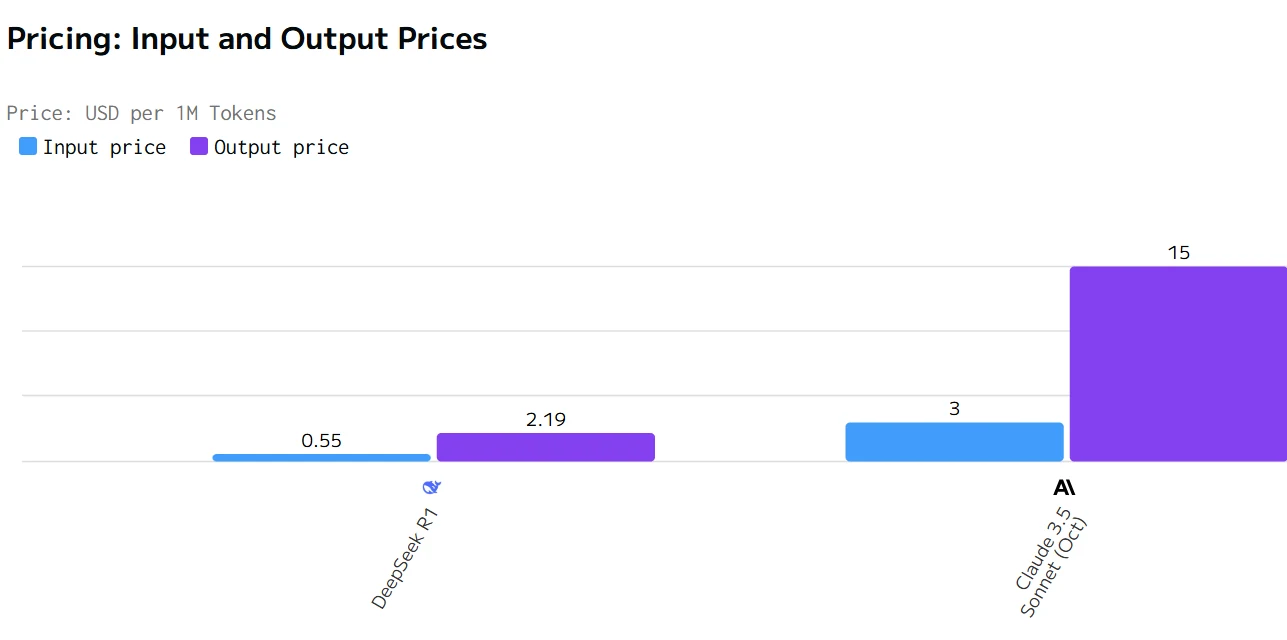
Die obigen Daten stammen von artificial analysis
Claude bietet überlegene Leistungskennzahlen (schnellere Ausgabegeschwindigkeit und geringere Latenz), jedoch zu einem deutlich höheren Preis. DeepSeek R1 ist wirtschaftlicher, aber langsamer in Reaktion und Generierung. Die Wahl zwischen ihnen hängt davon ab, ob Geschwindigkeit und Reaktionsfähigkeit oder Kosteneffizienz für einen bestimmten Anwendungsfall die höhere Priorität haben.
Novita AI bringt jedoch eine Turbo-Version mit 3-fachem Durchsatz und einem zeitlich begrenzten Rabatt von 60 %!
