

主な要点
アーキテクチャの違い: DeepSeek R1 の Mixture-of-Experts (MoE) 設計は論理重視のタスクで性能を最適化する一方、Claude 3.5 の独自アーキテクチャは汎用性と多言語対応を優先します。
タスク特化: DeepSeek R1 はプログラミング(Codeforces 96.3%)と数学(AIME 79.8%)に優れ、Claude 3.5 は多言語理解、視覚的推論、より広範な会話コンテキストで輝きます。
コスト効率と速度: DeepSeek R1 は経済的でオープンソースであるため、カスタマイズが必要な開発者に最適です。Claude 3.5 はより高速な出力を提供しますが、コストは高くなります。そして Novita AI は、スループットが3倍で期間限定60%割引の Turbo バージョンをリリースしました!
急速に進化する人工知能の分野において、Anthropic の Claude 3.5 Sonnet と DeepSeek の R1 は主要なプレイヤーとして浮上しています。異なる時期にリリースされた両モデルは高度な機能を示し、その独自の特徴とパフォーマンス属性で大きな注目を集めています。
DeepSeek R1 vs Claude 3.5:基本紹介
| **機能 ** | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|
| リリース日 | 2025年1月20日 | 2024年10月22日 |
| モデルサイズ | 総パラメータ6710億、トークンあたりアクティブ370億 | 約1000億パラメータ |
| 対応言語 | 主に中国語と英語 | 多言語 |
| モデルアーキテクチャ | Mixture-of-Experts (MoE)、最小限の教師あり微調整で大規模強化学習により訓練 | 独自 |
| コンテキストウィンドウ | 128k トークン | 200k トークン |
| 量子化精度 | BF16、F8_E4M3、F32(Hugging Face による) | ソースでは明示的に指定されていません |
| オープンソース | はい | いいえ |
| 開発者 | DeepSeek | Anthropic |
