

Aujourd’hui, après la sortie de FlashMLA, DeepSeek a lancé son deuxième projet OpenSourceWeek — DeepEP.
En tant que première bibliothèque de communication EP open-source spécialement conçue pour l’entraînement et l’inférence de modèles MoE (Mixture-of-Experts), DeepEP marque une avancée significative dans le domaine du parallélisme expert (EP). Son objectif est de fournir aux modèles MoE des capacités de communication à faible latence, à large bande passante et à haut débit, que ce soit entre GPUs au sein d’un nœud ou entre nœuds.
Selon les résultats des tests, DeepEP atteint des performances de bande passante quasi maximales pour la communication multi-GPU intra-nœud, tout en améliorant considérablement l’efficacité de la communication inter-nœuds.

Qu’est-ce que l’EP ?
Avant d’approfondir DeepEP, il est important de comprendre d’abord ce qu’est l’EP.
L’EP (Expert Parallelism) est une méthode de calcul distribué conçue spécifiquement pour les modèles MoE (Mixture-of-Experts), initialement publiée par DeepSeek. Les MoE sont une architecture de modèle basée sur Transformer qui utilise une stratégie d’activation creuse, ce qui les rend plus légers pendant l’entraînement par rapport aux modèles denses traditionnels. Dans un réseau neuronal MoE, seul un sous-ensemble des composants du modèle (appelés « experts ») est activé pour traiter l’entrée à un moment donné.
L’importance de l’EP (Expert Parallelism) dans l’accélération de l’inférence des grands modèles de langage réside dans sa capacité à partitionner efficacement les modèles MoE. Lorsqu’un modèle adopte l’architecture MoE avec des centaines d’experts (par exemple, 320 experts), l’EP peut affecter différents experts à des nœuds de calcul indépendants, avec une granularité parallèle qui correspond directement au nombre d’experts.
En revanche, le TP (Tensor Parallelism) repose sur la division du calcul selon le mécanisme multi-têtes dans les couches d’attention. Par exemple, dans une configuration typique à 32 têtes, le TP rencontre des difficultés pour passer à l’échelle sur 64 GPUs ou plus car la dimension de division est insuffisante (32 < 64), ce qui rend difficile l’utilisation complète des ressources matérielles. L’EP, quant à lui, partitionne les calculs le long de la dimension des experts.
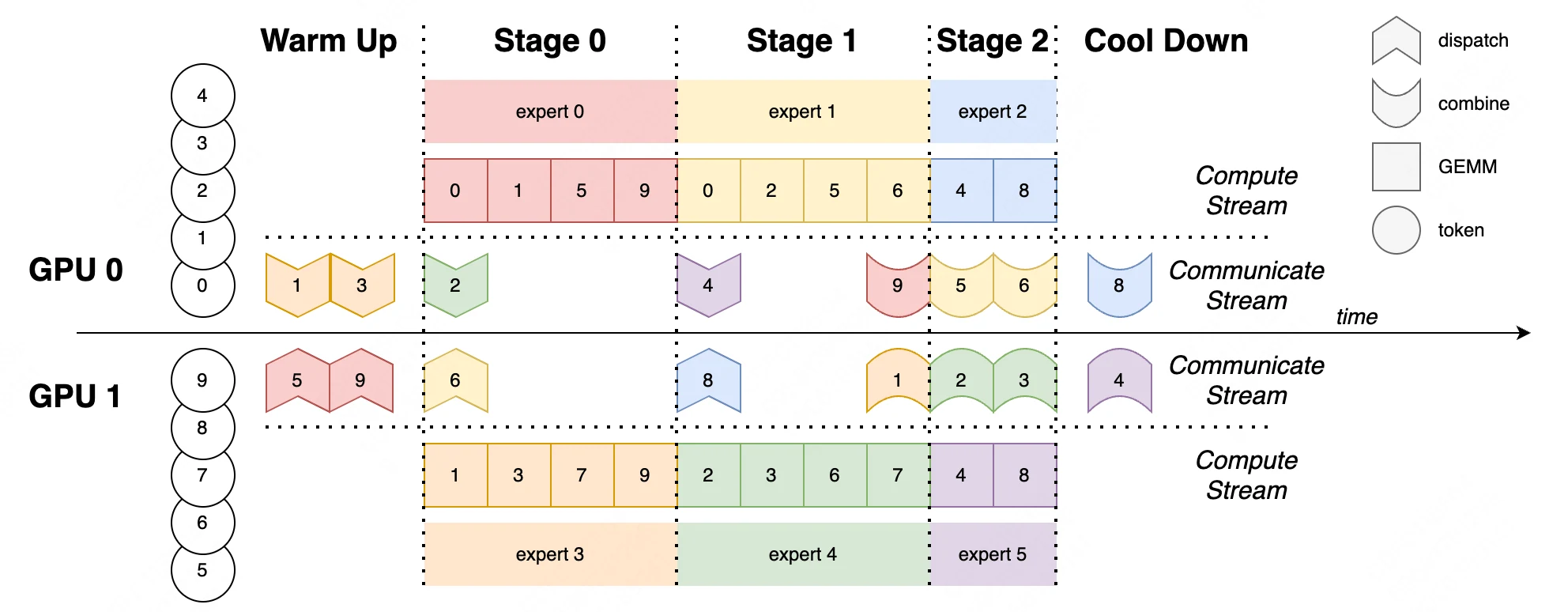
d’après EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