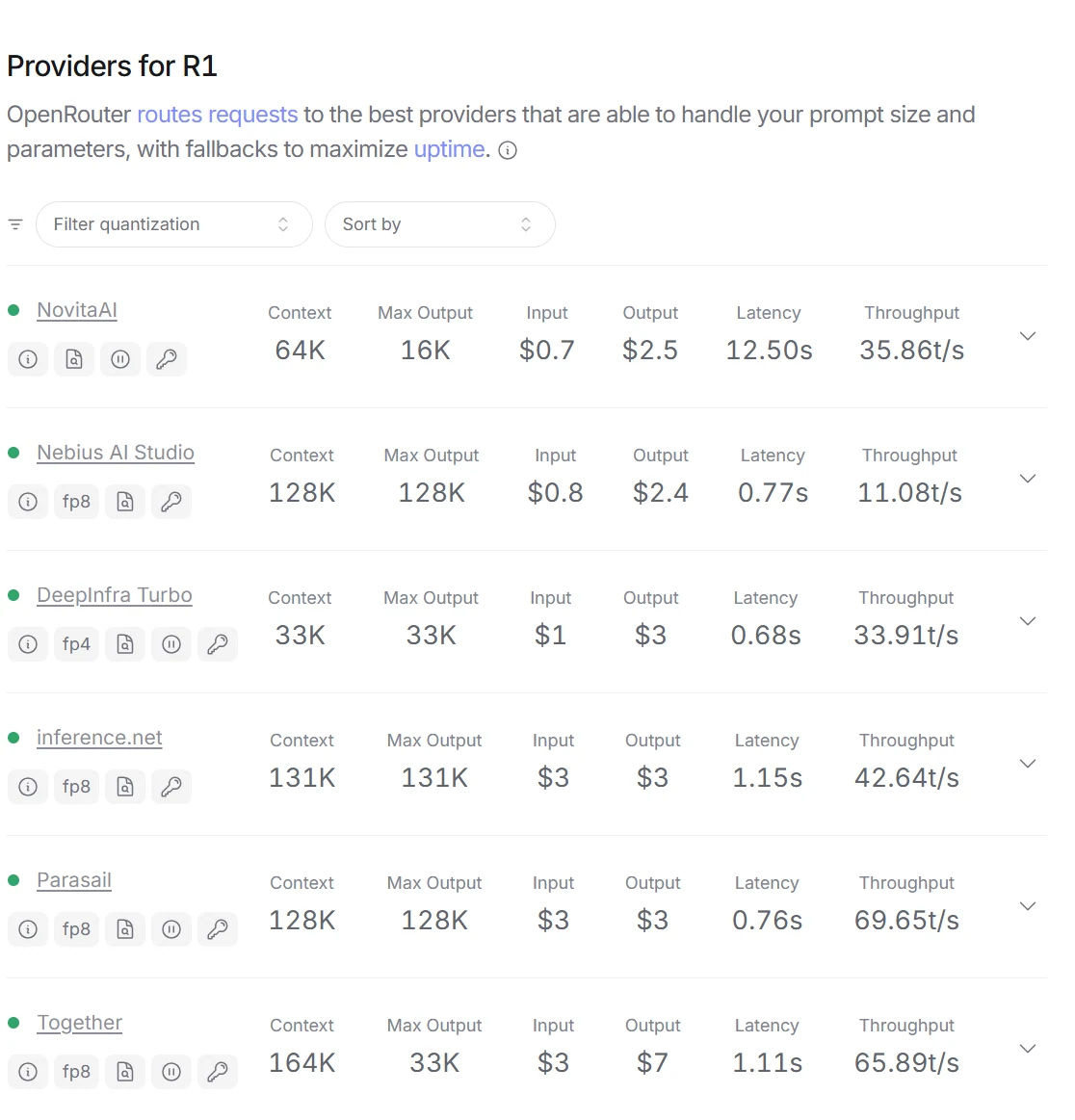
DeepSeek R1 vs Claude 3.5: Aufgaben
Aufgabe 1: Logisches Denken
Prompt: „Sie betreten einen Raum und sehen ein Bett. Auf dem Bett befinden sich zwei Hunde, vier Katzen, eine Giraffe, fünf Kühe und eine Ente. Es gibt auch drei Stühle und einen Tisch. Wie viele Beine stehen auf dem Boden?“
Deepseek R1 Ergebnis

Claude 3.5 Ergebnis

Bewertung:
- Denktiefe: DeepSeek R1 zeigt einen tieferen, gründlicheren Denkprozess und berücksichtigt alle Aspekte des Problems.