| マルチモーダル機能 | テキストのみ | チャートやグラフの解釈をサポート |
Deepseek R1
- DeepSeek R1 は高度な推論とプログラミング支援を必要とするタスク向けに設計されています。Mixture-of-Experts (MoE) アーキテクチャを活用し、トークンごとに膨大なパラメータのサブセットのみをアクティブ化することで計算効率を最適化します。最小限の教師あり微調整 (SFT) で大規模強化学習 (RL) を通じて訓練された DeepSeek R1 は、論理と問題解決能力を重視しています。
Claude 3.5 Sonnet
- Anthropic の最も先進的なモデルである Claude 3.5 Sonnet は、卓越したパフォーマンスと高速性を兼ね備えています。大きなコンテキストウィンドウを備え、微妙で複雑な指示を理解することに優れています。Claude 3.5 モデルファミリーの一部として、特にコーディングやツール活用の分野で、前世代から大幅な改善を実現しています。
Novita AI で Deepseek R1 シリーズの無料トライアルを開始できます!
DeepSeek R1 vs Claude 3.5:ベンチマーク
| **ベンチマーク ** | ** 説明 ** | DeepSeek R1 | Claude 3.5 Sonnet |
|---|---|---|---|
| Codeforces (パーセンタイル) | プログラミング問題解決のパーセンタイル。 | 96.3% | 20.3% |
| Codeforces (レーティング) | プログラミングコンテストのレーティング。 | 2029 | 717 |
| SWE Verified (解決率) | 解決されたソフトウェアエンジニアリング問題。 | 49.2% | 50.8% |
| LiveCodeBench (Pass@1-COT) | チェーン・オブ・ソート推論によるコーディング成功率。 | 65.9% | 33.8% |
| AIME 2024 (Pass@1) | 高度な数学問題解決。 | 79.8% | 16.0% |