DP vs TP vs PP vs EP
| Méthode | Logique interne | Problème principal résolu |
|---|---|---|
| Parallélisme de données (DP) | Répliquer les modèles sur les périphériques, diviser les données d’entrée, synchroniser les mises à jour des gradients. | Vitesse d’entraînement lente due à la grande taille du jeu de données. |
| Parallélisme tensoriel (TP) | Diviser les matrices de paramètres sur les périphériques, effectuer le calcul distribué et agréger les résultats. | Paramètres d’une seule couche dépassant la capacité mémoire du périphérique. |
| Parallélisme pipeline (PP) | Partitionner les couches du modèle sur les périphériques, ordonnancer les micro-lots via le pipeline. | Mémoire insuffisante pour des modèles de profondeur extrême. |
| Parallélisme expert (EP) | Router dynamiquement les entrées vers des sous-réseaux experts avec activation creuse des paramètres. | Inefficacité mémoire et de calcul à l’échelle de billions de paramètres. |
Les grands modèles modernes (par exemple, GPT-4, DeepSeek-V3) intègrent généralement plusieurs stratégies de parallélisme simultanément pour maximiser l’efficacité :
- Parallélisme tensoriel (TP) : Divise les paramètres des couches individuelles sur les périphériques.
- Parallélisme pipeline (PP) : Distribue les différentes couches du modèle sur les périphériques pour les traiter en mode pipeline.
- Parallélisme de données (DP) : Synchronise l’entraînement sur plusieurs machines en répliquant le modèle et en divisant le jeu de données.
- Parallélisme expert (EP) : Étend les paramètres creux en distribuant les experts sur les périphériques pour les modèles MoE.
En combinant ces stratégies, les grands modèles peuvent utiliser efficacement les ressources matérielles disponibles, passer à l’échelle vers des tailles de modèle et des jeux de données plus grands tout en maintenant l’efficacité de l’entraînement et de l’inférence.
Qu’est-ce que DeepEP ?
DeepEP est une bibliothèque de communication conçue spécifiquement pour les modèles MoE (Mixture-of-Experts) et l’EP (Expert Parallelism), offrant les avantages fondamentaux suivants :
- 1. Communication All-to-All hautement optimisée
DeepEP fournit un noyau de communication All-to-All efficace qui réduit considérablement les goulots d’étranglement de transfert de données, assurant un échange d’informations plus fluide entre les experts dans des environnements distribués.