- Genauigkeit: DeepSeek R1 kommt letztlich zur richtigen Antwort (22), während Claude 3.5 fälschlicherweise 20 schlussfolgert.
- Selbstüberprüfungsfähigkeit: DeepSeek R1 überprüft und kontrolliert kontinuierlich seine Argumentation, während Claude 3.5 diesen Mechanismus vermissen lässt.
- Umgang mit Mehrdeutigkeiten: DeepSeek R1 kann Mehrdeutigkeiten im Problem (z. B. ob das Bett Beine hat) adressieren, während Claude 3.5 einfache Annahmen ohne Erklärung trifft.
- Transparenz des Denkens: DeepSeek R1s Denkprozess ist transparenter, sodass Menschen seinen Argumentationspfad nachvollziehen können.
Aufgabe 2: Wissenschaftliches Denken
Prompt: „Sie haben einen leistungsstarken Laser und einen perfekt reflektierenden Spiegel. Wie können Sie den Laser auf den Spiegel richten, sodass der reflektierte Strahl niemals zu Ihnen zurückkehrt?“
Deepseek R1 Ergebnis

Claude 3.5 Ergebnis

Bewertung:
- DeepSeek R1 demonstriert deutlich stärkeres wissenschaftliches Denken:
- Physikalische Genauigkeit: DeepSeek R1s Antwort ist physikalisch korrekt und folgt etablierten optischen Prinzipien, während Claude 3.5s Antwort grundlegende Fehlvorstellungen enthält.
- Logische Konsistenz: DeepSeek R1 bewahrt während der gesamten Erklärung logische Konsistenz, während Claude 3.5s Antwort innere Widersprüche aufweist.
- Problemlösung: DeepSeek R1 löst das Problem korrekt, indem es einen gültigen Lösungsbereich angibt, während Claude 3.5 eine unmögliche Lösung vorschlägt.
- Wissenschaftliche Kenntnisse: DeepSeek R1 zeigt ein angemessenes Verständnis des Reflexionsgesetzes, während Claude 3.5 grundlegende optische Konzepte zu verwechseln scheint.
Aufgabe 3: Problemlösungsfähigkeiten