| MMLU-Pro (EM) | プロフェッショナルレベルのタスク精度。 | 84.0% | 78.0% |
| GPQA-Diamond (Pass@1) | 汎用質問応答。 | 71.5% | 65.0% |
| AlpacaEval2.0 (LC-winrate) | 言語理解と会話タスク。 | 87.6% | 52.0% |
| ArenaHard (GPT-4-1106) | GPT-4 対比のハード推論タスク。 | 92.3% | 85.2% |
| デバッグ精度 | コードバグの特定と修正。 | 90% | 75% |
Deepseek R1
DeepSeek R1 はプログラミング、デバッグ、高度な数学的推論に優れており、技術的で論理重視のタスクに最適です。Codeforces、AIME、デバッグ精度などのベンチマークでの強力なパフォーマンスは、これらの分野におけるその能力を示しています。
Claude 3.5 Sonnet
Claude 3.5 Sonnet はプログラミングや数学ではやや劣るものの、言語理解や汎用知識タスクで良いパフォーマンスを発揮し、多言語対応や会話型アプリケーションにより適しています。
DeepSeek R1 vs Claude 3.5:速度とコスト
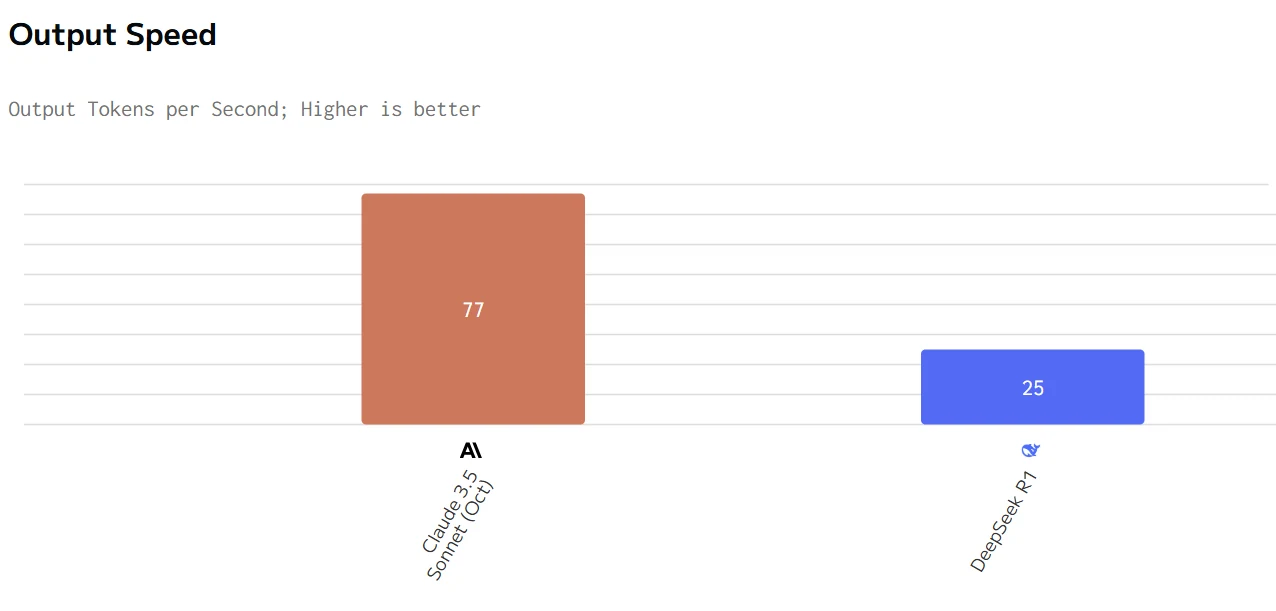
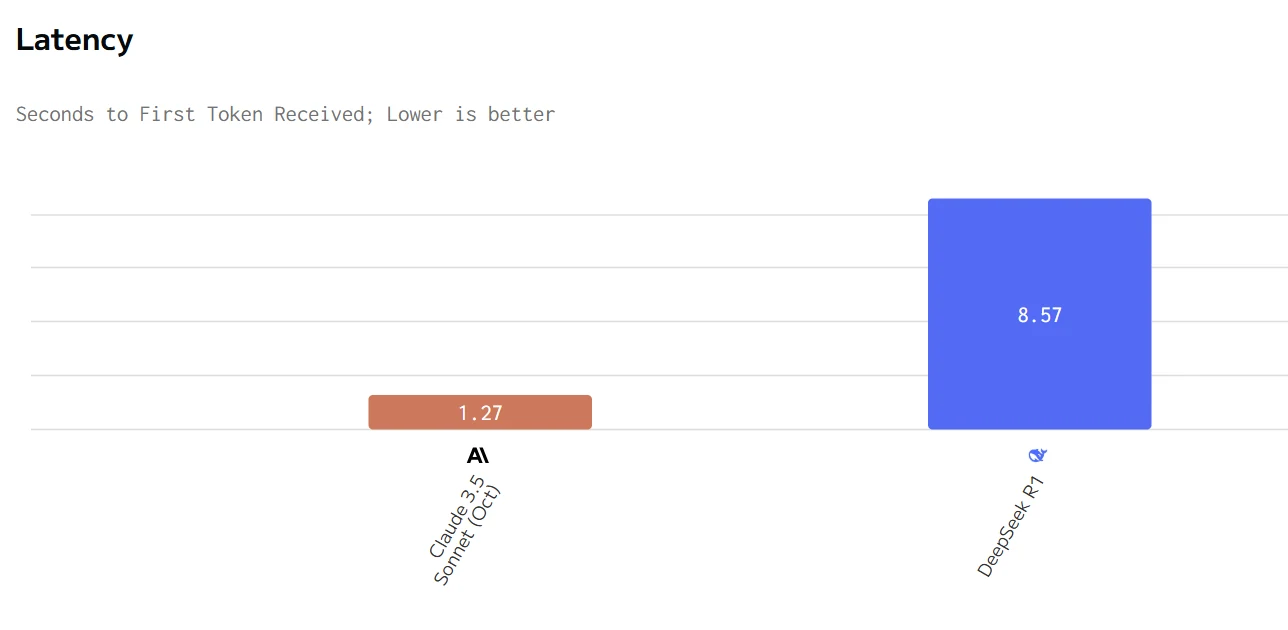
Deepseek R1 と Claude 3.5 の速度比較
Deepseek R1 と Claude 3.5 のコスト比較
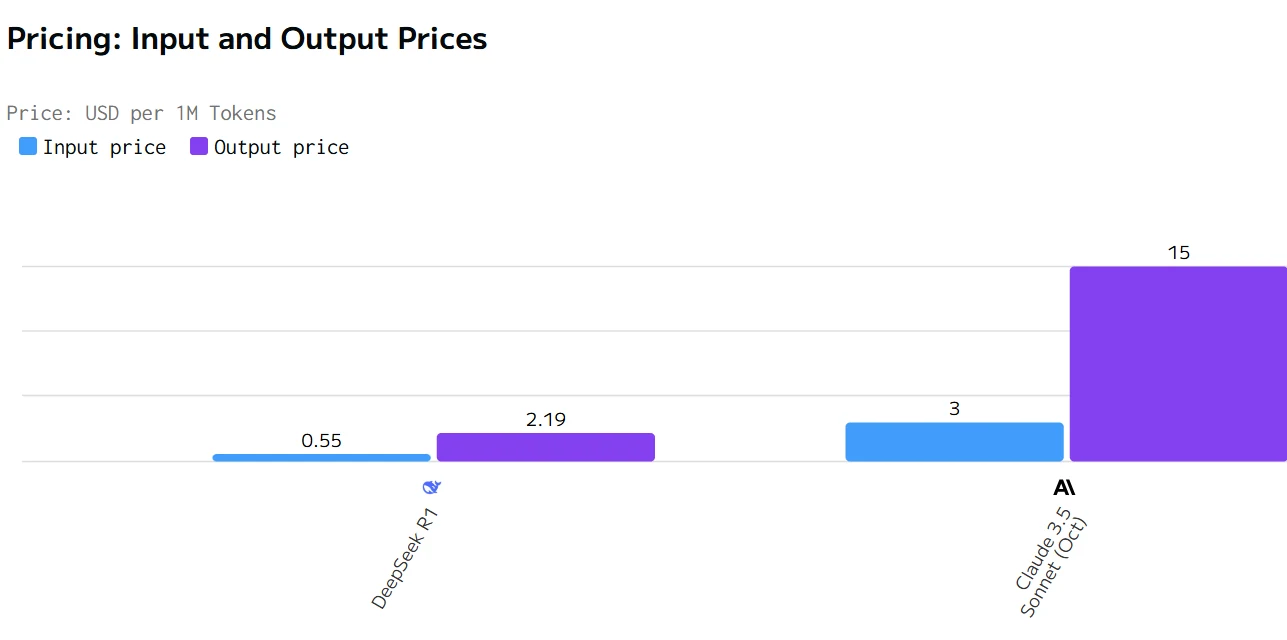
上記データは artificial analysis からのものです。
Claude は優れたパフォーマンス指標(より高速な出力速度と低レイテンシ)を提供しますが、価格はかなり高くなります。DeepSeek R1 はより経済的ですが、応答と生成が遅くなります。どちらを選ぶかは、特定のユースケースにおいて速度と応答性、またはコスト効率のどちらを優先するかによって決まります。
ただし、Novita AI はスループット3倍、期間限定60%割引の Turbo バージョンをリリースしました!