- 2. Prise en charge de NVLink et RDMA dans la communication intra-nœud et inter-nœuds
DeepEP prend en charge les technologies NVLink et RDMA, permettant une communication haute performance au sein des nœuds et entre les nœuds :
-
NVLink : Offre une bande passante allant jusqu’à 160 Go/s pour la communication intra-nœud.
-
RDMA : Permet des transferts de données inter-nœuds à faible latence, répondant aux exigences de l’entraînement distribué à grande échelle.
-
3. Noyau de calcul à haut débit
Pour les étapes d’entraînement et de préremplissage d’inférence, DeepEP fournit un noyau de calcul à haut débit, assurant un traitement efficace des données à grande échelle.
- 4. Noyau de calcul à faible latence
DeepEP offre un noyau de calcul à faible latence basé sur RDMA/Infiniband, ce qui minimise la latence d’inférence. Ceci est particulièrement bénéfique pour les applications sensibles à la latence pendant la phase de décodage de l’inférence.
- 5. Prise en charge native de la distribution de données FP8
DeepEP prend en charge nativement la distribution de données FP8, réduisant le volume de transfert de données tout en maintenant la précision, améliorant ainsi l’efficacité de la communication.
- 6. Contrôle flexible des ressources GPU
DeepEP dispose d’un mécanisme d’ordonnancement flexible des ressources GPU, permettant un chevauchement efficace du calcul et de la communication. Cela minimise le gaspillage de ressources et améliore les performances globales.
EP vs DeepEP
En substance, EP définit le « quoi » (comment diviser les experts et répartir les charges de travail), tandis que DeepEP fournit le « comment » (des mécanismes de communication efficaces pour rendre l’EP plus rapide et plus scalable).
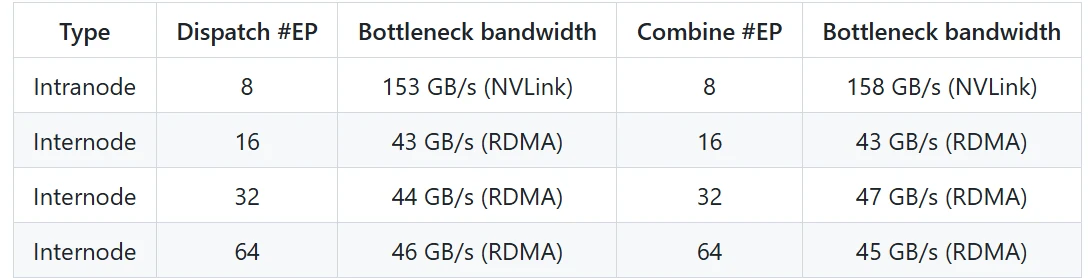
Performances de DeepEP
DeepEP démontre des performances exceptionnelles tant dans la communication intra-nœud qu’inter-nœuds, en particulier dans les architectures hybrides combinant NVLink et RDMA. Voici les résultats de performance dans deux scénarios typiques :
Performances du noyau standard (transmission NVLink et RDMA)
-
Environnement de test :
- GPU : H800 (NVLink avec une bande passante maximale d’environ 160 Go/s)
- Réseau : CX7 InfiniBand 400 Gb/s RDMA NIC (bande passante maximale d’environ 50 Go/s)
- Configuration : Configuration de pré-entraînement DeepSeek-V3/R1 (taille de lot : 4096 tokens, taille cachée : 7168, top-4 couches, top-8 experts, distribution FP8 et agrégation BF16)
-
Résultats de performance :
- La communication intra-nœud atteint une bande passante proche du maximum NVLink (160 Go/s), démontrant une efficacité de transfert de données extrêmement élevée.
- La communication inter-nœuds maintient une bande passante stable sous RDMA, répondant aux exigences de l’entraînement distribué à grande échelle.