Prompt: „Schreiben Sie ein Programm, das ein Sudoku-Rätsel lösen kann“
Deepseek R1 Ergebnis
def find_empty(grid):
for row in range(9):
for col in range(9):
if grid[row][col] == 0:
return (row, col) # Return empty cell position
return None # No empty cells left
def is_valid(grid, num, pos):
row, col = pos
# Check row
for i in range(9):
if grid[row][i] == num and i != col:
return False
# Check column
for i in range(9):
if grid[i][col] == num and i != row:
return False
# Check 3x3 subgrid
start_row = (row // 3) * 3
start_col = (col // 3) * 3
for i in range(start_row, start_row + 3):
for j in range(start_col, start_col + 3):
if grid[i][j] == num and (i, j) != pos:
return False
return True
def solve(grid):
empty = find_empty(grid)
if not empty:
return True # Puzzle solved
row, col = empty
for num in range(1, 10):
if is_valid(grid, num, (row, col)):
grid[row][col] = num # Place number
if solve(grid):
return True # Continue solving
grid[row][col] = 0 # Backtrack if invalid
return False # Trigger backtracking
def print_grid(grid):
for row in grid:
print(row)
# Example Sudoku puzzle (0 represents empty cells)
grid = [
[5,3,0,0,7,0,0,0,0],
[6,0,0,1,9,5,0,0,0],
[0,9,8,0,0,0,0,6,0],
[8,0,0,0,6,0,0,0,3],
[4,0,0,8,0,3,0,0,1],
[7,0,0,0,2,0,0,0,6],
[0,6,0,0,0,0,2,8,0],
[0,0,0,4,1,9,0,0,5],
[0,0,0,0,8,0,0,7,9]
]
if solve(grid):
print("Solved Sudoku:")
print_grid(grid)
else:
print("No solution exists")
Claude 3.5 Ergebnis
def print_board(board):
for i in range(9):
if i % 3 == 0 and i != 0:
print("- - - - - - - - - - - -")
for j in range(9):
if j % 3 == 0 and j != 0:
print("|", end=" ")
if j == 8:
print(board[i][j])
else:
print(str(board[i][j]) + " ", end="")
def find_empty(board):
for i in range(9):
for j in range(9):