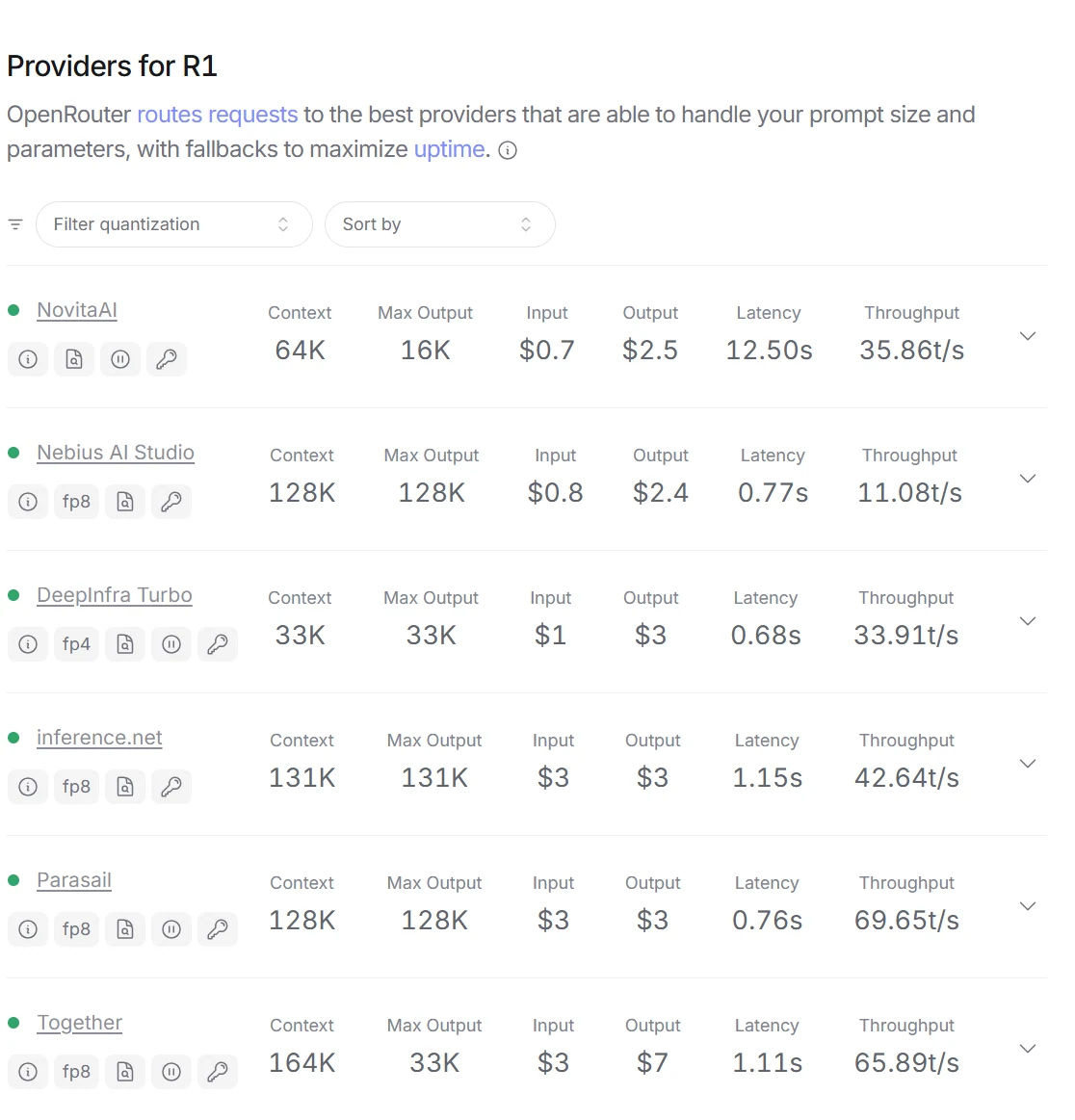
DeepSeek R1 vs Claude 3.5:タスク
タスク1:論理的推論
プロンプト: 「部屋に入るとベッドがあります。ベッドの上には2匹の犬、4匹の猫、キリン1頭、牛5頭、アヒル1羽がいます。椅子が3つとテーブルが1つもあります。床には何本の脚がありますか?」
Deepseek R1 の結果

Claude 3.5 の結果

レビュー:
- 推論の深さ: DeepSeek R1 はより深く徹底した推論プロセスを示し、問題のあらゆる側面を考慮しています。
- 正確性: DeepSeek R1 は最終的に正しい答え(22)に到達しますが、Claude 3.5 は誤って20と結論付けています。
- 自己検証能力: DeepSeek R1 は自身の推論を継続的に見直し確認しますが、Claude 3.5 にはこの自己検証メカニズムが欠けています。
- あいまいさへの対応: DeepSeek R1 は問題のあいまいさ(ベッドに脚があるかどうかなど)に対処できる一方、Claude 3.5 は説明なしに単純な仮定を行います。
- 思考の透明性: DeepSeek R1 の思考プロセスはより透明であり、人々がその推論経路を理解できます。
タスク2:科学的推論
プロンプト: 「強力なレーザーと完全反射鏡があります。反射したビームが決して自分に戻ってこないようにレーザーを鏡に向けるにはどうすればよいですか?」
Deepseek R1 の結果

Claude 3.5 の結果

レビュー:
- DeepSeek R1 は著しく強力な科学的推論を示しています:
- 物理的正確性: DeepSeek R1 の答えは物理的に正しく、確立された光学原理に従っていますが、Claude 3.5 の答えには根本的な誤解が含まれています。
- 論理的一貫性: DeepSeek R1 は説明全体で論理的一貫性を維持していますが、Claude 3.5 の応答には内部矛盾が含まれています。
- 問題解決: DeepSeek R1 は有効な解の範囲を提供することで問題を正しく解決しますが、Claude 3.5 は不可能な解決策を提案します。
- 科学的リテラシー: DeepSeek R1 は反射の法則を適切に理解していることを示しますが、Claude 3.5 は基本的な光学概念を混同しているように見えます。
タスク3:問題解決スキル
プロンプト: 「数独パズルを解くプログラムを書いてください。」
Deepseek R1 の結果
def find_empty(grid):
for row in range(9):
for col in range(9):
if grid[row][col] == 0:
return (row, col) # 空のセルの位置を返す
return None # 空のセルなし
def is_valid(grid, num, pos):