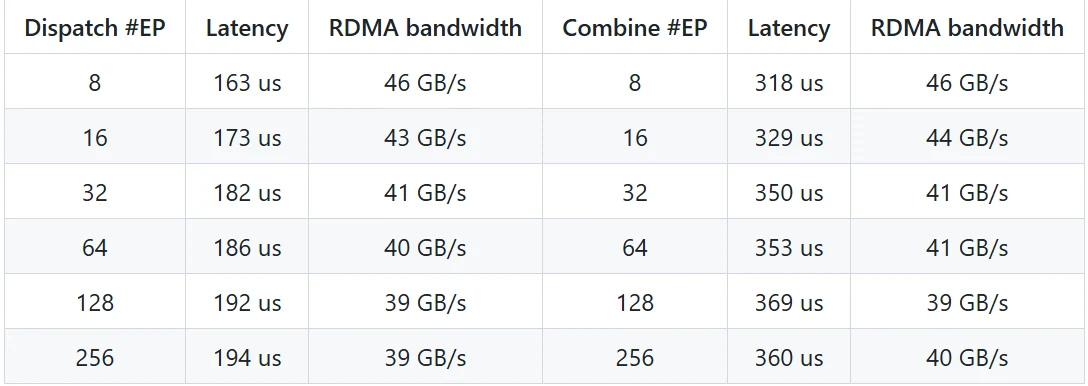
Performances du noyau à faible latence (RDMA pur)
-
Environnement de test :
- GPU : H800
- Réseau : CX7 InfiniBand 400 Gb/s RDMA NIC (bande passante maximale d’environ 50 Go/s)
- Configuration : Configuration de production typique DeepSeek-V3/R1 (taille de lot : 128 tokens, taille cachée : 7168, top-8 experts, distribution FP8 et agrégation BF16)
-
Résultats de performance :
- Le noyau à faible latence atteint une latence de l’ordre de la microseconde en mode RDMA pur, ce qui le rend adapté aux tâches de décodage d’inférence sensibles à la latence.
- Même avec un parallélisme élevé (#EP=256), la bande passante RDMA reste stable, garantissant un transfert de données efficace.
Scénarios d’application de DeepEP
DeepEP est bien adapté à divers scénarios d’entraînement et d’inférence de modèles MoE, en particulier dans l’entraînement distribué à grande échelle. Les principaux scénarios d’application incluent :
-
Entraînement de modèles MoE
- Le noyau de calcul à haut débit de DeepEP et son mécanisme de communication All-to-All efficace accélèrent considérablement le processus d’entraînement, en particulier dans les environnements multi-nœuds et multi-GPU.
-
Phase de préremplissage d’inférence
- Pendant la phase de préremplissage d’inférence, le noyau de calcul à haut débit de DeepEP traite efficacement de grandes quantités de données, assurant un pipeline d’inférence très efficace.
-
Phase de décodage d’inférence
- Pour la phase de décodage, le noyau de calcul à faible latence de DeepEP minimise les délais d’inférence, ce qui le rend idéal pour les applications en temps réel.
Conclusion
Selon les résultats d’évaluation, DeepGEMM a démontré des capacités d’optimisation de performance significatives sur plusieurs GPUs, notamment H100, H200 et H800, soulignant son excellente polyvalence.
Pour les modèles de la série MoE fonctionnant sur l’architecture Hopper (tels que DeepSeek V3 et R1), en intégrant les optimisations dans le module MoE du framework d’inférence et en remplaçant les GEMM groupés de la version CUTLASS d’origine par l’implémentation DeepGEMM, l’inférence du modèle devrait atteindre une accélération d’environ 1,2x, améliorant considérablement les performances globales.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via une API simple, tout en fournissant le cloud GPU fiable et abordable pour la construction et le passage à l’échelle.
Obtenez 20 $ de crédits et essayez DeepSeek dès maintenant !