if board[i][j] == 0:
return (i, j)
return None
def valid(board, num, pos):
# Check row
for j in range(9):
if board[pos[0]][j] == num and pos[1] != j:
return False
# Check column
for i in range(9):
if board[i][pos[1]] == num and pos[0] != i:
return False
# Check box
box_x = pos[1] // 3
box_y = pos[0] // 3
for i in range(box_y * 3, box_y * 3 + 3):
for j in range(box_x * 3, box_x * 3 + 3):
if board[i][j] == num and (i, j) != pos:
return False
return True
def solve(board):
empty = find_empty(board)
if not empty:
return True
row, col = empty
for num in range(1, 10):
if valid(board, num, (row, col)):
board[row][col] = num
if solve(board):
return True
board[row][col] = 0
return False
# Example puzzle (0 represents empty cells)
board = [
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
]
print("Original Sudoku:")
print_board(board)
print("\
Solving...\
")
if solve(board):
print("Solved Sudoku:")
print_board(board)
else:
print("No solution exists")
Bewertung:
- Algorithmusimplementierung: Beide sind gleichwertig und implementieren den Sudoku-Lösungsalgorithmus korrekt.
- Code-Lesbarkeit: Der generierte Code von Claude 3.5 ist etwas besser, insbesondere durch eine benutzerfreundlichere Ausgabefunktionalität.
- Benutzererfahrung: Claude 3.5 bietet eine vollständigere Benutzererfahrung, einschließlich Rückmeldungen zu den Verarbeitungsschritten.
- Codestil: Beide behalten einen guten und konsistenten Python-Codestil bei.
- Praktikabilität: Der generierte Code von Claude 3.5 könnte aufgrund seines klareren Ausgabeformats im praktischen Einsatz einen leichten Vorteil haben.
Wie kann man DeepSeek R1 per API nutzen?
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

DeepSeek R1 Demo jetzt testen!
Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
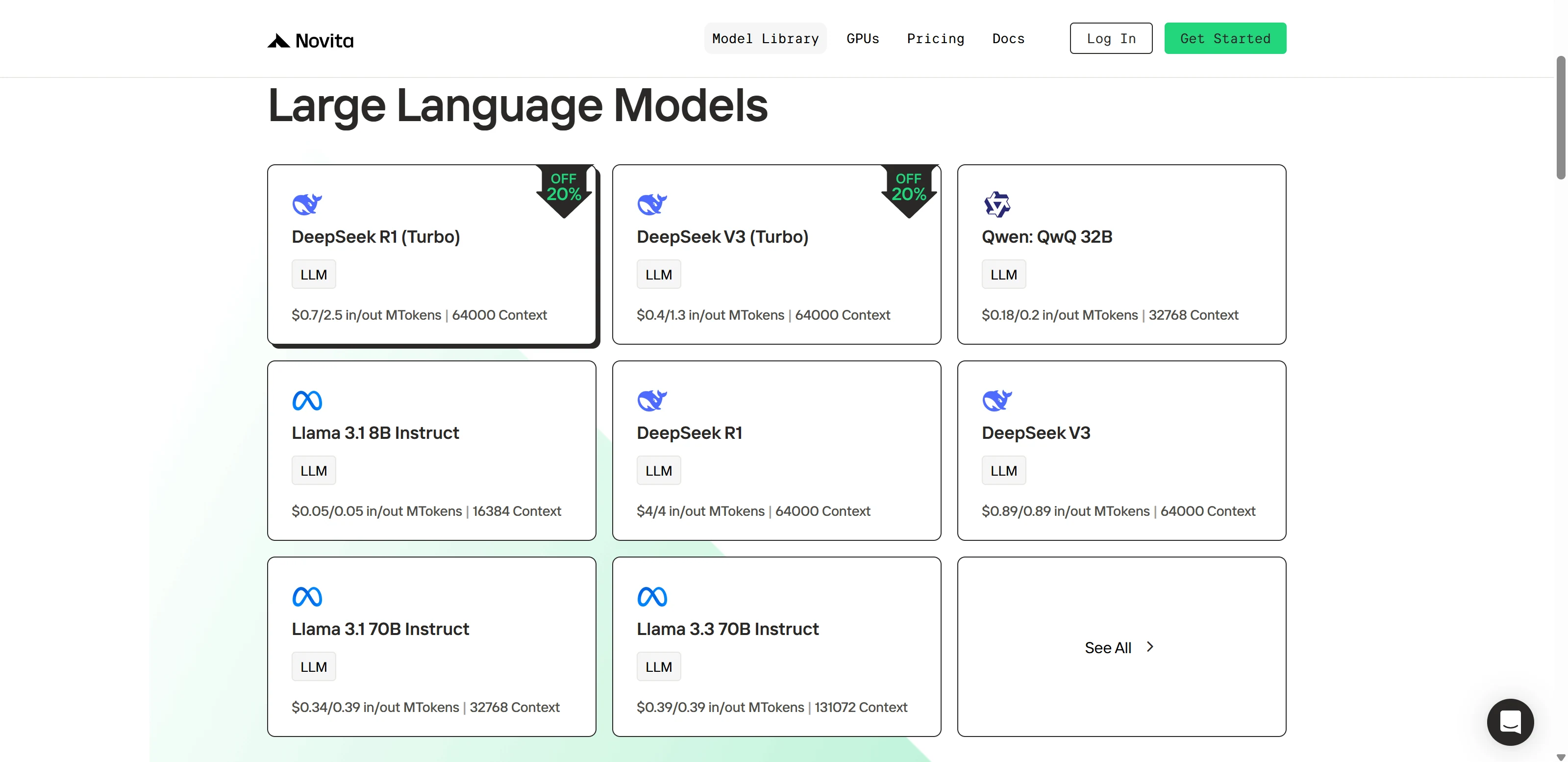
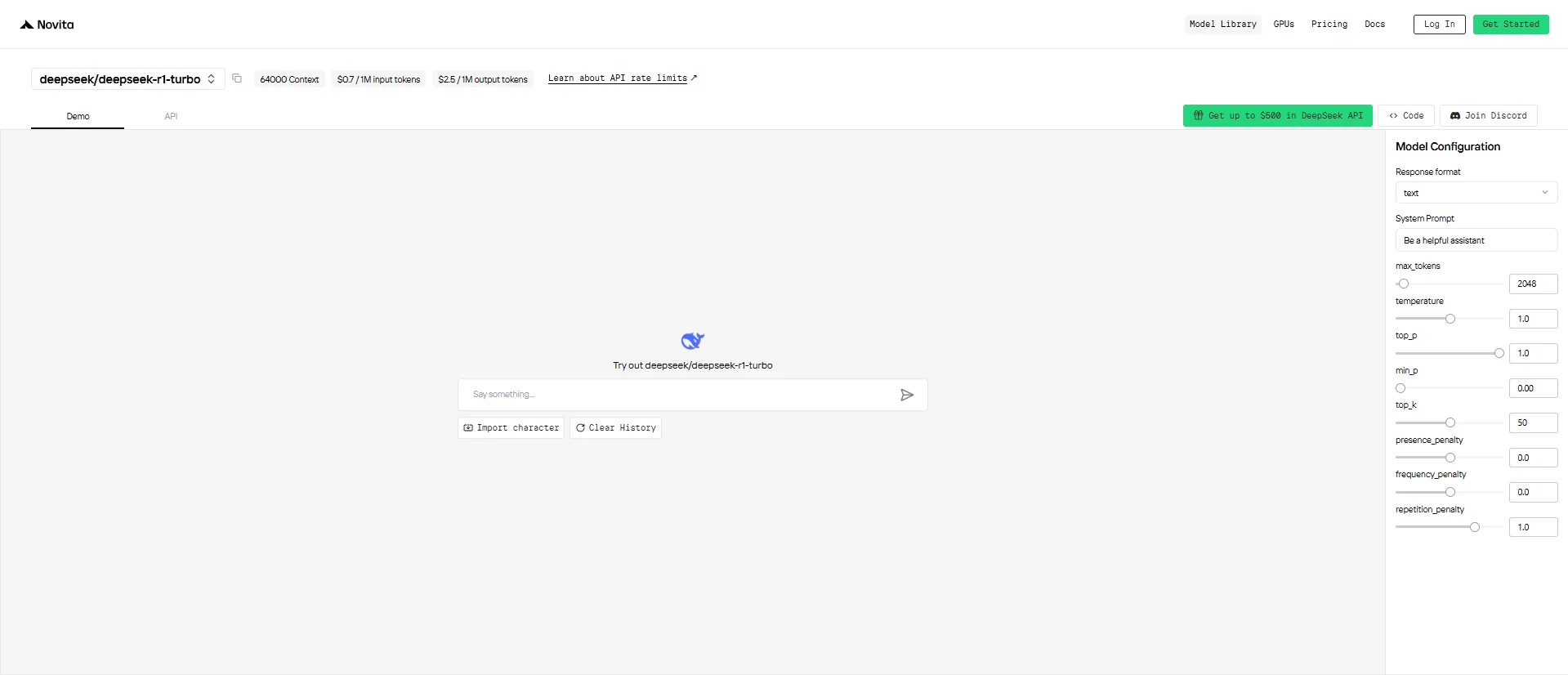
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 und Claude 3.5 Sonnet haben jeweils einzigartige Stärken. DeepSeek R1 zeichnet sich in Mathematik, Codierung und logischem Denken aus und bietet als Open-Source-Modell Kosteneffizienz und Anpassungsmöglichkeiten – ideal für Entwickler, Forscher oder budgetbewusste Organisationen.
Claude 3.5 Sonnet glänzt bei mehrsprachigen Aufgaben, Codegenerierung, visuellem Denken und der Verarbeitung großer Kontextfenster. Seine nahtlose Integration über APIs macht es vielseitig für Forschung, Content-Erstellung und fortgeschrittene Chatbots.
Die Wahl hängt von den Aufgabenanforderungen und Benutzerprioritäten ab, wie Kosten, Fachkenntnisse oder Benutzerfreundlichkeit.
Häufig gestellte Fragen
Welches Modell ist kosteneffizienter?
DeepSeek R1 ist deutlich günstiger als Claude 3.5 Sonnet, insbesondere bei Eingabe- und Ausgabetoken. Novita AI bietet zudem DeepSeek R1 Turbo an, eine optimierte Version von DeepSeek R1 mit 3-fachem Durchsatz, vollständiger Unterstützung von Funktionsaufrufen und einem zeitlich begrenzten Rabatt von 60 %!
Wie groß ist das Kontextfenster der einzelnen Modelle?
DeepSeek R1 hat ein Kontextfenster von 128k Token, während Claude 3.5 Sonnet ein größeres Kontextfenster von 200k Token bietet.
Ist DeepSeek R1 Open Source?
Ja, DeepSeek R1 ist vollständig Open Source und ermöglicht lokales Hosting und Anpassung.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz – die kostengünstigen Tools, die Sie benötigen. Bauen Sie Infrastruktur ab, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