row, col = pos
# 行をチェック
for i in range(9):
if grid[row][i] == num and i != col:
return False
# 列をチェック
for i in range(9):
if grid[i][col] == num and i != row:
return False
# 3x3 サブグリッドをチェック
start_row = (row // 3) * 3
start_col = (col // 3) * 3
for i in range(start_row, start_row + 3):
for j in range(start_col, start_col + 3):
if grid[i][j] == num and (i, j) != pos:
return False
return True
def solve(grid):
empty = find_empty(grid)
if not empty:
return True # パズル解決
row, col = empty
for num in range(1, 10):
if is_valid(grid, num, (row, col)):
grid[row][col] = num # 数字を配置
if solve(grid):
return True # 続けて解決
grid[row][col] = 0 # 無効ならバックトラック
return False # バックトラックをトリガー
def print_grid(grid):
for row in grid:
print(row)
# 数独パズルの例(0は空のセルを表す)
grid = [
[5,3,0,0,7,0,0,0,0],
[6,0,0,1,9,5,0,0,0],
[0,9,8,0,0,0,0,6,0],
[8,0,0,0,6,0,0,0,3],
[4,0,0,8,0,3,0,0,1],
[7,0,0,0,2,0,0,0,6],
[0,6,0,0,0,0,2,8,0],
[0,0,0,4,1,9,0,0,5],
[0,0,0,0,8,0,0,7,9]
]
if solve(grid):
print("Solved Sudoku:")
print_grid(grid)
else:
print("No solution exists")
Claude 3.5 の結果
def print_board(board):
for i in range(9):
if i % 3 == 0 and i != 0:
print("- - - - - - - - - - - -")
for j in range(9):
if j % 3 == 0 and j != 0:
print("|", end=" ")
if j == 8:
print(board[i][j])
else:
print(str(board[i][j]) + " ", end="")
def find_empty(board):
for i in range(9):
for j in range(9):
if board[i][j] == 0:
return (i, j)
return None
def valid(board, num, pos):
# 行をチェック
for j in range(9):
if board[pos[0]][j] == num and pos[1] != j:
return False
# 列をチェック
for i in range(9):
if board[i][pos[1]] == num and pos[0] != i:
return False
# ボックスをチェック
box_x = pos[1] // 3
box_y = pos[0] // 3
for i in range(box_y * 3, box_y * 3 + 3):
for j in range(box_x * 3, box_x * 3 + 3):
if board[i][j] == num and (i, j) != pos:
return False
return True
def solve(board):
empty = find_empty(board)
if not empty:
return True
row, col = empty
for num in range(1, 10):
if valid(board, num, (row, col)):
board[row][col] = num
if solve(board):
return True
board[row][col] = 0
return False
# パズルの例(0は空のセルを表す)
board = [
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
]
print("Original Sudoku:")
print_board(board)
print("\
Solving...\
")
if solve(board):
print("Solved Sudoku:")
print_board(board)
else:
print("No solution exists")
レビュー:
- アルゴリズム実装: 両者とも同等で、数独解決アルゴリズムを正しく実装しています。
- コードの可読性: Claude 3.5 の生成コードはやや優れており、特にユーザーフレンドリーな表示機能があります。
- ユーザー体験: Claude 3.5 は処理段階に関するフィードバックを含む、より完全なユーザー体験を提供します。
- コードスタイル: 両者とも良好で一貫した Python コーディングスタイルを維持しています。
- 実用性: Claude 3.5 の生成コードは、より明確な出力形式のため、実用面でわずかに優位かもしれません。
API 経由で DeepSeek R1 にアクセスするには?
Novita AI は AI クラウドプラットフォームであり、シンプルな API を使用して AI モデルを簡単にデプロイできるとともに、構築とスケーリングのための手頃で信頼性の高い GPU クラウドを提供します。
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
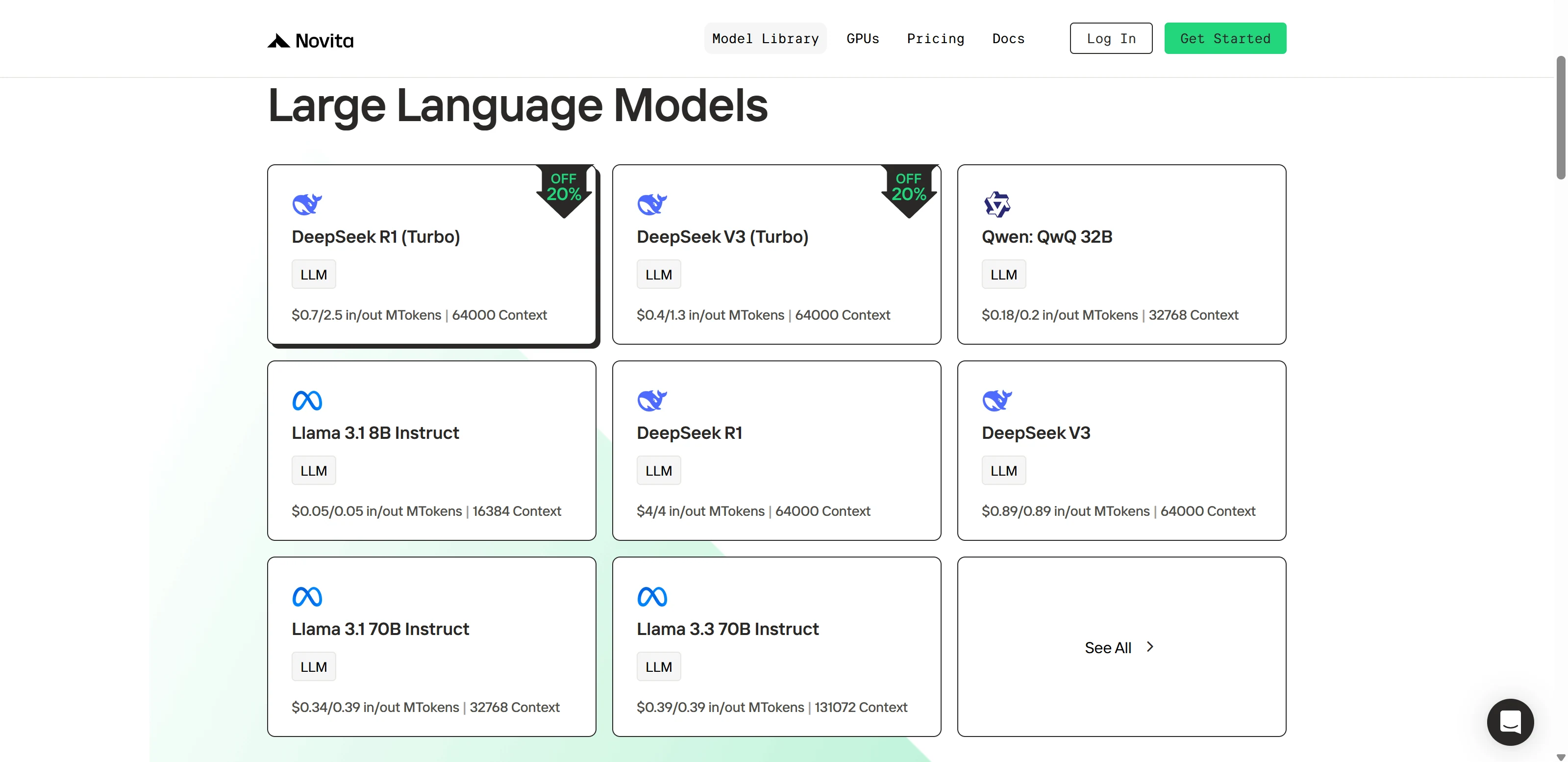
ステップ3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試してみましょう。
ステップ4:API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像のように API キーをコピーします。

ステップ5:API をインストール
プログラミング言語固有のパッケージマネージャーを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 と Claude 3.5 Sonnet はそれぞれ独自の強みを持っています。DeepSeek R1 は数学、コーディング、論理的問題解決に優れ、オープンソースモデルとしてコスト効率とカスタマイズ性を提供するため、開発者、研究者、予算重視の組織に最適です。
Claude 3.5 Sonnet は多言語タスク、コード生成、視覚的推論、大きなコンテキストウィンドウの処理で輝きます。API によるシームレスな統合により、研究、コンテンツ作成、高度なチャットボットに汎用性を発揮します。
選択は、コスト、ドメイン専門知識、使いやすさなどのタスク要件とユーザーの優先順位に依存します。
よくある質問
どのモデルがよりコスト効率が良いですか?
DeepSeek R1 は Claude 3.5 Sonnet よりも特に入力および出力トークンにおいて大幅に手頃です。一方、Novita AI は DeepSeek R1 の最適化バージョンである DeepSeek R1 Turbo を提供しており、スループットが3倍 、関数呼び出しを完全サポート、 期間限定60%割引です!
各モデルのコンテキストウィンドウサイズは?
DeepSeek R1 のコンテキストウィンドウは 128k トークン、Claude 3.5 Sonnet はより大きな 200k トークンのコンテキストウィンドウを提供します。
DeepSeek R1 はオープンソースですか?
はい、DeepSeek R1 は完全にオープンソースであり、ローカルホスティングとカスタマイズが可能です。
Novita AI は、AI の野心を強化するオールインワンのクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス—必要なコスト効率の高いツール。インフラを排除し、無料で始めて、AI のビジョンを現実にしましょう。



